 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance uncertainty in medical image analysis: a large-scale investigation of confidence intervals
Jan 23, 2026Performance uncertainty quantification is essential for reliable validation and eventual clinical translation of medical imaging artificial intelligence (AI). Confidence intervals (CIs) play a central role in this process by indicating how precise a reported performance estimate is. Yet, due to the limited amount of work examining CI behavior in medical imaging, the community remains largely unaware of how many diverse CI methods exist and how they behave in specific settings. The purpose of this study is to close this gap. To this end, we conducted a large-scale empirical analysis across a total of 24 segmentation and classification tasks, using 19 trained models per task group, a broad spectrum of commonly used performance metrics, multiple aggregation strategies, and several widely adopted CI methods. Reliability (coverage) and precision (width) of each CI method were estimated across all settings to characterize their dependence on study characteristics. Our analysis revealed five principal findings: 1) the sample size required for reliable CIs varies from a few dozens to several thousands of cases depending on study parameters; 2) CI behavior is strongly affected by the choice of performance metric; 3) aggregation strategy substantially influences the reliability of CIs, e.g. they require more observations for macro than for micro; 4) the machine learning problem (segmentation versus classification) modulates these effects; 5) different CI methods are not equally reliable and precise depending on the use case. These results form key components for the development of future guidelines on reporting performance uncertainty in medical imaging AI.
