 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Semantic Diffusion Architectures for Model Training on Synthetic Echocardiograms
Sep 28, 2024We investigate the utility of diffusion generative models to efficiently synthesise datasets that effectively train deep learning models for image analysis. Specifically, we propose novel $\Gamma$-distribution Latent Denoising Diffusion Models (LDMs) designed to generate semantically guided synthetic cardiac ultrasound images with improved computational efficiency. We also investigate the potential of using these synthetic images as a replacement for real data in training deep networks for left-ventricular segmentation and binary echocardiogram view classification tasks. We compared six diffusion models in terms of the computational cost of generating synthetic 2D echo data, the visual realism of the resulting images, and the performance, on real data, of downstream tasks (segmentation and classification) trained using these synthetic echoes. We compare various diffusion strategies and ODE solvers for their impact on segmentation and classification performance. The results show that our propose architectures significantly reduce computational costs while maintaining or improving downstream task performance compared to state-of-the-art methods. While other diffusion models generated more realistic-looking echo images at higher computational cost, our research suggests that for model training, visual realism is not necessarily related to model performance, and considerable compute costs can be saved by using more efficient models.
Surface Masked AutoEncoder: Self-Supervision for Cortical Imaging Data
Aug 10, 2023Self-supervision has been widely explored as a means of addressing the lack of inductive biases in vision transformer architectures, which limits generalisation when networks are trained on small datasets. This is crucial in the context of cortical imaging, where phenotypes are complex and heterogeneous, but the available datasets are limited in size. This paper builds upon recent advancements in translating vision transformers to surface meshes and investigates the potential of Masked AutoEncoder (MAE) self-supervision for cortical surface learning. By reconstructing surface data from a masked version of the input, the proposed method effectively models cortical structure to learn strong representations that translate to improved performance in downstream tasks. We evaluate our approach on cortical phenotype regression using the developing Human Connectome Project (dHCP) and demonstrate that pre-training leads to a 26\% improvement in performance, with an 80\% faster convergence, compared to models trained from scratch. Furthermore, we establish that pre-training vision transformer models on large datasets, such as the UK Biobank (UKB), enables the acquisition of robust representations for finetuning in low-data scenarios. Our code and pre-trained models are publicly available at \url{https://github.com/metrics-lab/surface-vision-transformers}.
The Multiscale Surface Vision Transformer
Mar 21, 2023Surface meshes are a favoured domain for representing structural and functional information on the human cortex, but their complex topology and geometry pose significant challenges for deep learning analysis. While Transformers have excelled as domain-agnostic architectures for sequence-to-sequence learning, notably for structures where the translation of the convolution operation is non-trivial, the quadratic cost of the self-attention operation remains an obstacle for many dense prediction tasks. Inspired by some of the latest advances in hierarchical modelling with vision transformers, we introduce the Multiscale Surface Vision Transformer (MS-SiT) as a backbone architecture for surface deep learning. The self-attention mechanism is applied within local-mesh-windows to allow for high-resolution sampling of the underlying data, while a shifted-window strategy improves the sharing of information between windows. Neighbouring patches are successively merged, allowing the MS-SiT to learn hierarchical representations suitable for any prediction task. Results demonstrate that the MS-SiT outperforms existing surface deep learning methods for neonatal phenotyping prediction tasks using the Developing Human Connectome Project (dHCP) dataset. Furthermore, building the MS-SiT backbone into a U-shaped architecture for surface segmentation demonstrates competitive results on cortical parcellation using the UK Biobank (UKB) and manually-annotated MindBoggle datasets. Code and trained models are publicly available at https://github.com/metrics-lab/surface-vision-transformers .
ICAM-reg: Interpretable Classification and Regression with Feature Attribution for Mapping Neurological Phenotypes in Individual Scans
Mar 03, 2021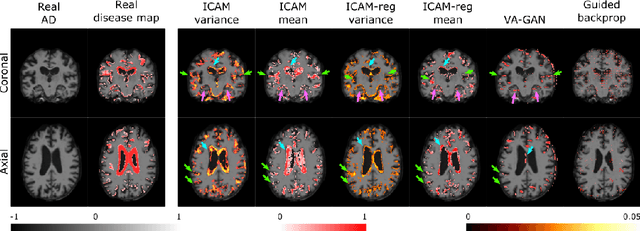

