 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIM: Surface-based fMRI Analysis for Inter-Subject Multimodal Decoding from Movie-Watching Experiments
Jan 27, 2025



Current AI frameworks for brain decoding and encoding, typically train and test models within the same datasets. This limits their utility for brain computer interfaces (BCI) or neurofeedback, for which it would be useful to pool experiences across individuals to better simulate stimuli not sampled during training. A key obstacle to model generalisation is the degree of variability of inter-subject cortical organisation, which makes it difficult to align or compare cortical signals across participants. In this paper we address this through the use of surface vision transformers, which build a generalisable model of cortical functional dynamics, through encoding the topography of cortical networks and their interactions as a moving image across a surface. This is then combined with tri-modal self-supervised contrastive (CLIP) alignment of audio, video, and fMRI modalities to enable the retrieval of visual and auditory stimuli from patterns of cortical activity (and vice-versa). We validate our approach on 7T task-fMRI data from 174 healthy participants engaged in the movie-watching experiment from the Human Connectome Project (HCP). Results show that it is possible to detect which movie clips an individual is watching purely from their brain activity, even for individuals and movies not seen during training. Further analysis of attention maps reveals that our model captures individual patterns of brain activity that reflect semantic and visual systems. This opens the door to future personalised simulations of brain function. Code & pre-trained models will be made available at https://github.com/metrics-lab/sim, processed data for training will be available upon request at https://gin.g-node.org/Sdahan30/sim.
RecFusion: A Binomial Diffusion Process for 1D Data for Recommendation
Jun 19, 2023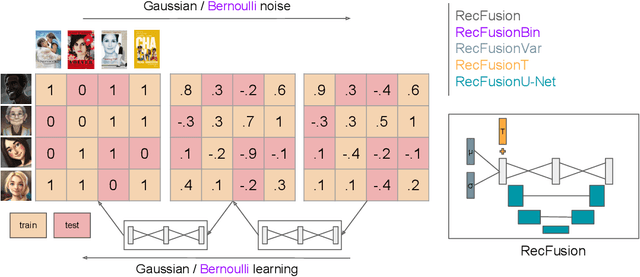
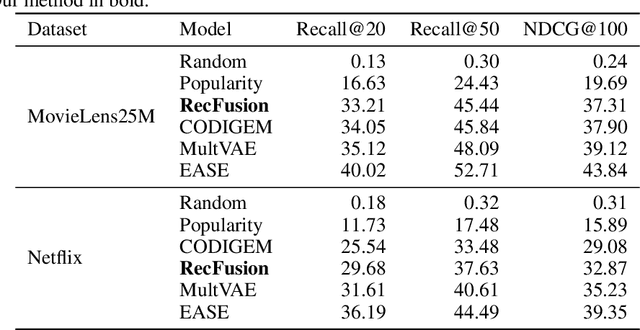
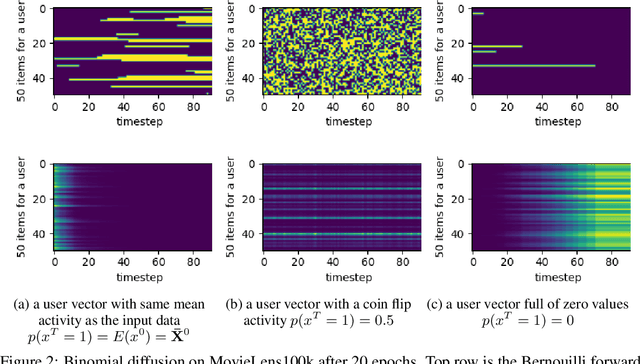
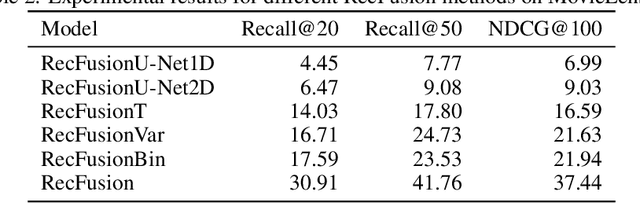
In this paper we propose RecFusion, which comprise a set of diffusion models for recommendation. Unlike image data which contain spatial correlations, a user-item interaction matrix, commonly utilized in recommendation, lacks spatial relationships between users and items. We formulate diffusion on a 1D vector and propose binomial diffusion, which explicitly models binary user-item interactions with a Bernoulli process. We show that RecFusion approaches the performance of complex VAE baselines on the core recommendation setting (top-n recommendation for binary non-sequential feedback) and the most common datasets (MovieLens and Netflix). Our proposed diffusion models that are specialized for 1D and/or binary setups have implications beyond recommendation systems, such as in the medical domain with MRI and CT scans.
Gen-IR @ SIGIR 2023: The First Workshop on Generative Information Retrieval
Jun 13, 2023Generative information retrieval (IR) has experienced substantial growth across multiple research communities (e.g., information retrieval, computer vision, natural language processing, and machine learning), and has been highly visible in the popular press. Theoretical, empirical, and actual user-facing products have been released that retrieve documents (via generation) or directly generate answers given an input request. We would like to investigate whether end-to-end generative models are just another trend or, as some claim, a paradigm change for IR. This necessitates new metrics, theoretical grounding, evaluation methods, task definitions, models, user interfaces, etc. The goal of this workshop (https://coda.io/@sigir/gen-ir) is to focus on previously explored Generative IR techniques like document retrieval and direct Grounded Answer Generation, while also offering a venue for the discussion and exploration of how Generative IR can be applied to new domains like recommendation systems, summarization, etc. The format of the workshop is interactive, including roundtable and keynote sessions and tends to avoid the one-sided dialogue of a mini-conference.
RADio -- Rank-Aware Divergence Metrics to Measure Normative Diversity in News Recommendations
Sep 17, 2022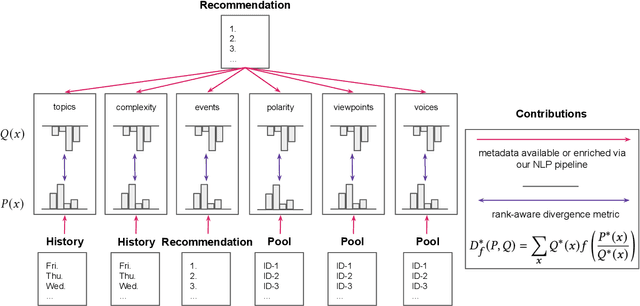

