 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Analysis with Vision Transformers
Paper and Code
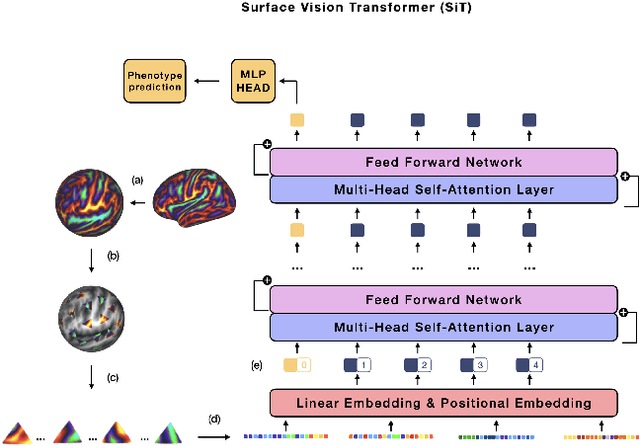

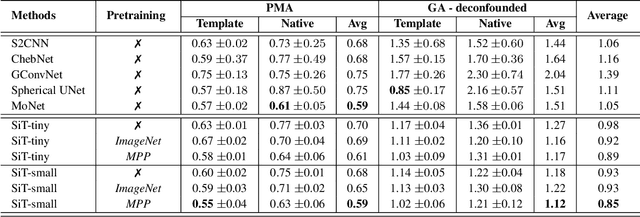
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Recent state-of-the-art performance of Vision Transformers (ViTs) demonstrates that a general-purpose architecture, which implements self-attention, could replace the local feature learning operations of CNNs. Motivated by the success of attention-modelling in computer vision, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence problem and propose a patching mechanism for surface meshes. We validate the performance of the proposed Surface Vision Transformer (SiT) on two brain age prediction tasks in the developing Human Connectome Project (dHCP) dataset and investigate the impact of pre-training on model performance. Experiments show that the SiT outperforms many surface CNNs, while indicating some evidence of general transformation invariance. Code available at https://github.com/metrics-lab/surface-vision-transformers