 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIM: Surface-based fMRI Analysis for Inter-Subject Multimodal Decoding from Movie-Watching Experiments
Jan 27, 2025



Current AI frameworks for brain decoding and encoding, typically train and test models within the same datasets. This limits their utility for brain computer interfaces (BCI) or neurofeedback, for which it would be useful to pool experiences across individuals to better simulate stimuli not sampled during training. A key obstacle to model generalisation is the degree of variability of inter-subject cortical organisation, which makes it difficult to align or compare cortical signals across participants. In this paper we address this through the use of surface vision transformers, which build a generalisable model of cortical functional dynamics, through encoding the topography of cortical networks and their interactions as a moving image across a surface. This is then combined with tri-modal self-supervised contrastive (CLIP) alignment of audio, video, and fMRI modalities to enable the retrieval of visual and auditory stimuli from patterns of cortical activity (and vice-versa). We validate our approach on 7T task-fMRI data from 174 healthy participants engaged in the movie-watching experiment from the Human Connectome Project (HCP). Results show that it is possible to detect which movie clips an individual is watching purely from their brain activity, even for individuals and movies not seen during training. Further analysis of attention maps reveals that our model captures individual patterns of brain activity that reflect semantic and visual systems. This opens the door to future personalised simulations of brain function. Code & pre-trained models will be made available at https://github.com/metrics-lab/sim, processed data for training will be available upon request at https://gin.g-node.org/Sdahan30/sim.
Cortical Surface Diffusion Generative Models
Feb 07, 2024Cortical surface analysis has gained increased prominence, given its potential implications for neurological and developmental disorders. Traditional vision diffusion models, while effective in generating natural images, present limitations in capturing intricate development patterns in neuroimaging due to limited datasets. This is particularly true for generating cortical surfaces where individual variability in cortical morphology is high, leading to an urgent need for better methods to model brain development and diverse variability inherent across different individuals. In this work, we proposed a novel diffusion model for the generation of cortical surface metrics, using modified surface vision transformers as the principal architecture. We validate our method in the developing Human Connectome Project (dHCP), the results suggest our model demonstrates superior performance in capturing the intricate details of evolving cortical surfaces. Furthermore, our model can generate high-quality realistic samples of cortical surfaces conditioned on postmenstrual age(PMA) at scan.
Surface Masked AutoEncoder: Self-Supervision for Cortical Imaging Data
Aug 10, 2023Self-supervision has been widely explored as a means of addressing the lack of inductive biases in vision transformer architectures, which limits generalisation when networks are trained on small datasets. This is crucial in the context of cortical imaging, where phenotypes are complex and heterogeneous, but the available datasets are limited in size. This paper builds upon recent advancements in translating vision transformers to surface meshes and investigates the potential of Masked AutoEncoder (MAE) self-supervision for cortical surface learning. By reconstructing surface data from a masked version of the input, the proposed method effectively models cortical structure to learn strong representations that translate to improved performance in downstream tasks. We evaluate our approach on cortical phenotype regression using the developing Human Connectome Project (dHCP) and demonstrate that pre-training leads to a 26\% improvement in performance, with an 80\% faster convergence, compared to models trained from scratch. Furthermore, we establish that pre-training vision transformer models on large datasets, such as the UK Biobank (UKB), enables the acquisition of robust representations for finetuning in low-data scenarios. Our code and pre-trained models are publicly available at \url{https://github.com/metrics-lab/surface-vision-transformers}.
The Multiscale Surface Vision Transformer
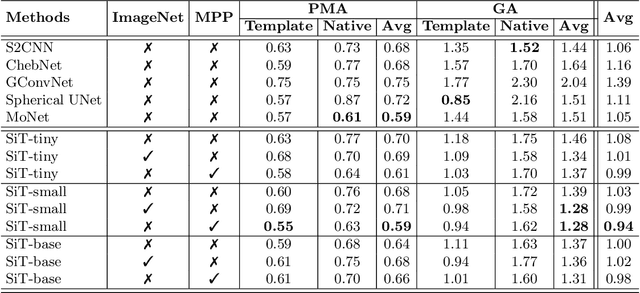
Mar 21, 2023Surface meshes are a favoured domain for representing structural and functional information on the human cortex, but their complex topology and geometry pose significant challenges for deep learning analysis. While Transformers have excelled as domain-agnostic architectures for sequence-to-sequence learning, notably for structures where the translation of the convolution operation is non-trivial, the quadratic cost of the self-attention operation remains an obstacle for many dense prediction tasks. Inspired by some of the latest advances in hierarchical modelling with vision transformers, we introduce the Multiscale Surface Vision Transformer (MS-SiT) as a backbone architecture for surface deep learning. The self-attention mechanism is applied within local-mesh-windows to allow for high-resolution sampling of the underlying data, while a shifted-window strategy improves the sharing of information between windows. Neighbouring patches are successively merged, allowing the MS-SiT to learn hierarchical representations suitable for any prediction task. Results demonstrate that the MS-SiT outperforms existing surface deep learning methods for neonatal phenotyping prediction tasks using the Developing Human Connectome Project (dHCP) dataset. Furthermore, building the MS-SiT backbone into a U-shaped architecture for surface segmentation demonstrates competitive results on cortical parcellation using the UK Biobank (UKB) and manually-annotated MindBoggle datasets. Code and trained models are publicly available at https://github.com/metrics-lab/surface-vision-transformers .
