 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Crowdsourced Frame Disambiguation Corpus with Ambiguity
Paper and Code


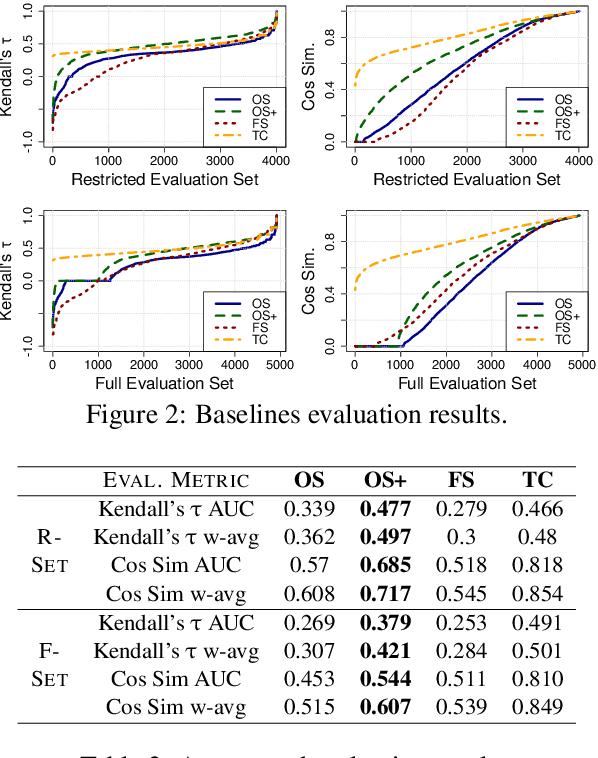
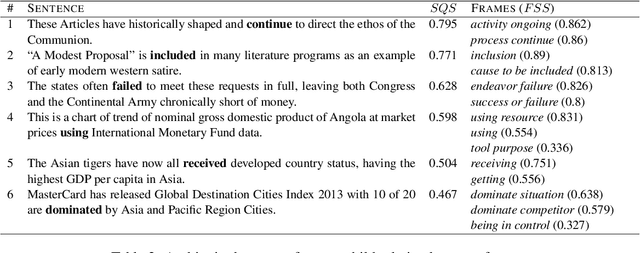
We present a resource for the task of FrameNet semantic frame disambiguation of over 5,000 word-sentence pairs from the Wikipedia corpus. The annotations were collected using a novel crowdsourcing approach with multiple workers per sentence to capture inter-annotator disagreement. In contrast to the typical approach of attributing the best single frame to each word, we provide a list of frames with disagreement-based scores that express the confidence with which each frame applies to the word. This is based on the idea that inter-annotator disagreement is at least partly caused by ambiguity that is inherent to the text and frames. We have found many examples where the semantics of individual frames overlap sufficiently to make them acceptable alternatives for interpreting a sentence. We have argued that ignoring this ambiguity creates an overly arbitrary target for training and evaluating natural language processing systems - if humans cannot agree, why would we expect the correct answer from a machine to be any different? To process this data we also utilized an expanded lemma-set provided by the Framester system, which merges FN with WordNet to enhance coverage. Our dataset includes annotations of 1,000 sentence-word pairs whose lemmas are not part of FN. Finally we present metrics for evaluating frame disambiguation systems that account for ambiguity.