False Promises in Medical Imaging AI? Assessing Validity of Outperformance Claims
May 07, 2025Performance comparisons are fundamental in medical imaging Artificial Intelligence (AI) research, often driving claims of superiority based on relative improvements in common performance metrics. However, such claims frequently rely solely on empirical mean performance. In this paper, we investigate whether newly proposed methods genuinely outperform the state of the art by analyzing a representative cohort of medical imaging papers. We quantify the probability of false claims based on a Bayesian approach that leverages reported results alongside empirically estimated model congruence to estimate whether the relative ranking of methods is likely to have occurred by chance. According to our results, the majority (>80%) of papers claims outperformance when introducing a new method. Our analysis further revealed a high probability (>5%) of false outperformance claims in 86% of classification papers and 53% of segmentation papers. These findings highlight a critical flaw in current benchmarking practices: claims of outperformance in medical imaging AI are frequently unsubstantiated, posing a risk of misdirecting future research efforts.
Confidence intervals uncovered: Are we ready for real-world medical imaging AI?
Sep 27, 2024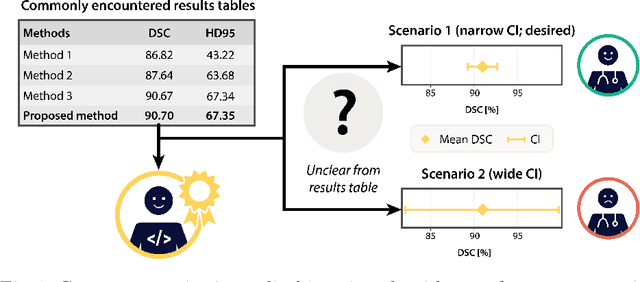
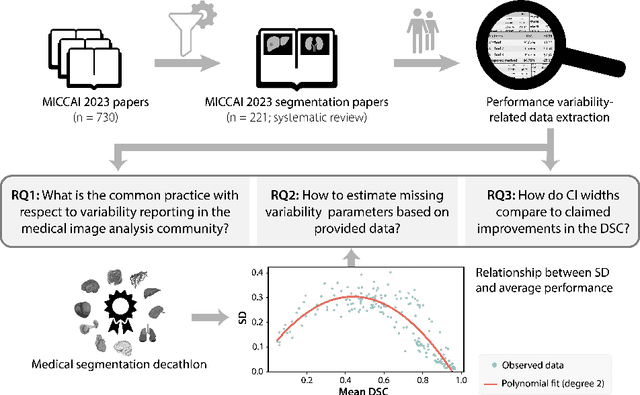
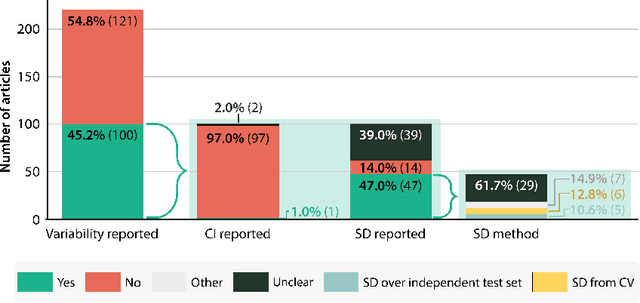

