 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes SpatioTemporal information benefit Two video summarization benchmarks?
Oct 04, 2024An important aspect of summarizing videos is understanding the temporal context behind each part of the video to grasp what is and is not important. Video summarization models have in recent years modeled spatio-temporal relationships to represent this information. These models achieved state-of-the-art correlation scores on important benchmark datasets. However, what has not been reviewed is whether spatio-temporal relationships are even required to achieve state-of-the-art results. Previous work in activity recognition has found biases, by prioritizing static cues such as scenes or objects, over motion information. In this paper we inquire if similar spurious relationships might influence the task of video summarization. To do so, we analyse the role that temporal information plays on existing benchmark datasets. We first estimate a baseline with temporally invariant models to see how well such models rank on benchmark datasets (TVSum and SumMe). We then disrupt the temporal order of the videos to investigate the impact it has on existing state-of-the-art models. One of our findings is that the temporally invariant models achieve competitive correlation scores that are close to the human baselines on the TVSum dataset. We also demonstrate that existing models are not affected by temporal perturbations. Furthermore, with certain disruption strategies that shuffle fixed time segments, we can actually improve their correlation scores. With these results, we find that spatio-temporal relationship play a minor role and we raise the question whether these benchmarks adequately model the task of video summarization. Code available at: https://github.com/AashGan/TemporalPerturbSum
Find the Cliffhanger: Multi-Modal Trailerness in Soap Operas
Jan 29, 2024Creating a trailer requires carefully picking out and piecing together brief enticing moments out of a longer video, making it a challenging and time-consuming task. This requires selecting moments based on both visual and dialogue information. We introduce a multi-modal method for predicting the trailerness to assist editors in selecting trailer-worthy moments from long-form videos. We present results on a newly introduced soap opera dataset, demonstrating that predicting trailerness is a challenging task that benefits from multi-modal information. Code is available at https://github.com/carlobretti/cliffhanger
VideolandGPT: A User Study on a Conversational Recommender System
Sep 07, 2023



This paper investigates how large language models (LLMs) can enhance recommender systems, with a specific focus on Conversational Recommender Systems that leverage user preferences and personalised candidate selections from existing ranking models. We introduce VideolandGPT, a recommender system for a Video-on-Demand (VOD) platform, Videoland, which uses ChatGPT to select from a predetermined set of contents, considering the additional context indicated by users' interactions with a chat interface. We evaluate ranking metrics, user experience, and fairness of recommendations, comparing a personalised and a non-personalised version of the system, in a between-subject user study. Our results indicate that the personalised version outperforms the non-personalised in terms of accuracy and general user satisfaction, while both versions increase the visibility of items which are not in the top of the recommendation lists. However, both versions present inconsistent behavior in terms of fairness, as the system may generate recommendations which are not available on Videoland.
