 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Surface Registration with Geometric Deep Learning
Nov 21, 2023



This paper introduces GeoMorph, a novel geometric deep-learning framework designed for image registration of cortical surfaces. The registration process consists of two main steps. First, independent feature extraction is performed on each input surface using graph convolutions, generating low-dimensional feature representations that capture important cortical surface characteristics. Subsequently, features are registered in a deep-discrete manner to optimize the overlap of common structures across surfaces by learning displacements of a set of control points. To ensure smooth and biologically plausible deformations, we implement regularization through a deep conditional random field implemented with a recurrent neural network. Experimental results demonstrate that GeoMorph surpasses existing deep-learning methods by achieving improved alignment with smoother deformations. Furthermore, GeoMorph exhibits competitive performance compared to classical frameworks. Such versatility and robustness suggest strong potential for various neuroscience applications.
Robust and Generalisable Segmentation of Subtle Epilepsy-causing Lesions: a Graph Convolutional Approach
Jun 05, 2023



Focal cortical dysplasia (FCD) is a leading cause of drug-resistant focal epilepsy, which can be cured by surgery. These lesions are extremely subtle and often missed even by expert neuroradiologists. "Ground truth" manual lesion masks are therefore expensive, limited and have large inter-rater variability. Existing FCD detection methods are limited by high numbers of false positive predictions, primarily due to vertex- or patch-based approaches that lack whole-brain context. Here, we propose to approach the problem as semantic segmentation using graph convolutional networks (GCN), which allows our model to learn spatial relationships between brain regions. To address the specific challenges of FCD identification, our proposed model includes an auxiliary loss to predict distance from the lesion to reduce false positives and a weak supervision classification loss to facilitate learning from uncertain lesion masks. On a multi-centre dataset of 1015 participants with surface-based features and manual lesion masks from structural MRI data, the proposed GCN achieved an AUC of 0.74, a significant improvement against a previously used vertex-wise multi-layer perceptron (MLP) classifier (AUC 0.64). With sensitivity thresholded at 67%, the GCN had a specificity of 71% in comparison to 49% when using the MLP. This improvement in specificity is vital for clinical integration of lesion-detection tools into the radiological workflow, through increasing clinical confidence in the use of AI radiological adjuncts and reducing the number of areas requiring expert review.
The Multiscale Surface Vision Transformer
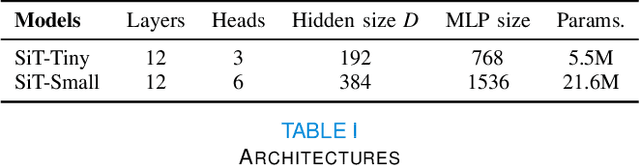
Mar 21, 2023Surface meshes are a favoured domain for representing structural and functional information on the human cortex, but their complex topology and geometry pose significant challenges for deep learning analysis. While Transformers have excelled as domain-agnostic architectures for sequence-to-sequence learning, notably for structures where the translation of the convolution operation is non-trivial, the quadratic cost of the self-attention operation remains an obstacle for many dense prediction tasks. Inspired by some of the latest advances in hierarchical modelling with vision transformers, we introduce the Multiscale Surface Vision Transformer (MS-SiT) as a backbone architecture for surface deep learning. The self-attention mechanism is applied within local-mesh-windows to allow for high-resolution sampling of the underlying data, while a shifted-window strategy improves the sharing of information between windows. Neighbouring patches are successively merged, allowing the MS-SiT to learn hierarchical representations suitable for any prediction task. Results demonstrate that the MS-SiT outperforms existing surface deep learning methods for neonatal phenotyping prediction tasks using the Developing Human Connectome Project (dHCP) dataset. Furthermore, building the MS-SiT backbone into a U-shaped architecture for surface segmentation demonstrates competitive results on cortical parcellation using the UK Biobank (UKB) and manually-annotated MindBoggle datasets. Code and trained models are publicly available at https://github.com/metrics-lab/surface-vision-transformers .