Medical imaging is spearheading the AI transformation of healthcare. Performance reporting is key to determine which methods should be translated into clinical practice. Frequently, broad conclusions are simply derived from mean performance values. In this paper, we argue that this common practice is often a misleading simplification as it ignores performance variability. Our contribution is threefold. (1) Analyzing all MICCAI segmentation papers (n = 221) published in 2023, we first observe that more than 50% of papers do not assess performance variability at all. Moreover, only one (0.5%) paper reported confidence intervals (CIs) for model performance. (2) To address the reporting bottleneck, we show that the unreported standard deviation (SD) in segmentation papers can be approximated by a second-order polynomial function of the mean Dice similarity coefficient (DSC). Based on external validation data from 56 previous MICCAI challenges, we demonstrate that this approximation can accurately reconstruct the CI of a method using information provided in publications. (3) Finally, we reconstructed 95% CIs around the mean DSC of MICCAI 2023 segmentation papers. The median CI width was 0.03 which is three times larger than the median performance gap between the first and second ranked method. For more than 60% of papers, the mean performance of the second-ranked method was within the CI of the first-ranked method. We conclude that current publications typically do not provide sufficient evidence to support which models could potentially be translated into clinical practice.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022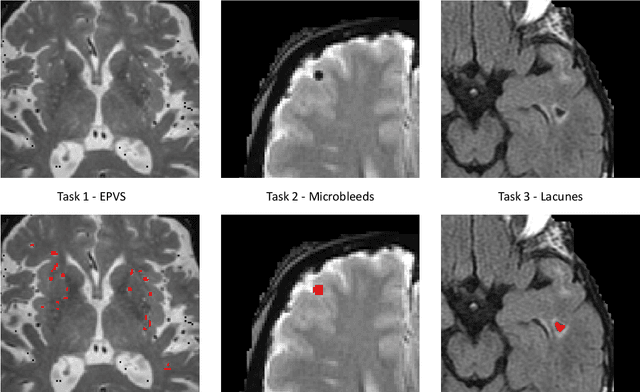
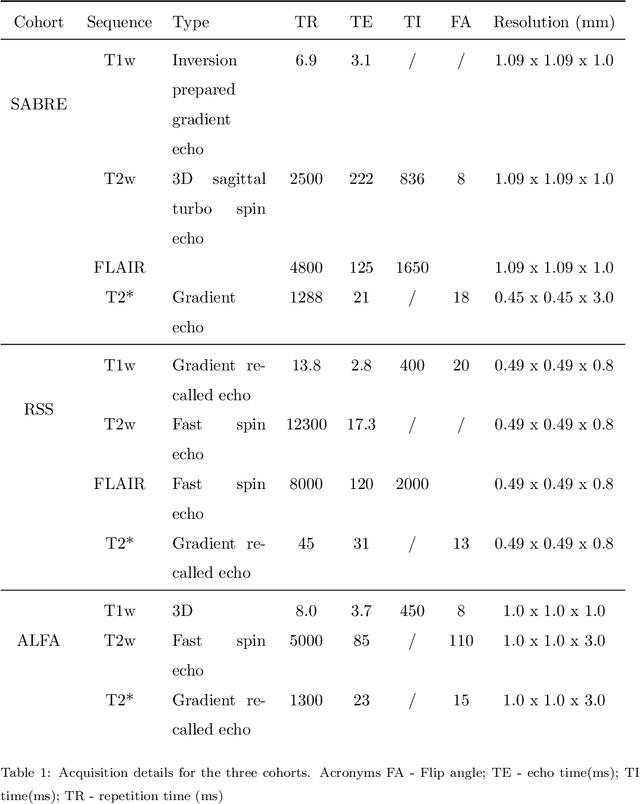
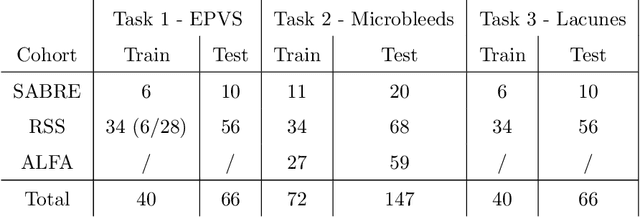
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022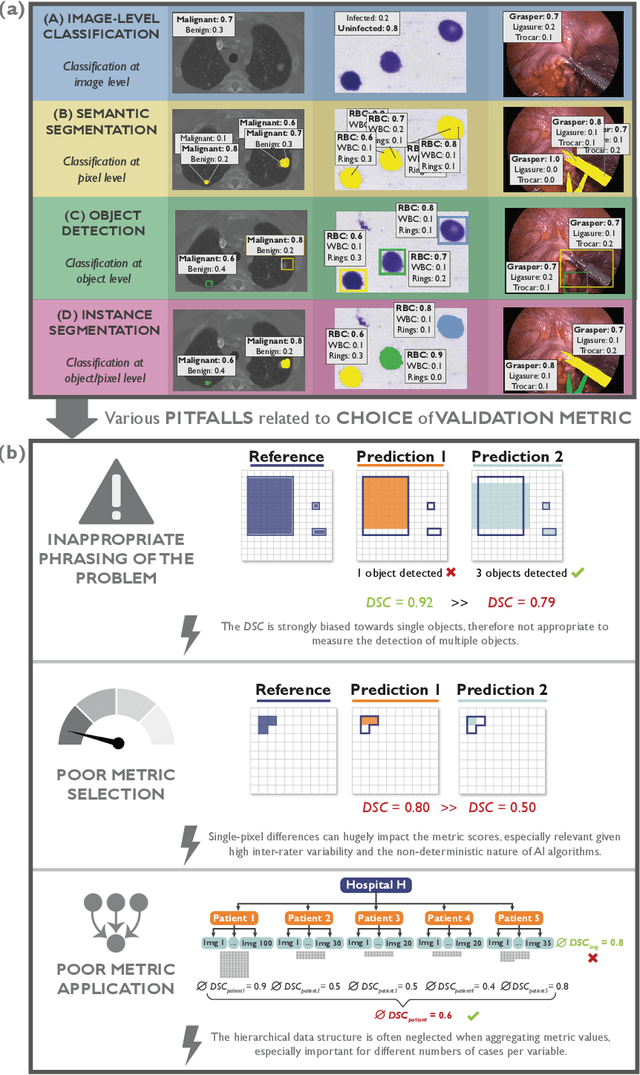
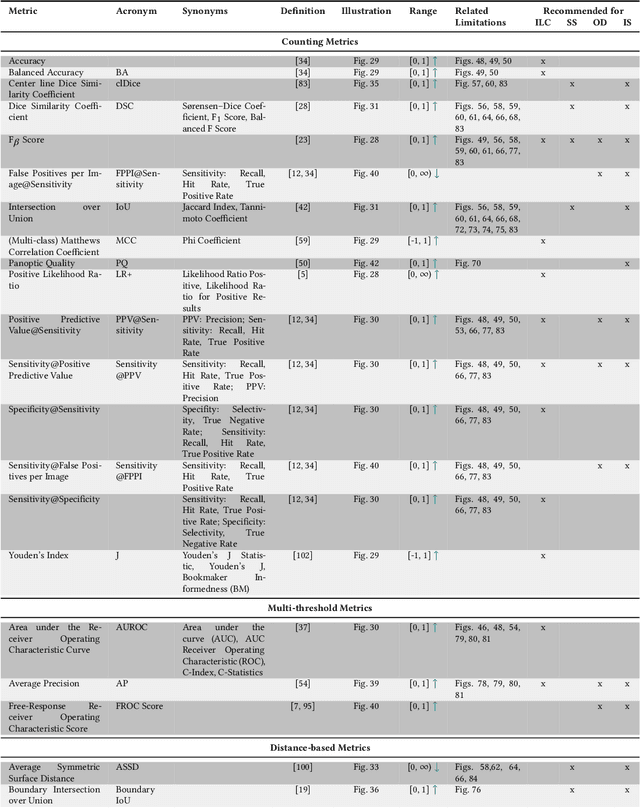
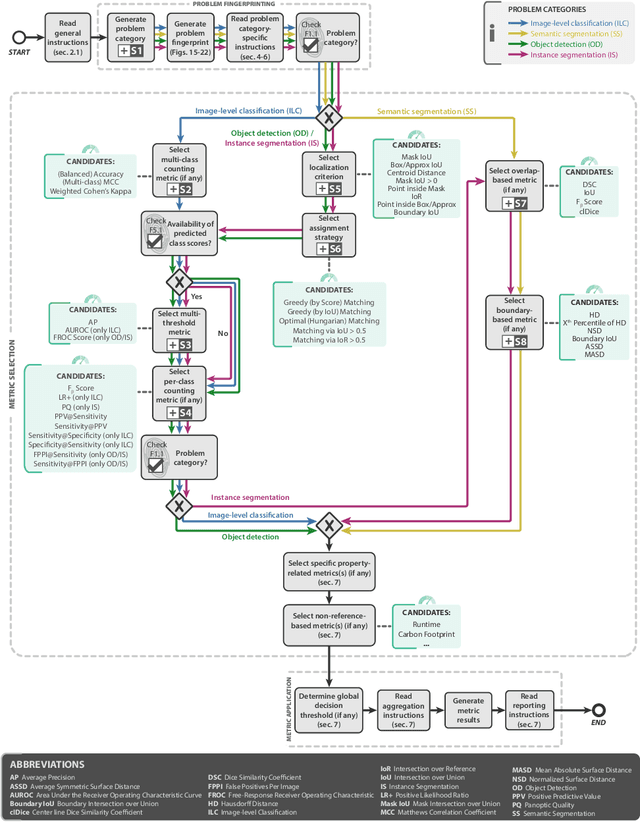