Surface Analysis with Vision Transformers
May 31, 2022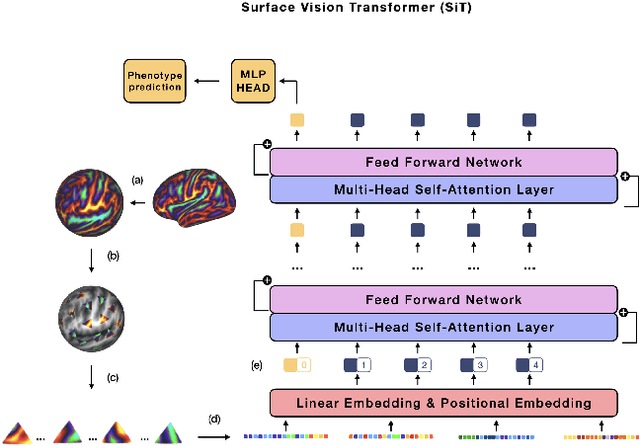

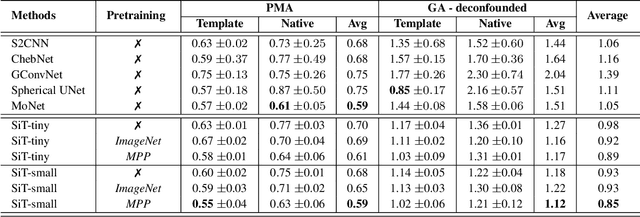
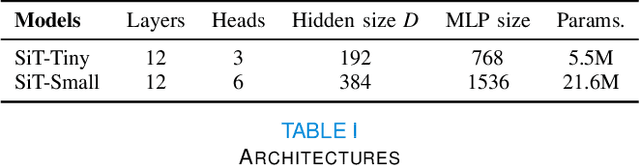
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Recent state-of-the-art performance of Vision Transformers (ViTs) demonstrates that a general-purpose architecture, which implements self-attention, could replace the local feature learning operations of CNNs. Motivated by the success of attention-modelling in computer vision, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence problem and propose a patching mechanism for surface meshes. We validate the performance of the proposed Surface Vision Transformer (SiT) on two brain age prediction tasks in the developing Human Connectome Project (dHCP) dataset and investigate the impact of pre-training on model performance. Experiments show that the SiT outperforms many surface CNNs, while indicating some evidence of general transformation invariance. Code available at https://github.com/metrics-lab/surface-vision-transformers
Surface Vision Transformers: Flexible Attention-Based Modelling of Biomedical Surfaces
Apr 07, 2022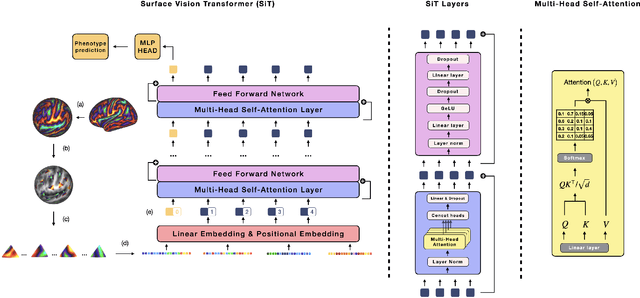
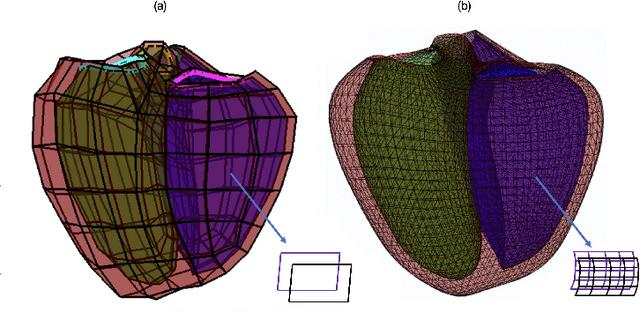
Recent state-of-the-art performances of Vision Transformers (ViT) in computer vision tasks demonstrate that a general-purpose architecture, which implements long-range self-attention, could replace the local feature learning operations of convolutional neural networks. In this paper, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence learning problem, by proposing patching mechanisms for general surface meshes. Sequences of patches are then processed by a transformer encoder and used for classification or regression. We validate our method on a range of different biomedical surface domains and tasks: brain age prediction in the developing Human Connectome Project (dHCP), fluid intelligence prediction in the Human Connectome Project (HCP), and coronary artery calcium score classification using surfaces from the Scottish Computed Tomography of the Heart (SCOT-HEART) dataset, and investigate the impact of pretraining and data augmentation on model performance. Results suggest that Surface Vision Transformers (SiT) demonstrate consistent improvement over geometric deep learning methods for brain age and fluid intelligence prediction and achieve comparable performance on calcium score classification to standard metrics used in clinical practice. Furthermore, analysis of transformer attention maps offers clear and individualised predictions of the features driving each task. Code is available on Github: https://github.com/metrics-lab/surface-vision-transformers
Surface Vision Transformers: Attention-Based Modelling applied to Cortical Analysis