A Deep Generative Model of Neonatal Cortical Surface Development
Jun 22, 2022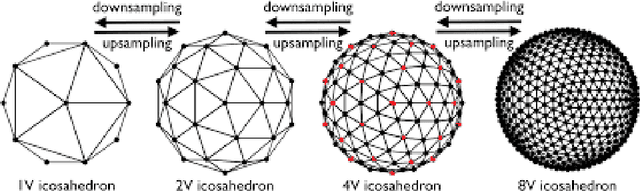
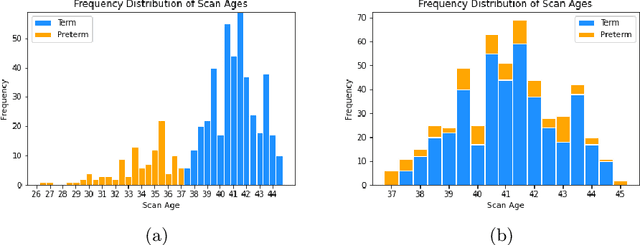
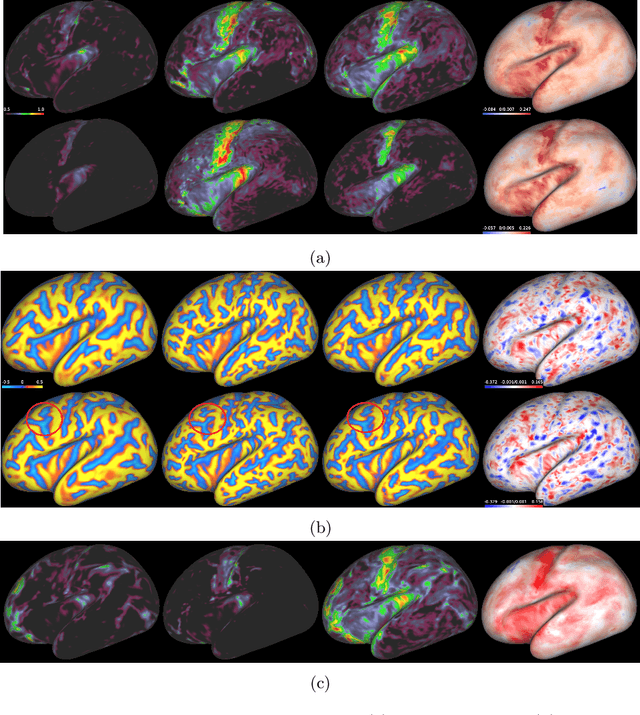
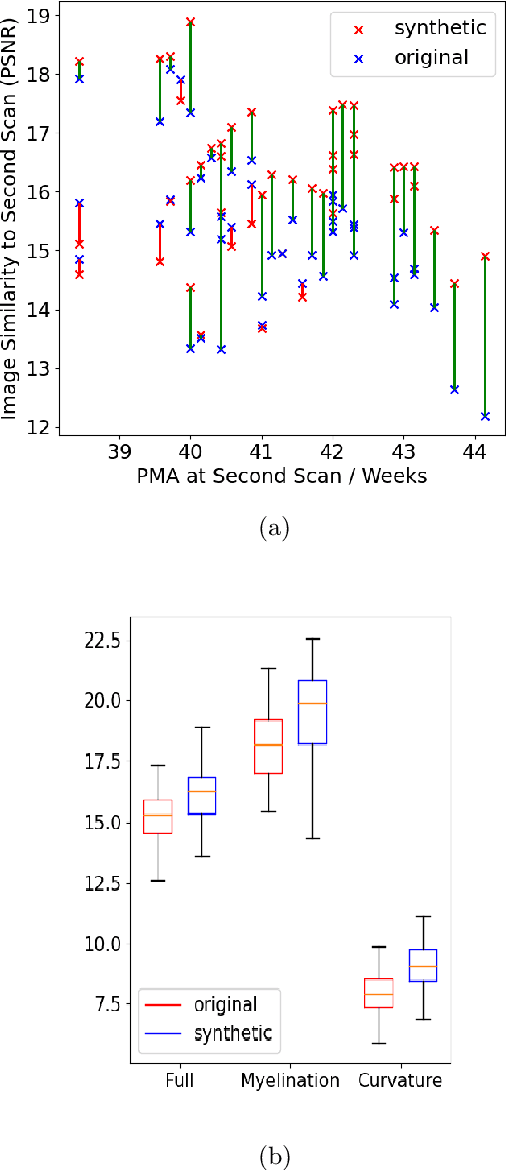
The neonatal cortical surface is known to be affected by preterm birth, and the subsequent changes to cortical organisation have been associated with poorer neurodevelopmental outcomes. Deep Generative models have the potential to lead to clinically interpretable models of disease, but developing these on the cortical surface is challenging since established techniques for learning convolutional filters are inappropriate on non-flat topologies. To close this gap, we implement a surface-based CycleGAN using mixture model CNNs (MoNet) to translate sphericalised neonatal cortical surface features (curvature and T1w/T2w cortical myelin) between different stages of cortical maturity. Results show our method is able to reliably predict changes in individual patterns of cortical organisation at later stages of gestation, validated by comparison to longitudinal data; and translate appearance between preterm and term gestation (> 37 weeks gestation), validated through comparison with a trained term/preterm classifier. Simulated differences in cortical maturation are consistent with observations in the literature.
Surface Analysis with Vision Transformers
May 31, 2022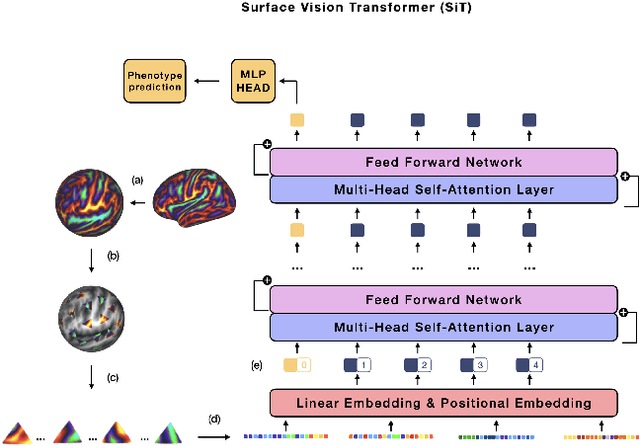

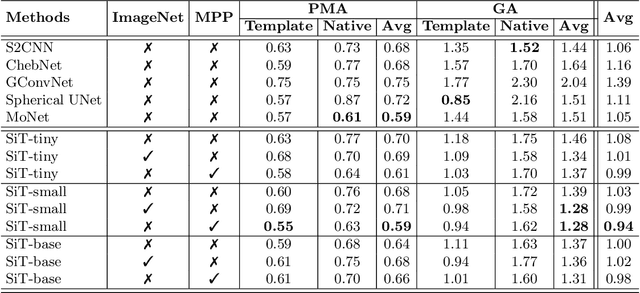
The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Recent state-of-the-art performance of Vision Transformers (ViTs) demonstrates that a general-purpose architecture, which implements self-attention, could replace the local feature learning operations of CNNs. Motivated by the success of attention-modelling in computer