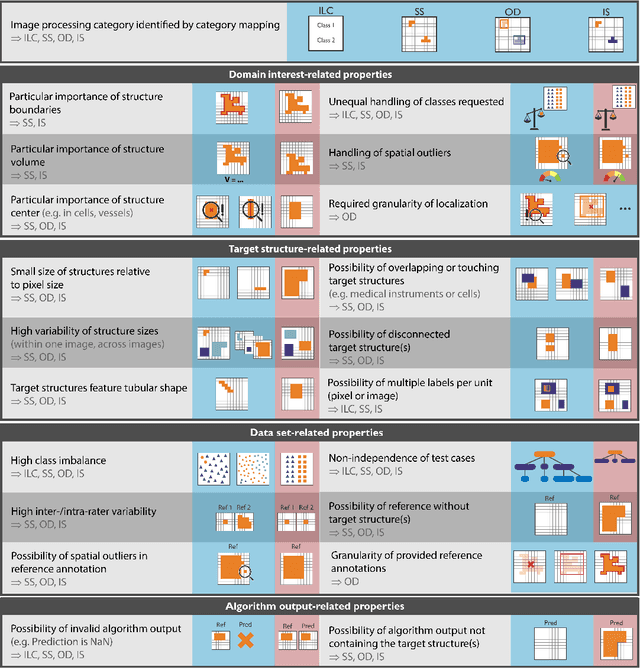
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
A Decoupled Uncertainty Model for MRI Segmentation Quality Estimation
Sep 06, 2021



Quality control (QC) of MR images is essential to ensure that downstream analyses such as segmentation can be performed successfully. Currently, QC is predominantly performed visually and subjectively, at significant time and operator cost. We aim to automate the process using a probabilistic network that estimates segmentation uncertainty through a heteroscedastic noise model, providing a measure of task-specific quality. By augmenting training images with k-space artefacts, we propose a novel CNN architecture to decouple sources of uncertainty related to the task and different k-space artefacts in a self-supervised manner. This enables the prediction of separate uncertainties for different types of data degradation. While the uncertainty predictions reflect the presence and severity of artefacts, the network provides more robust and generalisable segmentation predictions given the quality of the data. We show that models trained with artefact augmentation provide informative measures of uncertainty on both simulated artefacts and problematic real-world images identified by human raters, both qualitatively and quantitatively in the form of error bars on volume measurements. Relating artefact uncertainty to segmentation Dice scores, we observe that our uncertainty predictions provide a better estimate of MRI quality from the point of view of the task (gray matter segmentation) compared to commonly used metrics of quality including signal-to-noise ratio (SNR) and contrast-to-noise ratio (CNR), hence providing a real-time quality metric indicative of segmentation quality.
