 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Vision Transformers: Flexible Attention-Based Modelling of Biomedical Surfaces
Paper and Code
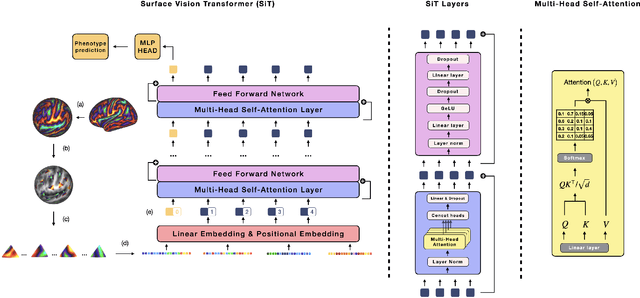
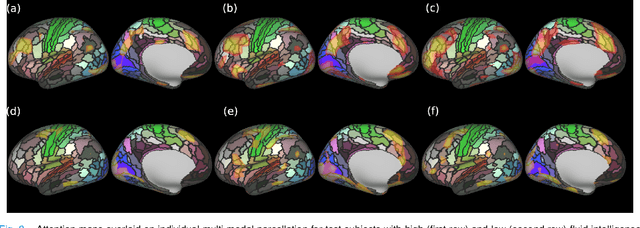
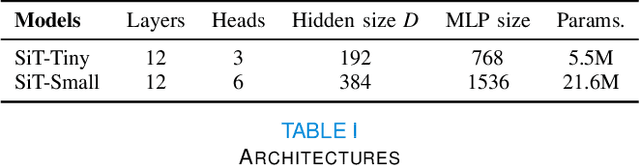
Recent state-of-the-art performances of Vision Transformers (ViT) in computer vision tasks demonstrate that a general-purpose architecture, which implements long-range self-attention, could replace the local feature learning operations of convolutional neural networks. In this paper, we extend ViTs to surfaces by reformulating the task of surface learning as a sequence-to-sequence learning problem, by proposing patching mechanisms for general surface meshes. Sequences of patches are then processed by a transformer encoder and used for classification or regression. We validate our method on a range of different biomedical surface domains and tasks: brain age prediction in the developing Human Connectome Project (dHCP), fluid intelligence prediction in the Human Connectome Project (HCP), and coronary artery calcium score classification using surfaces from the Scottish Computed Tomography of the Heart (SCOT-HEART) dataset, and investigate the impact of pretraining and data augmentation on model performance. Results suggest that Surface Vision Transformers (SiT) demonstrate consistent improvement over geometric deep learning methods for brain age and fluid intelligence prediction and achieve comparable performance on calcium score classification to standard metrics used in clinical practice. Furthermore, analysis of transformer attention maps offers clear and individualised predictions of the features driving each task. Code is available on Github: https://github.com/metrics-lab/surface-vision-transformers