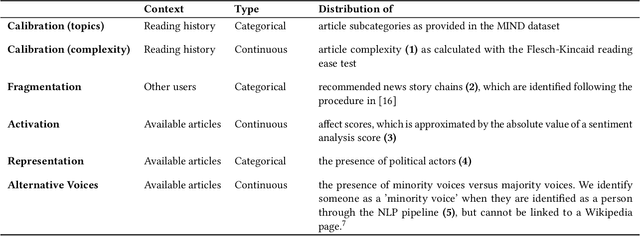
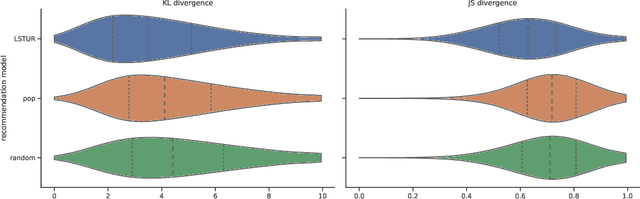
In traditional recommender system literature, diversity is often seen as the opposite of similarity, and typically defined as the distance between identified topics, categories or word models. However, this is not expressive of the social science's interpretation of diversity, which accounts for a news organization's norms and values and which we here refer to as normative diversity. We introduce RADio, a versatile metrics framework to evaluate recommendations according to these normative goals. RADio introduces a rank-aware Jensen Shannon (JS) divergence. This combination accounts for (i) a user's decreasing propensity to observe items further down a list and (ii) full distributional shifts as opposed to point estimates. We evaluate RADio's ability to reflect five normative concepts in news recommendations on the Microsoft News Dataset and six (neural) recommendation algorithms, with the help of our metadata enrichment pipeline. We find that RADio provides insightful estimates that can potentially be used to inform news recommender system design.
sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification
Aug 24, 2021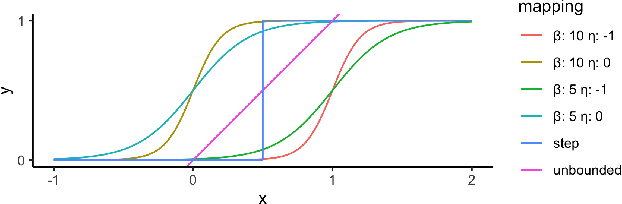

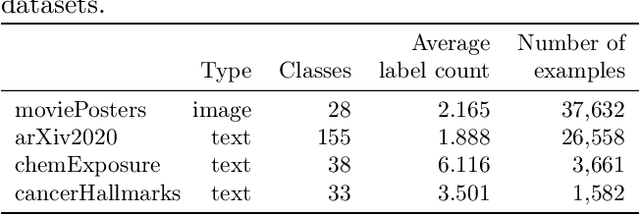
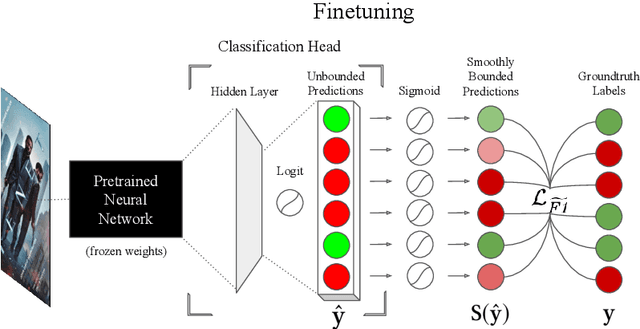
Multiclass multilabel classification refers to the task of attributing multiple labels to examples via predictions. Current models formulate a reduction of that multilabel setting into either multiple binary classifications or multiclass classification, allowing for the use of existing loss functions (sigmoid, cross-entropy, logistic, etc.). Empirically, these methods have been reported to achieve good performance on different metrics (F1 score, Recall, Precision, etc.). Theoretically though, the multilabel classification reductions does not accommodate for the prediction of varying numbers of labels per example and the underlying losses are distant estimates of the performance metrics. We propose a loss function, sigmoidF1. It is an approximation of the F1 score that (I) is smooth and tractable for stochastic gradient descent, (II) naturally approximates a multilabel metric, (III) estimates label propensities and label counts. More generally, we show that any confusion matrix metric can be formulated with a smooth surrogate. We evaluate the proposed loss function on different text and image datasets, and with a variety of metrics, to account for the complexity of multilabel classification evaluation. In our experiments, we embed the sigmoidF1 loss in a classification head that is attached to state-of-the-art efficient pretrained neural networks MobileNetV2 and DistilBERT. Our experiments show that sigmoidF1 outperforms other loss functions on four datasets and several metrics. These results show the effectiveness of using inference-time metrics as loss function at training time in general and their potential on non-trivial classification problems like multilabel classification.