 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Quotes to Concepts: Axial Coding of Political Debates with Ensemble LMs
Jan 20, 2026Axial coding is a commonly used qualitative analysis method that enhances document understanding by organizing sentence-level open codes into broader categories. In this paper, we operationalize axial coding with large language models (LLMs). Extending an ensemble-based open coding approach with an LLM moderator, we add an axial coding step that groups open codes into higher-order categories, transforming raw debate transcripts into concise, hierarchical representations. We compare two strategies: (i) clustering embeddings of code-utterance pairs using density-based and partitioning algorithms followed by LLM labeling, and (ii) direct LLM-based grouping of codes and utterances into categories. We apply our method to Dutch parliamentary debates, converting lengthy transcripts into compact, hierarchically structured codes and categories. We evaluate our method using extrinsic metrics aligned with human-assigned topic labels (ROUGE-L, cosine, BERTScore), and intrinsic metrics describing code groups (coverage, brevity, coherence, novelty, JSD divergence). Our results reveal a trade-off: density-based clustering achieves high coverage and strong cluster alignment, while direct LLM grouping results in higher fine-grained alignment, but lower coverage 20%. Overall, clustering maximizes coverage and structural separation, whereas LLM grouping produces more concise, interpretable, and semantically aligned categories. To support future research, we publicly release the full dataset of utterances and codes, enabling reproducibility and comparative studies.
Aspect-Based Sentiment Analysis for Open-Ended HR Survey Responses
Feb 07, 2024



Understanding preferences, opinions, and sentiment of the workforce is paramount for effective employee lifecycle management. Open-ended survey responses serve as a valuable source of information. This paper proposes a machine learning approach for aspect-based sentiment analysis (ABSA) of Dutch open-ended responses in employee satisfaction surveys. Our approach aims to overcome the inherent noise and variability in these responses, enabling a comprehensive analysis of sentiments that can support employee lifecycle management. Through response clustering we identify six key aspects (salary, schedule, contact, communication, personal attention, agreements), which we validate by domain experts. We compile a dataset of 1,458 Dutch survey responses, revealing label imbalance in aspects and sentiments. We propose few-shot approaches for ABSA based on Dutch BERT models, and compare them against bag-of-words and zero-shot baselines. Our work significantly contributes to the field of ABSA by demonstrating the first successful application of Dutch pre-trained language models to aspect-based sentiment analysis in the domain of human resources (HR).
Career Path Recommendations for Long-term Income Maximization: A Reinforcement Learning Approach
Sep 11, 2023This study explores the potential of reinforcement learning algorithms to enhance career planning processes. Leveraging data from Randstad The Netherlands, the study simulates the Dutch job market and develops strategies to optimize employees' long-term income. By formulating career planning as a Markov Decision Process (MDP) and utilizing machine learning algorithms such as Sarsa, Q-Learning, and A2C, we learn optimal policies that recommend career paths with high-income occupations and industries. The results demonstrate significant improvements in employees' income trajectories, with RL models, particularly Q-Learning and Sarsa, achieving an average increase of 5% compared to observed career paths. The study acknowledges limitations, including narrow job filtering, simplifications in the environment formulation, and assumptions regarding employment continuity and zero application costs. Future research can explore additional objectives beyond income optimization and address these limitations to further enhance career planning processes.
Enhancing PLM Performance on Labour Market Tasks via Instruction-based Finetuning and Prompt-tuning with Rules
Aug 31, 2023The increased digitization of the labour market has given researchers, educators, and companies the means to analyze and better understand the labour market. However, labour market resources, although available in high volumes, tend to be unstructured, and as such, research towards methodologies for the identification, linking, and extraction of entities becomes more and more important. Against the backdrop of this quest for better labour market representations, resource constraints and the unavailability of large-scale annotated data cause a reliance on human domain experts. We demonstrate the effectiveness of prompt-based tuning of pre-trained language models (PLM) in labour market specific applications. Our results indicate that cost-efficient methods such as PTR and instruction tuning without exemplars can significantly increase the performance of PLMs on downstream labour market applications without introducing additional model layers, manual annotations, and data augmentation.