RecFusion: A Binomial Diffusion Process for 1D Data for Recommendation
Jun 19, 2023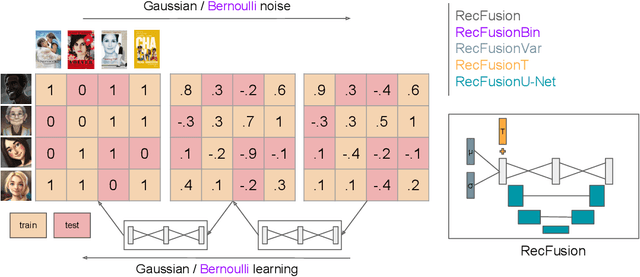
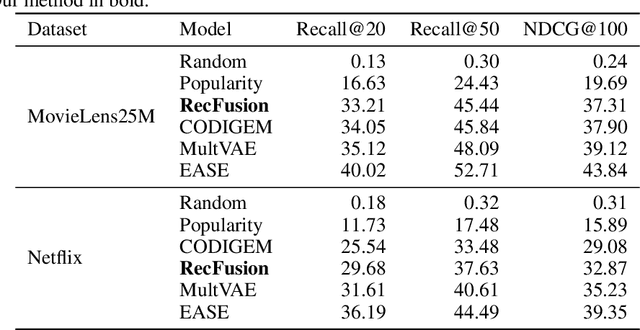
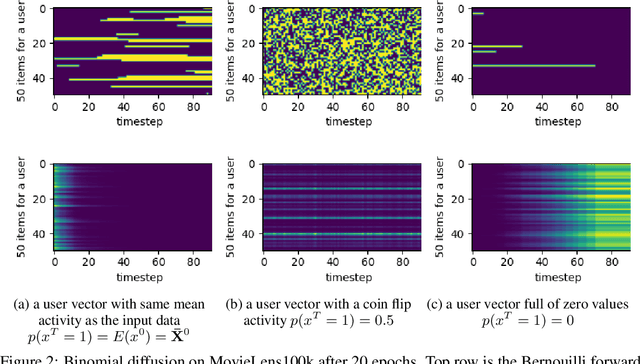
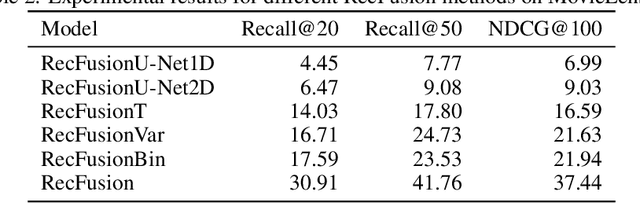
In this paper we propose RecFusion, which comprise a set of diffusion models for recommendation. Unlike image data which contain spatial correlations, a user-item interaction matrix, commonly utilized in recommendation, lacks spatial relationships between users and items. We formulate diffusion on a 1D vector and propose binomial diffusion, which explicitly models binary user-item interactions with a Bernoulli process. We show that RecFusion approaches the performance of complex VAE baselines on the core recommendation setting (top-n recommendation for binary non-sequential feedback) and the most common datasets (MovieLens and Netflix). Our proposed diffusion models that are specialized for 1D and/or binary setups have implications beyond recommendation systems, such as in the medical domain with MRI and CT scans.
RADio -- Rank-Aware Divergence Metrics to Measure Normative Diversity in News Recommendations
Sep 17, 2022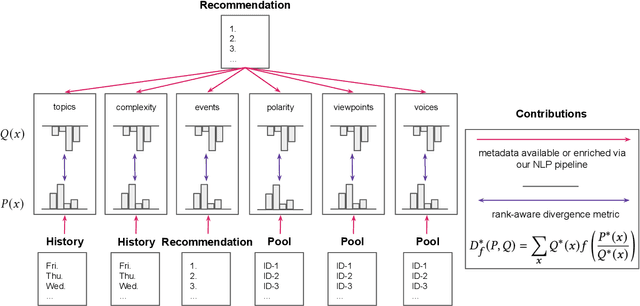

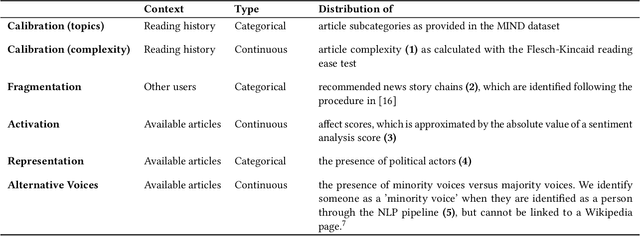
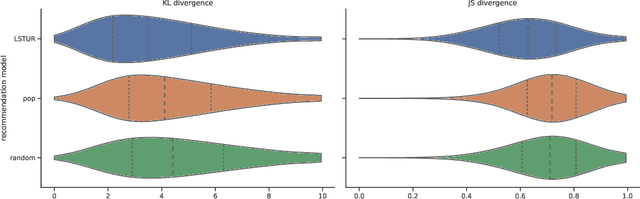
In traditional recommender system literature, diversity is often seen as the opposite of similarity, and typically defined as the distance between identified topics, categories or word models. However, this is not expressive of the social science's interpretation of diversity, which accounts for a news organization's norms and values and which we here refer to as normative diversity. We introduce RADio, a versatile metrics framework to evaluate recommendations according to these normative goals. RADio introduces a rank-aware Jensen Shannon (JS) divergence. This combination accounts for (i) a user's decreasing propensity to observe items further down a list and (ii) full distributional shifts as opposed to point estimates. We evaluate RADio's ability to reflect five normative concepts in news recommendations on the Microsoft News Dataset and six (neural) recommendation algorithms, with the help of our metadata enrichment pipeline. We find that RADio provides insightful estimates that can potentially be used to inform news recommender system design.