vision, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence problem and propose a patching mechanism for surface meshes. We validate the performance of the proposed Surface Vision Transformer (SiT) on two brain age prediction tasks in the developing Human Connectome Project (dHCP) dataset and investigate the impact of pre-training on model performance. Experiments show that the SiT outperforms many surface CNNs, while indicating some evidence of general transformation invariance. Code available at https://github.com/metrics-lab/surface-vision-transformers
Surface Vision Transformers: Flexible Attention-Based Modelling of Biomedical Surfaces
Apr 07, 2022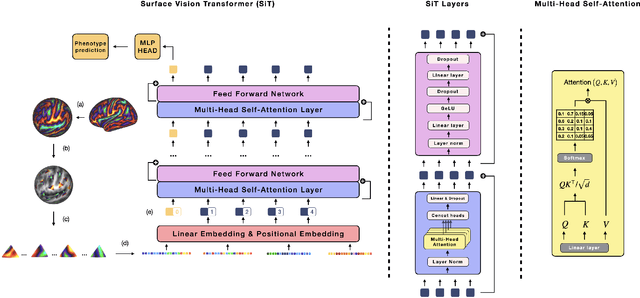
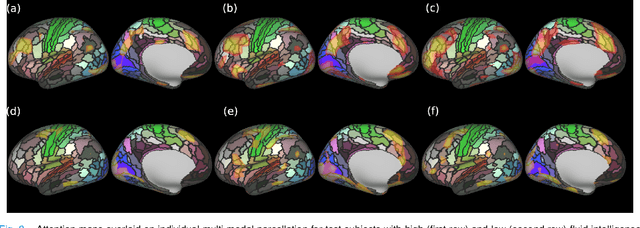
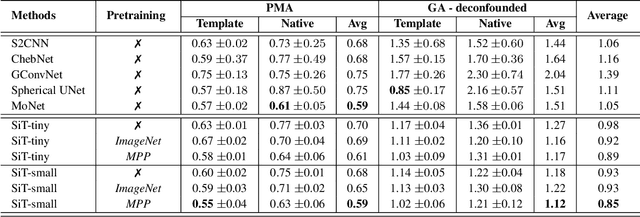
Recent state-of-the-art performances of Vision Transformers (ViT) in computer vision tasks demonstrate that a general-purpose architecture, which implements long-range self-attention, could replace the local feature learning operations of convolutional neural networks. In this paper, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence learning problem, by proposing patching mechanisms for general surface meshes. Sequences of patches are then processed by a transformer encoder and used for classification or regression. We validate our method on a range of different biomedical surface domains and tasks: brain age prediction in the developing Human Connectome Project (dHCP), fluid intelligence prediction in the Human Connectome Project (HCP), and coronary artery calcium score classification using surfaces from the Scottish Computed Tomography of the Heart (SCOT-HEART) dataset, and investigate the impact of pretraining and data augmentation on model performance. Results suggest that Surface Vision Transformers (SiT) demonstrate consistent improvement over geometric deep