 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving automated segmentation of radio shows with audio embeddings
Feb 12, 2020
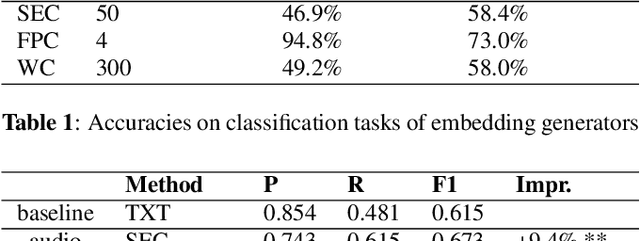
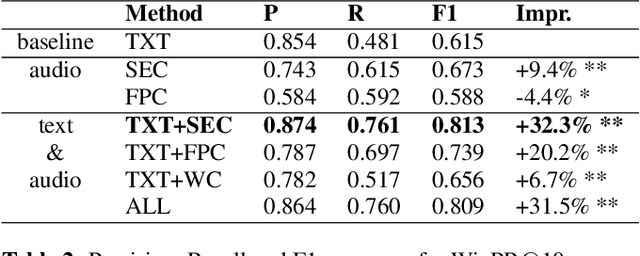
Audio features have been proven useful for increasing the performance of automated topic segmentation systems. This study explores the novel task of using audio embeddings for automated, topically coherent segmentation of radio shows. We created three different audio embedding generators using multi-class classification tasks on three datasets from different domains. We evaluate topic segmentation performance of the audio embeddings and compare it against a text-only baseline. We find that a set-up including audio embeddings generated through a non-speech sound event classification task significantly outperforms our text-only baseline by 32.3% in F1-measure. In addition, we find that different classification tasks yield audio embeddings that vary in segmentation performance.