sigmoidF1: A Smooth F1 Score Surrogate Loss for Multilabel Classification
Aug 24, 2021

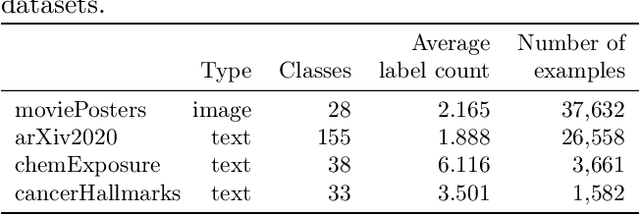
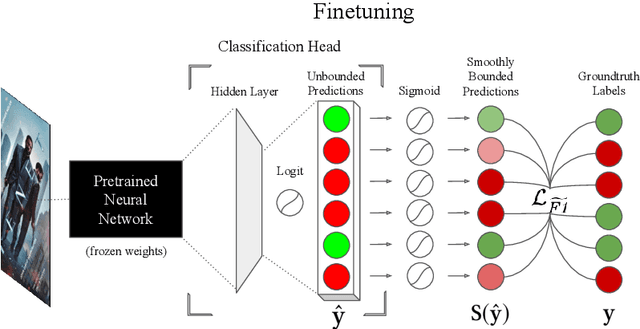
Multiclass multilabel classification refers to the task of attributing multiple labels to examples via predictions. Current models formulate a reduction of that multilabel setting into either multiple binary classifications or multiclass classification, allowing for the use of existing loss functions (sigmoid, cross-entropy, logistic, etc.). Empirically, these methods have been reported to achieve good performance on different metrics (F1 score, Recall, Precision, etc.). Theoretically though, the multilabel classification reductions does not accommodate for the prediction of varying numbers of labels per example and the underlying losses are distant estimates of the performance metrics. We propose a loss function, sigmoidF1. It is an approximation of the F1 score that (I) is smooth and tractable for stochastic gradient descent, (II) naturally approximates a multilabel metric, (III) estimates label propensities and label counts. More generally, we show that any confusion matrix metric can be formulated with a smooth surrogate. We evaluate the proposed loss function on different text and image datasets, and with a variety of metrics, to account for the complexity of multilabel classification evaluation. In our experiments, we embed the sigmoidF1 loss in a classification head that is attached to state-of-the-art efficient pretrained neural networks MobileNetV2 and DistilBERT. Our experiments show that sigmoidF1 outperforms other loss functions on four datasets and several metrics. These results show the effectiveness of using inference-time metrics as loss function at training time in general and their potential on non-trivial classification problems like multilabel classification.