Distinguishing Healthy Ageing from Dementia: a Biomechanical Simulation of Brain Atrophy using Deep Networks
Aug 18, 2021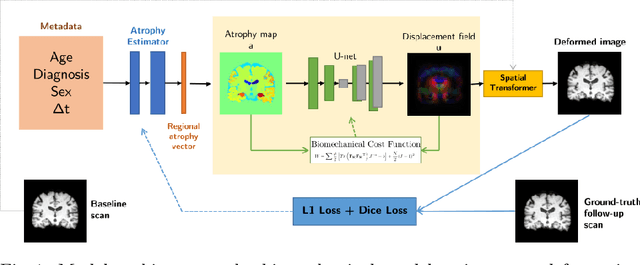


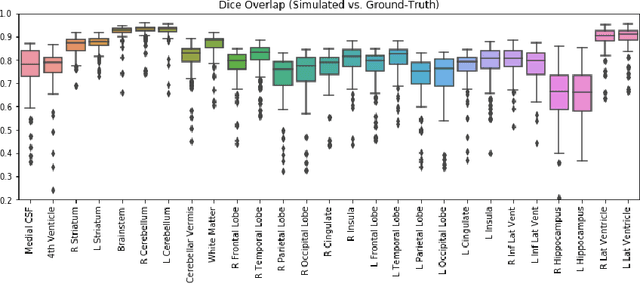
Biomechanical modeling of tissue deformation can be used to simulate different scenarios of longitudinal brain evolution. In this work,we present a deep learning framework for hyper-elastic strain modelling of brain atrophy, during healthy ageing and in Alzheimer's Disease. The framework directly models the effects of age, disease status, and scan interval to regress regional patterns of atrophy, from which a strain-based model estimates deformations. This model is trained and validated using 3D structural magnetic resonance imaging data from the ADNI cohort. Results show that the framework can estimate realistic deformations, following the known course of Alzheimer's disease, that clearly differentiate between healthy and demented patterns of ageing. This suggests the framework has potential to be incorporated into explainable models of disease, for the exploration of interventions and counterfactual examples.
Estimating MRI Image Quality via Image Reconstruction Uncertainty
Jun 21, 2021

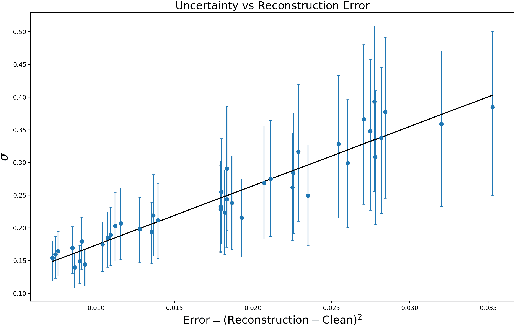
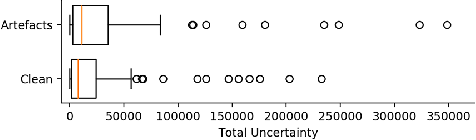
Quality control (QC) in medical image analysis is time-consuming and laborious, leading to increased interest in automated methods. However, what is deemed suitable quality for algorithmic processing may be different from human-perceived measures of visual quality. In this work, we pose MR image quality assessment from an image reconstruction perspective. We train Bayesian CNNs using a heteroscedastic uncertainty model to recover clean images from noisy data, providing measures of uncertainty over the predictions. This framework enables us to divide data corruption into learnable and non-learnable components and leads us to interpret the predictive uncertainty as an estimation of the achievable recovery of an image. Thus, we argue that quality control for visual assessment cannot be equated to quality control for algorithmic processing. We validate this statement in a multi-task experiment combining artefact recovery with uncertainty prediction and grey matter segmentation. Recognising this distinction between visual and algorithmic quality has the impact that, depending on the downstream task, less data can be excluded based on ``visual quality" reasons alone.