learning methods for brain age and fluid intelligence prediction and achieve comparable performance on calcium score classification to standard metrics used in clinical practice. Furthermore, analysis of transformer attention maps offers clear and individualised predictions of the features driving each task. Code is available on Github: https://github.com/metrics-lab/surface-vision-transformers
Surface Vision Transformers: Attention-Based Modelling applied to Cortical Analysis
Mar 30, 2022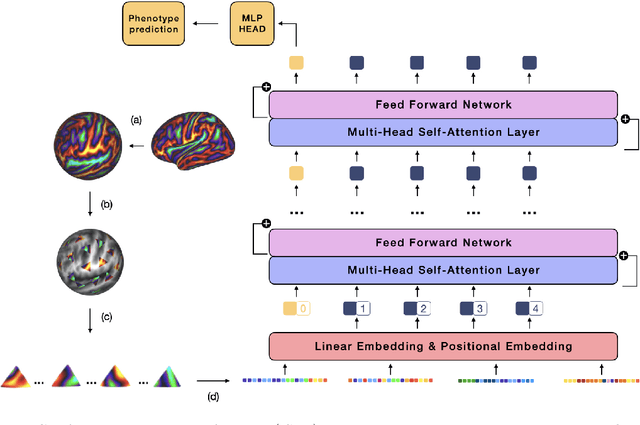


The extension of convolutional neural networks (CNNs) to non-Euclidean geometries has led to multiple frameworks for studying manifolds. Many of those methods have shown design limitations resulting in poor modelling of long-range associations, as the generalisation of convolutions to irregular surfaces is non-trivial. Motivated by the success of attention-modelling in computer vision, we translate convolution-free vision transformer approaches to surface data, to introduce a domain-agnostic architecture to study any surface data projected onto a spherical manifold. Here, surface patching is achieved by representing spherical data as a sequence of triangular patches, extracted from a subdivided icosphere. A transformer model encodes the sequence of patches via successive multi-head self-attention layers while preserving the sequence resolution. We validate the performance of the proposed Surface Vision Transformer (SiT) on the task of phenotype regression from cortical surface metrics derived from the Developing Human Connectome Project (dHCP). Experiments show that the SiT generally outperforms surface CNNs, while performing comparably on registered and unregistered data. Analysis of transformer attention maps offers strong potential to characterise subtle cognitive developmental patterns.