Faithfully Explaining Rankings in a News Recommender System
May 14, 2018

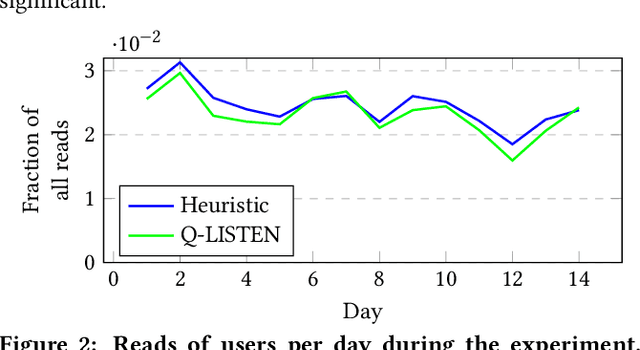
There is an increasing demand for algorithms to explain their outcomes. So far, there is no method that explains the rankings produced by a ranking algorithm. To address this gap we propose LISTEN, a LISTwise ExplaiNer, to explain rankings produced by a ranking algorithm. To efficiently use LISTEN in production, we train a neural network to learn the underlying explanation space created by LISTEN; we call this model Q-LISTEN. We show that LISTEN produces faithful explanations and that Q-LISTEN is able to learn these explanations. Moreover, we show that LISTEN is safe to use in a real world environment: users of a news recommendation system do not behave significantly differently when they are exposed to explanations generated by LISTEN instead of manually generated explanations.
The Birth of Collective Memories: Analyzing Emerging Entities in Text Streams
Dec 08, 2017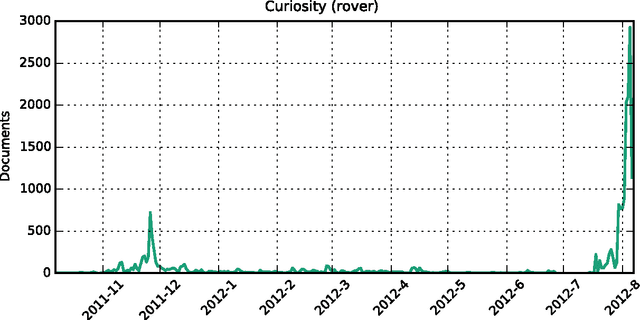
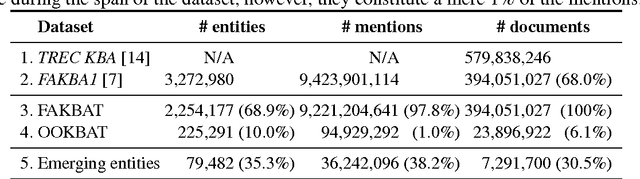
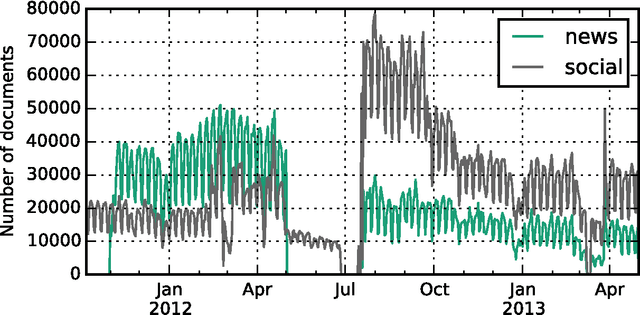
We study how collective memories are formed online. We do so by tracking entities that emerge in public discourse, that is, in online text streams such as social media and news streams, before they are incorporated into Wikipedia, which, we argue, can be viewed as an online place for collective memory. By tracking how entities emerge in public discourse, i.e., the temporal patterns between their first mention in online text streams and subsequent incorporation into collective memory, we gain insights into how the collective remembrance process happens online. Specifically, we analyze nearly 80,000 entities as they emerge in online text streams before they are incorporated into Wikipedia. The online text streams we use for our analysis comprise of social media and news streams, and span over 579 million documents in a timespan of 18 months. We discover two main emergence patterns: entities that emerge in a "bursty" fashion, i.e., that appear in public discourse without a precedent, blast into activity and transition into collective memory. Other entities display a "delayed" pattern, where they appear in public discourse, experience a period of inactivity, and then resurface before transitioning into our cultural collective memory.