 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Optimizing for Clicks: Incorporating Editorial Values in News Recommendation
Apr 21, 2020


With the uptake of algorithmic personalization in the news domain, news organizations increasingly trust automated systems with previously considered editorial responsibilities, e.g., prioritizing news to readers. In this paper we study an automated news recommender system in the context of a news organization's editorial values. We conduct and present two online studies with a news recommender system, which span one and a half months and involve over 1,200 users. In our first study we explore how our news recommender steers reading behavior in the context of editorial values such as serendipity, dynamism, diversity, and coverage. Next, we present an intervention study where we extend our news recommender to steer our readers to more dynamic reading behavior. We find that (i) our recommender system yields more diverse reading behavior and yields a higher coverage of articles compared to non-personalized editorial rankings, and (ii) we can successfully incorporate dynamism in our recommender system as a re-ranking method, effectively steering our readers to more dynamic articles without hurting our recommender system's accuracy.
A Crowdsourced Frame Disambiguation Corpus with Ambiguity
Apr 12, 2019

We present a resource for the task of FrameNet semantic frame disambiguation of over 5,000 word-sentence pairs from the Wikipedia corpus. The annotations were collected using a novel crowdsourcing approach with multiple workers per sentence to capture inter-annotator disagreement. In contrast to the typical approach of attributing the best single frame to each word, we provide a list of frames with disagreement-based scores that express the confidence with which each frame applies to the word. This is based on the idea that inter-annotator disagreement is at least partly caused by ambiguity that is inherent to the text and frames. We have found many examples where the semantics of individual frames overlap sufficiently to make them acceptable alternatives for interpreting a sentence. We have argued that ignoring this ambiguity creates an overly arbitrary target for training and evaluating natural language processing systems - if humans cannot agree, why would we expect the correct answer from a machine to be any different? To process this data we also utilized an expanded lemma-set provided by the Framester system, which merges FN with WordNet to enhance coverage. Our dataset includes annotations of 1,000 sentence-word pairs whose lemmas are not part of FN. Finally we present metrics for evaluating frame disambiguation systems that account for ambiguity.
Crowdsourcing Semantic Label Propagation in Relation Classification
Sep 03, 2018
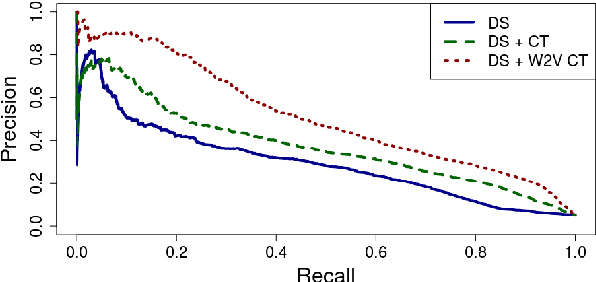
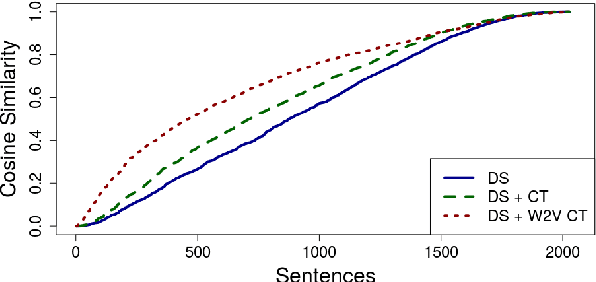
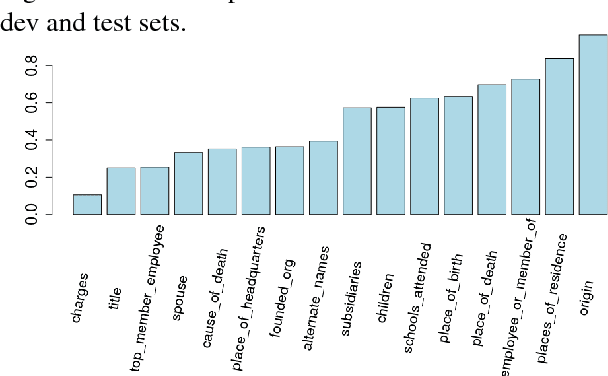
Distant supervision is a popular method for performing relation extraction from text that is known to produce noisy labels. Most progress in relation extraction and classification has been made with crowdsourced corrections to distant-supervised labels, and there is evidence that indicates still more would be better. In this paper, we explore the problem of propagating human annotation signals gathered for open-domain relation classification through the CrowdTruth methodology for crowdsourcing, that captures ambiguity in annotations by measuring inter-annotator disagreement. Our approach propagates annotations to sentences that are similar in a low dimensional embedding space, expanding the number of labels by two orders of magnitude. Our experiments show significant improvement in a sentence-level multi-class relation classifier.
Capturing Ambiguity in Crowdsourcing Frame Disambiguation
May 01, 2018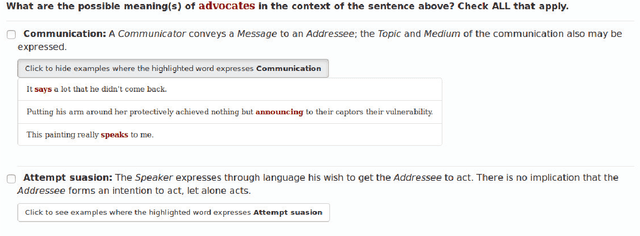