A Deep-Discrete Learning Framework for Spherical Surface Registration
Mar 24, 2022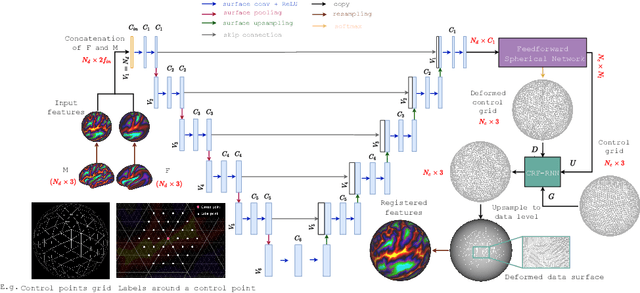
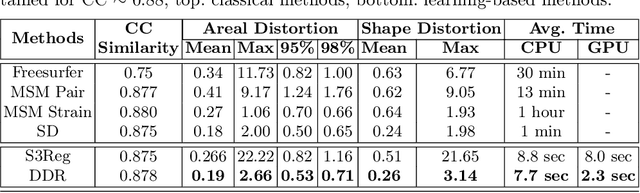
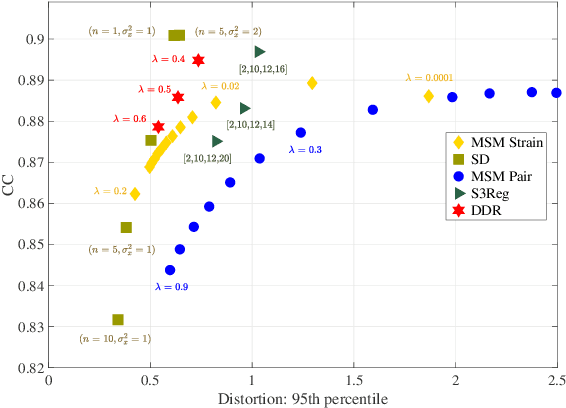
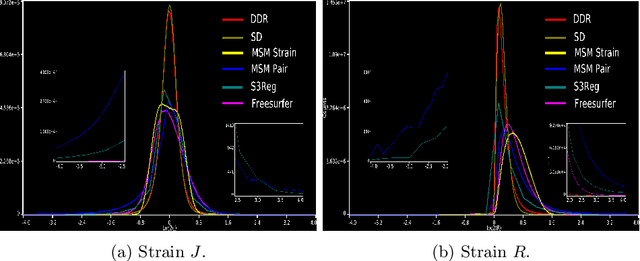
Cortical surface registration is a fundamental tool for neuroimaging analysis that has been shown to improve the alignment of functional regions relative to volumetric approaches. Classically, image registration is performed by optimizing a complex objective similarity function, leading to long run times. This contributes to a convention for aligning all data to a global average reference frame that poorly reflects the underlying cortical heterogeneity. In this paper, we propose a novel unsupervised learning-based framework that converts registration to a multi-label classification problem, where each point in a low-resolution control grid deforms to one of fixed, finite number of endpoints. This is learned using a spherical geometric deep learning architecture, in an end-to-end unsupervised way, with regularization imposed using a deep Conditional Random Field (CRF). Experiments show that our proposed framework performs competitively, in terms of similarity and areal distortion, relative to the most popular classical surface registration algorithms and generates smoother deformations than other learning-based surface registration methods, even in subjects with atypical cortical morphology.