conSultantBERT: Fine-tuned Siamese Sentence-BERT for Matching Jobs and Job Seekers
Sep 14, 2021
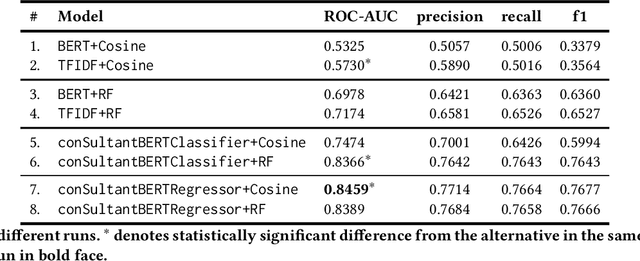
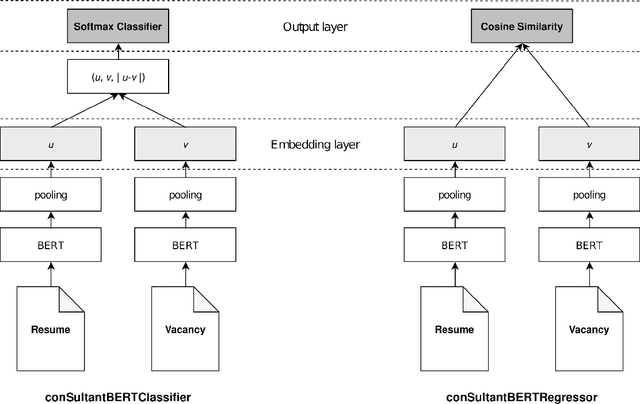
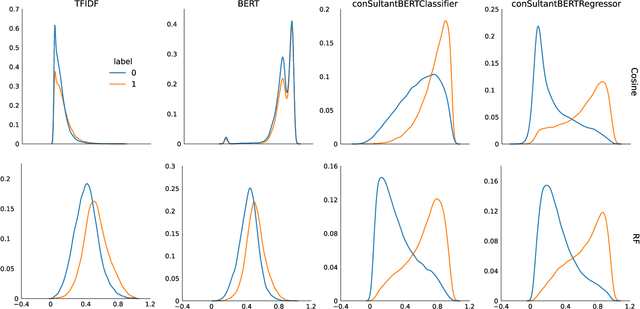
In this paper we focus on constructing useful embeddings of textual information in vacancies and resumes, which we aim to incorporate as features into job to job seeker matching models alongside other features. We explain our task where noisy data from parsed resumes, heterogeneous nature of the different sources of data, and crosslinguality and multilinguality present domain-specific challenges. We address these challenges by fine-tuning a Siamese Sentence-BERT (SBERT) model, which we call conSultantBERT, using a large-scale, real-world, and high quality dataset of over 270,000 resume-vacancy pairs labeled by our staffing consultants. We show how our fine-tuned model significantly outperforms unsupervised and supervised baselines that rely on TF-IDF-weighted feature vectors and BERT embeddings. In addition, we find our model successfully matches cross-lingual and multilingual textual content.
Job Posting-Enriched Knowledge Graph for Skills-based Matching
Sep 06, 2021


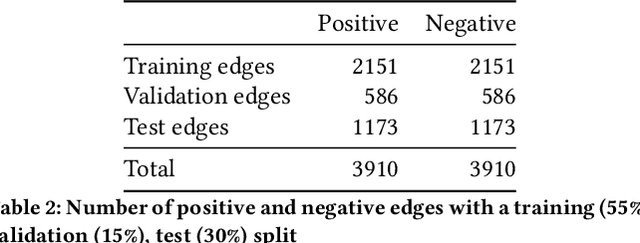
The labor market is constantly evolving. Occupations are changing, being added, or disappearing to fit the needs of today's market. In recent years the pace of this change has accelerated, due to factors such as globalization, digitization, and the shift to working from home. Different factors are relevant when selecting employment, e.g., cultural fit, compensation, provided degree of freedom. To successfully fulfill an occupation the gap between required (by the job) and possessed (by the job seeker) skills needs to be as small as possible. Decreasing this skill-gap improves the fit between a job candidate and occupation. In this paper we propose a custom-built Skills & Occupation Knowledge Graph (KG) that fits the above described dynamic nature of the labor market, by leveraging existing skills and occupation taxonomies enriched with external job posting data. We leverage this KG and explore several applications for skills-based matching of jobs to job seekers. First, we study link prediction as a means to quantify relevance of skills to occupations, which can help in prioritizing learning and development of employees. Next, we study node similarity methods and shortest path algorithms for career pathfinding. Finally, we leverage a term weighting method for identifying which skills are most "distinctive" for different (types of) occupations.
