 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Seed to Harvest: Augmenting Human Creativity with AI for Red-teaming Text-to-Image Models
Jul 23, 2025Text-to-image (T2I) models have become prevalent across numerous applications, making their robust evaluation against adversarial attacks a critical priority. Continuous access to new and challenging adversarial prompts across diverse domains is essential for stress-testing these models for resilience against novel attacks from multiple vectors. Current techniques for generating such prompts are either entirely authored by humans or synthetically generated. On the one hand, datasets of human-crafted adversarial prompts are often too small in size and imbalanced in their cultural and contextual representation. On the other hand, datasets of synthetically-generated prompts achieve scale, but typically lack the realistic nuances and creative adversarial strategies found in human-crafted prompts. To combine the strengths of both human and machine approaches, we propose Seed2Harvest, a hybrid red-teaming method for guided expansion of culturally diverse, human-crafted adversarial prompt seeds. The resulting prompts preserve the characteristics and attack patterns of human prompts while maintaining comparable average attack success rates (0.31 NudeNet, 0.36 SD NSFW, 0.12 Q16). Our expanded dataset achieves substantially higher diversity with 535 unique geographic locations and a Shannon entropy of 7.48, compared to 58 locations and 5.28 entropy in the original dataset. Our work demonstrates the importance of human-machine collaboration in leveraging human creativity and machine computational capacity to achieve comprehensive, scalable red-teaming for continuous T2I model safety evaluation.
Insights on Disagreement Patterns in Multimodal Safety Perception across Diverse Rater Groups
Oct 22, 2024



AI systems crucially rely on human ratings, but these ratings are often aggregated, obscuring the inherent diversity of perspectives in real-world phenomenon. This is particularly concerning when evaluating the safety of generative AI, where perceptions and associated harms can vary significantly across socio-cultural contexts. While recent research has studied the impact of demographic differences on annotating text, there is limited understanding of how these subjective variations affect multimodal safety in generative AI. To address this, we conduct a large-scale study employing highly-parallel safety ratings of about 1000 text-to-image (T2I) generations from a demographically diverse rater pool of 630 raters balanced across 30 intersectional groups across age, gender, and ethnicity. Our study shows that (1) there are significant differences across demographic groups (including intersectional groups) on how severe they assess the harm to be, and that these differences vary across different types of safety violations, (2) the diverse rater pool captures annotation patterns that are substantially different from expert raters trained on specific set of safety policies, and (3) the differences we observe in T2I safety are distinct from previously documented group level differences in text-based safety tasks. To further understand these varying perspectives, we conduct a qualitative analysis of the open-ended explanations provided by raters. This analysis reveals core differences into the reasons why different groups perceive harms in T2I generations. Our findings underscore the critical need for incorporating diverse perspectives into safety evaluation of generative AI ensuring these systems are truly inclusive and reflect the values of all users.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
AART: AI-Assisted Red-Teaming with Diverse Data Generation for New LLM-powered Applications
Nov 29, 2023Adversarial testing of large language models (LLMs) is crucial for their safe and responsible deployment. We introduce a novel approach for automated generation of adversarial evaluation datasets to test the safety of LLM generations on new downstream applications. We call it AI-assisted Red-Teaming (AART) - an automated alternative to current manual red-teaming efforts. AART offers a data generation and augmentation pipeline of reusable and customizable recipes that reduce human effort significantly and enable integration of adversarial testing earlier in new product development. AART generates evaluation datasets with high diversity of content characteristics critical for effective adversarial testing (e.g. sensitive and harmful concepts, specific to a wide range of cultural and geographic regions and application scenarios). The data generation is steered by AI-assisted recipes to define, scope and prioritize diversity within the application context. This feeds into a structured LLM-generation process that scales up evaluation priorities. Compared to some state-of-the-art tools, AART shows promising results in terms of concept coverage and data quality.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
A Framework to Assess agreement Among Diverse Rater Groups
Nov 09, 2023Recent advancements in conversational AI have created an urgent need for safety guardrails that prevent users from being exposed to offensive and dangerous content. Much of this work relies on human ratings and feedback, but does not account for the fact that perceptions of offense and safety are inherently subjective and that there may be systematic disagreements between raters that align with their socio-demographic identities. Instead, current machine learning approaches largely ignore rater subjectivity and use gold standards that obscure disagreements (e.g., through majority voting). In order to better understand the socio-cultural leanings of such tasks, we propose a comprehensive disagreement analysis framework to measure systematic diversity in perspectives among different rater subgroups. We then demonstrate its utility by applying this framework to a dataset of human-chatbot conversations rated by a demographically diverse pool of raters. Our analysis reveals specific rater groups that have more diverse perspectives than the rest, and informs demographic axes that are crucial to consider for safety annotations.
Collect, Measure, Repeat: Reliability Factors for Responsible AI Data Collection
Aug 22, 2023

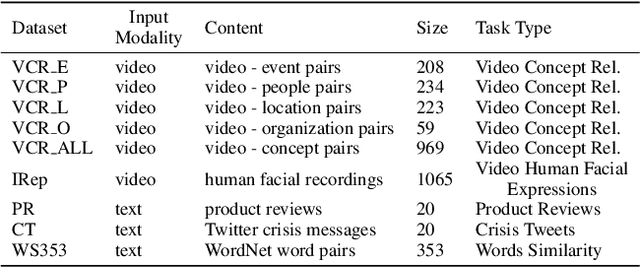

The rapid entry of machine learning approaches in our daily activities and high-stakes domains demands transparency and scrutiny of their fairness and reliability. To help gauge machine learning models' robustness, research typically focuses on the massive datasets used for their deployment, e.g., creating and maintaining documentation for understanding their origin, process of development, and ethical considerations. However, data collection for AI is still typically a one-off practice, and oftentimes datasets collected for a certain purpose or application are reused for a different problem. Additionally, dataset annotations may not be representative over time, contain ambiguous or erroneous annotations, or be unable to generalize across issues or domains. Recent research has shown these practices might lead to unfair, biased, or inaccurate outcomes. We argue that data collection for AI should be performed in a responsible manner where the quality of the data is thoroughly scrutinized and measured through a systematic set of appropriate metrics. In this paper, we propose a Responsible AI (RAI) methodology designed to guide the data collection with a set of metrics for an iterative in-depth analysis of the factors influencing the quality and reliability} of the generated data. We propose a granular set of measurements to inform on the internal reliability of a dataset and its external stability over time. We validate our approach across nine existing datasets and annotation tasks and four content modalities. This approach impacts the assessment of data robustness used for AI applied in the real world, where diversity of users and content is eminent. Furthermore, it deals with fairness and accountability aspects in data collection by providing systematic and transparent quality analysis for data collections.