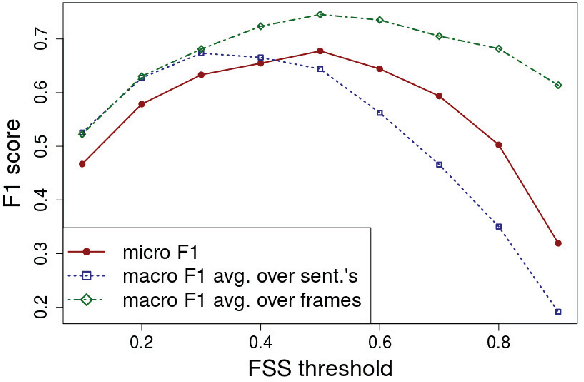
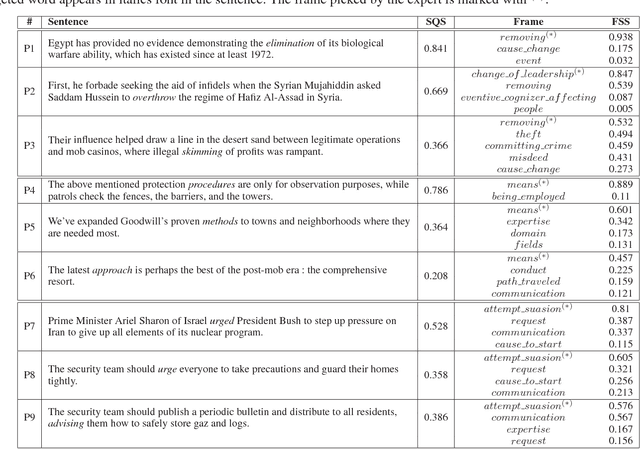
FrameNet is a computational linguistics resource composed of semantic frames, high-level concepts that represent the meanings of words. In this paper, we present an approach to gather frame disambiguation annotations in sentences using a crowdsourcing approach with multiple workers per sentence to capture inter-annotator disagreement. We perform an experiment over a set of 433 sentences annotated with frames from the FrameNet corpus, and show that the aggregated crowd annotations achieve an F1 score greater than 0.67 as compared to expert linguists. We highlight cases where the crowd annotation was correct even though the expert is in disagreement, arguing for the need to have multiple annotators per sentence. Most importantly, we examine cases in which crowd workers could not agree, and demonstrate that these cases exhibit ambiguity, either in the sentence, frame, or the task itself, and argue that collapsing such cases to a single, discrete truth value (i.e. correct or incorrect) is inappropriate, creating arbitrary targets for machine learning.
False Positive and Cross-relation Signals in Distant Supervision Data
Nov 29, 2017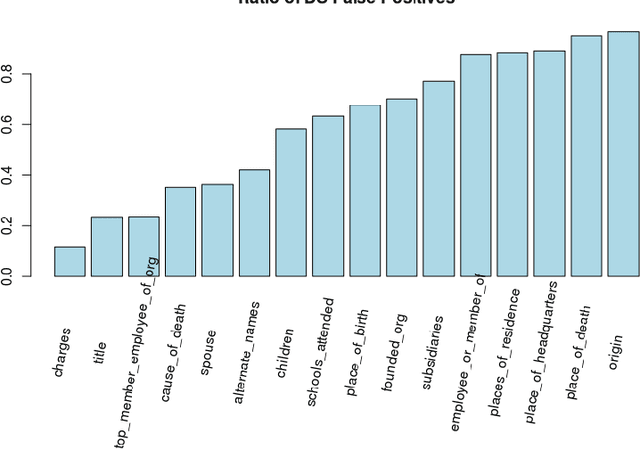
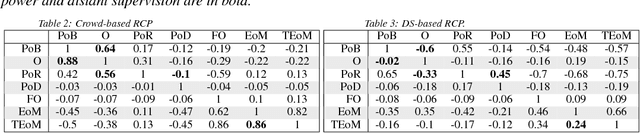
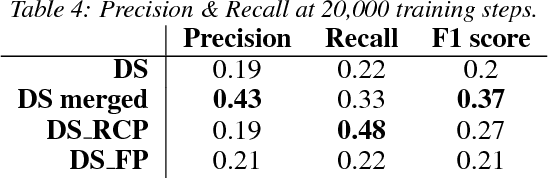
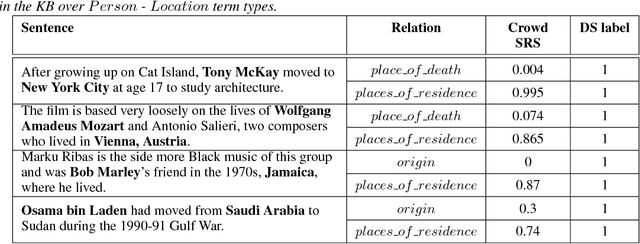
Distant supervision (DS) is a well-established method for relation extraction from text, based on the assumption that when a knowledge-base contains a relation between a term pair, then sentences that contain that pair are likely to express the relation. In this paper, we use the results of a crowdsourcing relation extraction task to identify two problems with DS data quality: the widely varying degree of false positives across different relations, and the observed causal connection between relations that are not considered by the DS method. The crowdsourcing data aggregation is performed using ambiguity-aware CrowdTruth metrics, that are used to capture and interpret inter-annotator disagreement. We also present preliminary results of using the crowd to enhance DS training data for a relation classification model, without requiring the crowd to annotate the entire set.
Crowdsourcing Ground Truth for Medical Relation Extraction
Oct 03, 2017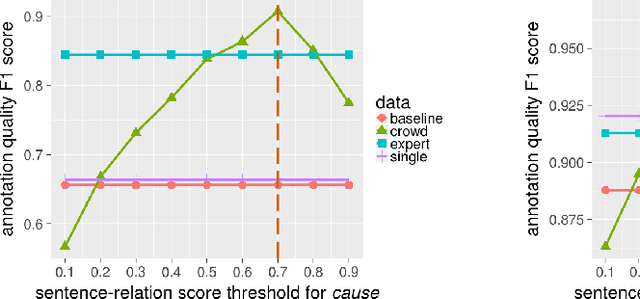