Entities of Interest
Feb 22, 2021


In the era of big data, we continuously - and at times unknowingly - leave behind digital traces, by browsing, sharing, posting, liking, searching, watching, and listening to online content. When aggregated, these digital traces can provide powerful insights into the behavior, preferences, activities, and traits of people. While many have raised privacy concerns around the use of aggregated digital traces, it has undisputedly brought us many advances, from the search engines that learn from their users and enable our access to unforeseen amounts of data, knowledge, and information, to, e.g., the discovery of previously unknown adverse drug reactions from search engine logs. Whether in online services, journalism, digital forensics, law, or research, we increasingly set out to exploring large amounts of digital traces to discover new information. Consider for instance, the Enron scandal, Hillary Clinton's email controversy, or the Panama papers: cases that revolve around analyzing, searching, investigating, exploring, and turning upside down large amounts of digital traces to gain new insights, knowledge, and information. This discovery task is at its core about "finding evidence of activity in the real world." This dissertation revolves around discovery in digital traces, and sits at the intersection of Information Retrieval, Natural Language Processing, and applied Machine Learning. We propose computational methods that aim to support the exploration and sense-making process of large collections of digital traces. We focus on textual traces, e.g., emails and social media streams, and address two aspects that are central to discovery in digital traces.
Beyond Optimizing for Clicks: Incorporating Editorial Values in News Recommendation
Apr 21, 2020


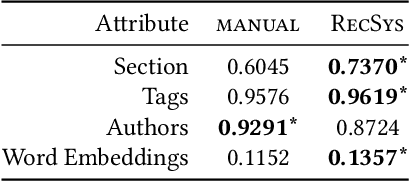
With the uptake of algorithmic personalization in the news domain, news organizations increasingly trust automated systems with previously considered editorial responsibilities, e.g., prioritizing news to readers. In this paper we study an automated news recommender system in the context of a news organization's editorial values. We conduct and present two online studies with a news recommender system, which span one and a half months and involve over 1,200 users. In our first study we explore how our news recommender steers reading behavior in the context of editorial values such as serendipity, dynamism, diversity, and coverage. Next, we present an intervention study where we extend our news recommender to steer our readers to more dynamic reading behavior. We find that (i) our recommender system yields more diverse reading behavior and yields a higher coverage of articles compared to non-personalized editorial rankings, and (ii) we can successfully incorporate dynamism in our recommender system as a re-ranking method, effectively steering our readers to more dynamic articles without hurting our recommender system's accuracy.
Improving automated segmentation of radio shows with audio embeddings
Feb 12, 2020
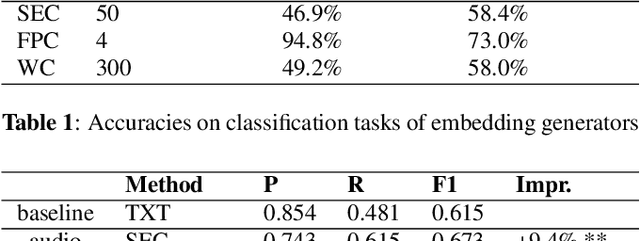
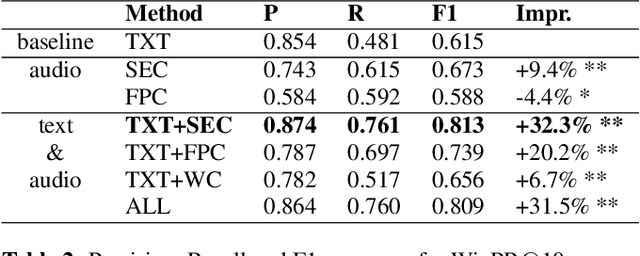
Audio features have been proven useful for increasing the performance of automated topic segmentation systems. This study explores the novel task of using audio embeddings for automated, topically coherent segmentation of radio shows. We created three different audio embedding generators using multi-class classification tasks on three datasets from different domains. We evaluate topic segmentation performance of the audio embeddings and compare it against a text-only baseline. We find that a set-up including audio embeddings generated through a non-speech sound event classification task significantly outperforms our text-only baseline by 32.3% in F1-measure. In addition, we find that different classification tasks yield audio embeddings that vary in segmentation performance.