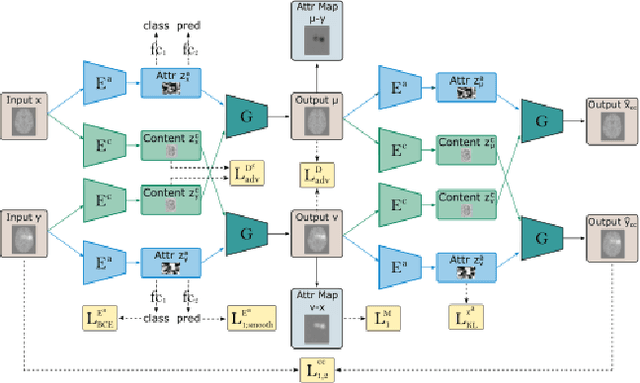
An important goal of medical imaging is to be able to precisely detect patterns of disease specific to individual scans; however, this is challenged in brain imaging by the degree of heterogeneity of shape and appearance. Traditional methods, based on image registration to a global template, historically fail to detect variable features of disease, as they utilise population-based analyses, suited primarily to studying group-average effects. In this paper we therefore take advantage of recent developments in generative deep learning to develop a method for simultaneous classification, or regression, and feature attribution (FA). Specifically, we explore the use of a VAE-GAN translation network called ICAM, to explicitly disentangle class relevant features from background confounds for improved interpretability and regression of neurological phenotypes. We validate our method on the tasks of Mini-Mental State Examination (MMSE) cognitive test score prediction for the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, as well as brain age prediction, for both neurodevelopment and neurodegeneration, using the developing Human Connectome Project (dHCP) and UK Biobank datasets. We show that the generated FA maps can be used to explain outlier predictions and demonstrate that the inclusion of a regression module improves the disentanglement of the latent space. Our code is freely available on Github https://github.com/CherBass/ICAM.
Biomechanical modelling of brain atrophy through deep learning
Dec 14, 2020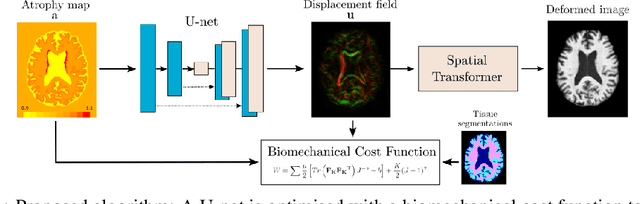
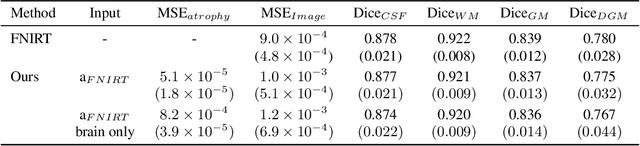

We present a proof-of-concept, deep learning (DL) based, differentiable biomechanical model of realistic brain deformations. Using prescribed maps of local atrophy and growth as input, the network learns to deform images according to a Neo-Hookean model of tissue deformation. The tool is validated using longitudinal brain atrophy data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, and we demonstrate that the trained model is capable of rapidly simulating new brain deformations with minimal residuals. This method has the potential to be used in data augmentation or for the exploration of different causal hypotheses reflecting brain growth and atrophy.
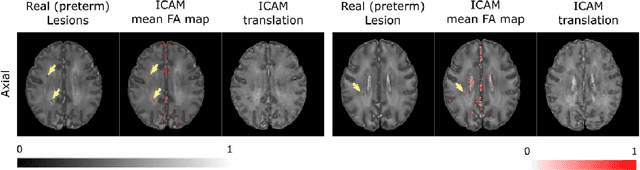
ICAM: Interpretable Classification via Disentangled Representations and Feature Attribution Mapping
Jun 16, 2020

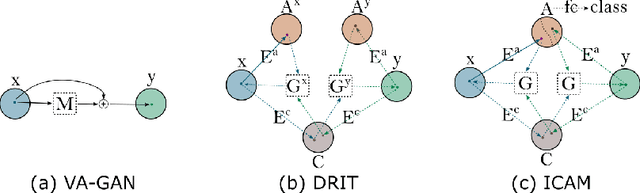
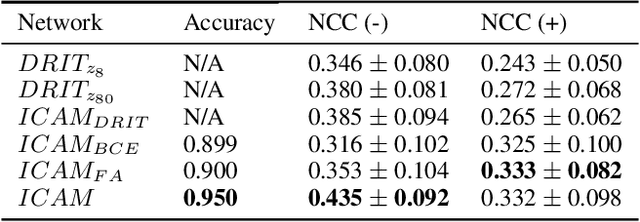
Feature attribution (FA), or the assignment of class-relevance to different locations in an image, is important for many classification problems but is particularly crucial within the neuroscience domain, where accurate mechanistic models of behaviours, or disease, require knowledge of all features discriminative of a trait. At the same time, predicting class relevance from brain images is challenging as phenotypes are typically heterogeneous, and changes occur against a background of significant natural variation. Here, we present a novel framework for creating class specific FA maps through image-to-image translation. We propose the use of a VAE-GAN to explicitly disentangle class relevance from background features for improved interpretability properties, which results in meaningful FA maps. We validate our method on 2D and 3D brain image datasets of dementia (ADNI dataset), ageing (UK Biobank), and (simulated) lesion detection. We show that FA maps generated by our method outperform baseline FA methods when validated against ground truth. More significantly, our approach is the first to use latent space sampling to support exploration of phenotype variation. Our code will be available online at https://github.com/CherBass/ICAM.