Mar 30, 2022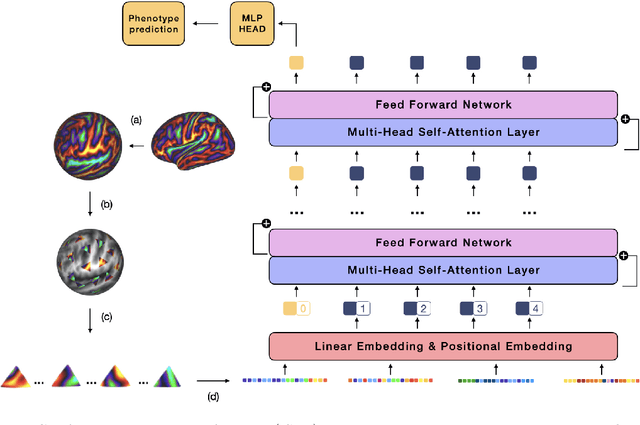


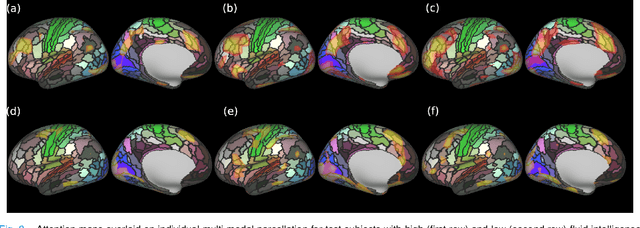
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Motivated by the success of attention-modelling in computer vision, we translate convolution-free vision transformer approaches to surface data, to introduce a domain-agnostic architecture to study any surface data projected onto a spherical manifold. Here, surface patching is achieved by representing spherical data as a sequence of triangular patches, extracted from a subdivided icosphere. A transformer model encodes the sequence of patches via successive multi-head self-attention layers while preserving the sequence resolution. We validate the performance of the proposed Surface Vision Transformer (SiT) on the task of phenotype regression from cortical surface metrics derived from the Developing Human Connectome Project (dHCP). Experiments show that the SiT generally outperforms surface CNNs, while performing comparably on registered and unregistered data. Analysis of transformer attention maps offers strong potential to characterise subtle cognitive developmental patterns.
Improving Phenotype Prediction using Long-Range Spatio-Temporal Dynamics of Functional Connectivity
Sep 07, 2021

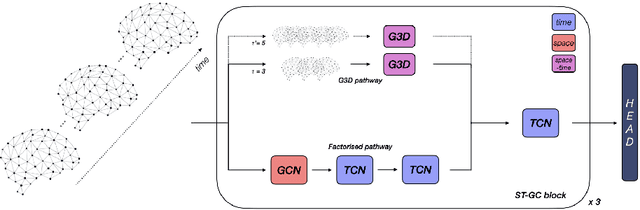
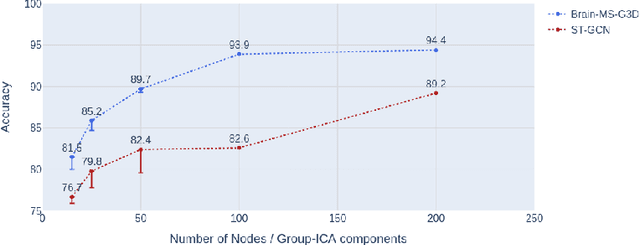
The study of functional brain connectivity (FC) is important for understanding the underlying mechanisms of many psychiatric disorders. Many recent analyses adopt graph convolutional networks, to study non-linear interactions between functionally-correlated states. However, although patterns of brain activation are known to be hierarchically organised in both space and time, many methods have failed to extract powerful spatio-temporal features. To overcome those challenges, and improve understanding of long-range functional dynamics, we translate an approach, from the domain of skeleton-based action recognition, designed to model interactions across space and time. We evaluate this approach using the Human Connectome Project (HCP) dataset on sex classification and fluid intelligence prediction. To account for subject topographic variability of functional organisation, we modelled functional connectomes using multi-resolution dual-regressed (subject-specific) ICA nodes. Results show a prediction accuracy of 94.4% for sex classification (an increase of 6.2% compared to other methods), and an improvement of correlation with fluid intelligence of 0.325 vs 0.144, relative to a baseline model that encodes space and time separately. Results suggest that explicit encoding of spatio-temporal dynamics of brain functional activity may improve the precision with which behavioural and cognitive phenotypes may be predicted in the future.