The Birth of Collective Memories: Analyzing Emerging Entities in Text Streams
Dec 08, 2017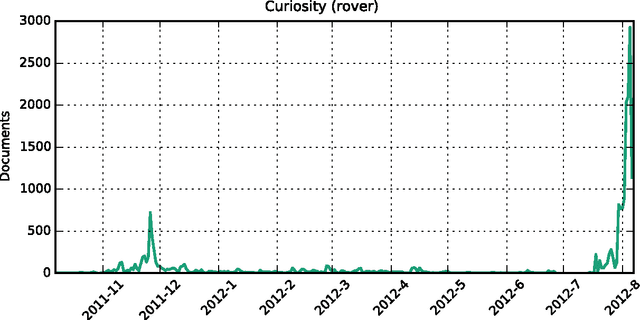
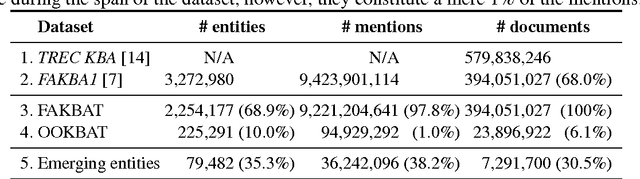
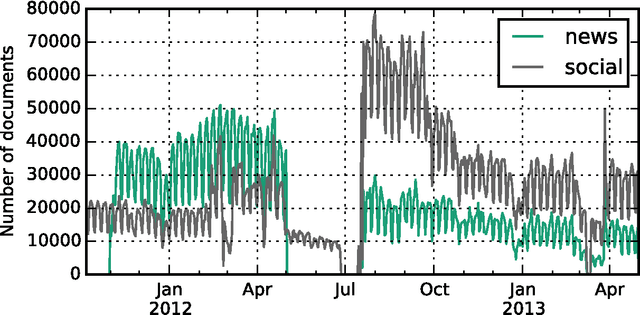
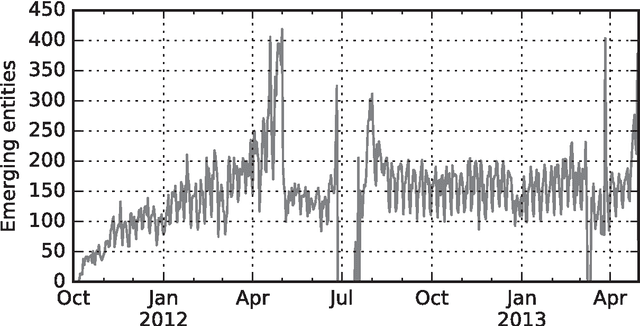
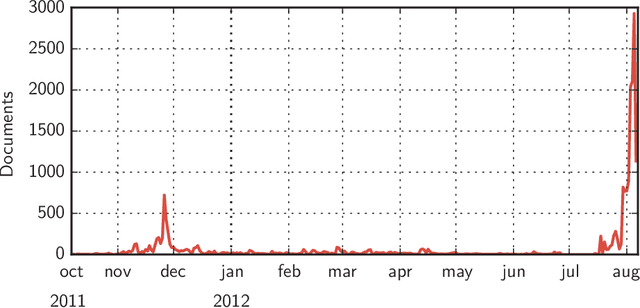
We study how collective memories are formed online. We do so by tracking entities that emerge in public discourse, that is, in online text streams such as social media and news streams, before they are incorporated into Wikipedia, which, we argue, can be viewed as an online place for collective memory. By tracking how entities emerge in public discourse, i.e., the temporal patterns between their first mention in online text streams and subsequent incorporation into collective memory, we gain insights into how the collective remembrance process happens online. Specifically, we analyze nearly 80,000 entities as they emerge in online text streams before they are incorporated into Wikipedia. The online text streams we use for our analysis comprise of social media and news streams, and span over 579 million documents in a timespan of 18 months. We discover two main emergence patterns: entities that emerge in a "bursty" fashion, i.e., that appear in public discourse without a precedent, blast into activity and transition into collective memory. Other entities display a "delayed" pattern, where they appear in public discourse, experience a period of inactivity, and then resurface before transitioning into our cultural collective memory.