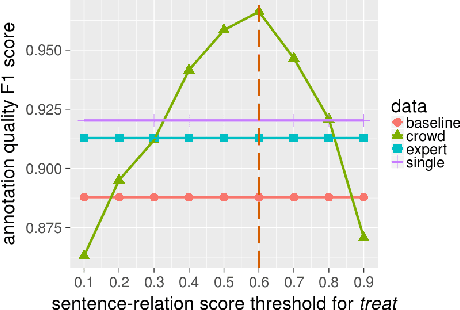

Cognitive computing systems require human labeled data for evaluation, and often for training. The standard practice used in gathering this data minimizes disagreement between annotators, and we have found this results in data that fails to account for the ambiguity inherent in language. We have proposed the CrowdTruth method for collecting ground truth through crowdsourcing, that reconsiders the role of people in machine learning based on the observation that disagreement between annotators provides a useful signal for phenomena such as ambiguity in the text. We report on using this method to build an annotated data set for medical relation extraction for the $cause$ and $treat$ relations, and how this data performed in a supervised training experiment. We demonstrate that by modeling ambiguity, labeled data gathered from crowd workers can (1) reach the level of quality of domain experts for this task while reducing the cost, and (2) provide better training data at scale than distant supervision. We further propose and validate new weighted measures for precision, recall, and F-measure, that account for ambiguity in both human and machine performance on this task.
* Accepted for publication in ACM Transactions on Interactive Intelligent Systems (TiiS) Special Issue on Human-Centered Machine Learning