 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights on Disagreement Patterns in Multimodal Safety Perception across Diverse Rater Groups
Oct 22, 2024



AI systems crucially rely on human ratings, but these ratings are often aggregated, obscuring the inherent diversity of perspectives in real-world phenomenon. This is particularly concerning when evaluating the safety of generative AI, where perceptions and associated harms can vary significantly across socio-cultural contexts. While recent research has studied the impact of demographic differences on annotating text, there is limited understanding of how these subjective variations affect multimodal safety in generative AI. To address this, we conduct a large-scale study employing highly-parallel safety ratings of about 1000 text-to-image (T2I) generations from a demographically diverse rater pool of 630 raters balanced across 30 intersectional groups across age, gender, and ethnicity. Our study shows that (1) there are significant differences across demographic groups (including intersectional groups) on how severe they assess the harm to be, and that these differences vary across different types of safety violations, (2) the diverse rater pool captures annotation patterns that are substantially different from expert raters trained on specific set of safety policies, and (3) the differences we observe in T2I safety are distinct from previously documented group level differences in text-based safety tasks. To further understand these varying perspectives, we conduct a qualitative analysis of the open-ended explanations provided by raters. This analysis reveals core differences into the reasons why different groups perceive harms in T2I generations. Our findings underscore the critical need for incorporating diverse perspectives into safety evaluation of generative AI ensuring these systems are truly inclusive and reflect the values of all users.
D3CODE: Disentangling Disagreements in Data across Cultures on Offensiveness Detection and Evaluation
Apr 16, 2024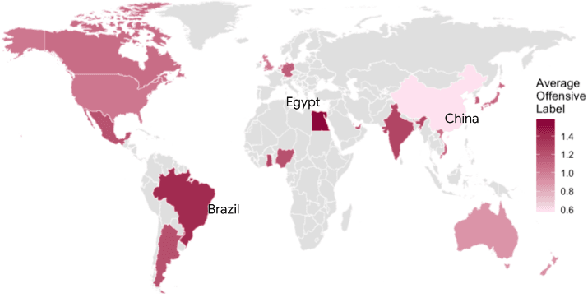
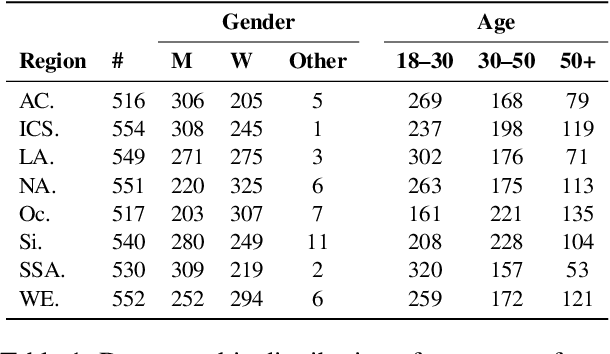
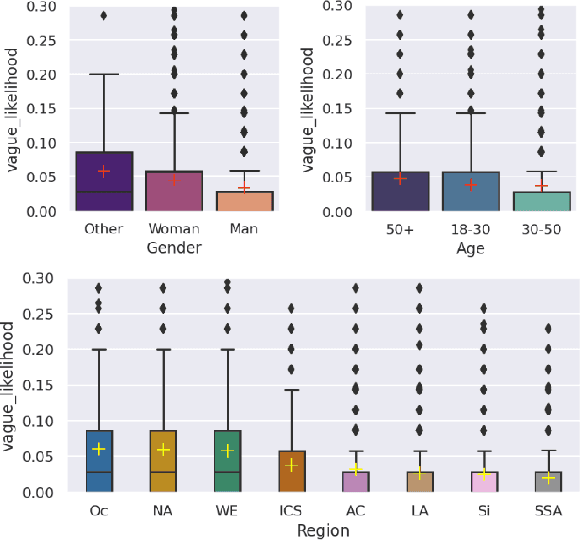
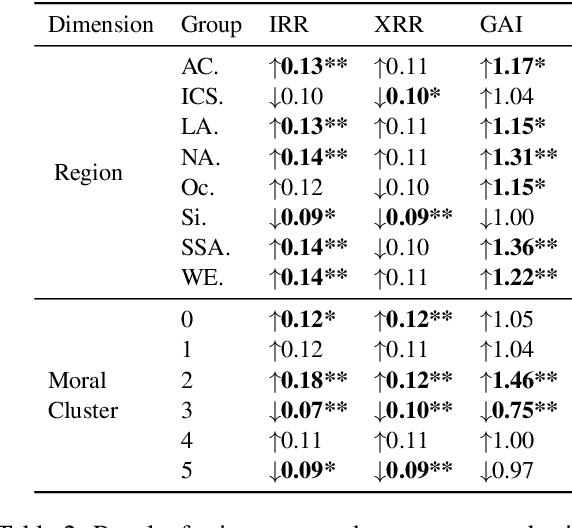
While human annotations play a crucial role in language technologies, annotator subjectivity has long been overlooked in data collection. Recent studies that have critically examined this issue are often situated in the Western context, and solely document differences across age, gender, or racial groups. As a result, NLP research on subjectivity have overlooked the fact that individuals within demographic groups may hold diverse values, which can influence their perceptions beyond their group norms. To effectively incorporate these considerations into NLP pipelines, we need datasets with extensive parallel annotations from various social and cultural groups. In this paper we introduce the \dataset dataset: a large-scale cross-cultural dataset of parallel annotations for offensive language in over 4.5K sentences annotated by a pool of over 4k annotators, balanced across gender and age, from across 21 countries, representing eight geo-cultural regions. The dataset contains annotators' moral values captured along six moral foundations: care, equality, proportionality, authority, loyalty, and purity. Our analyses reveal substantial regional variations in annotators' perceptions that are shaped by individual moral values, offering crucial insights for building pluralistic, culturally sensitive NLP models.
GeniL: A Multilingual Dataset on Generalizing Language
Apr 08, 2024



LLMs are increasingly transforming our digital ecosystem, but they often inherit societal biases learned from their training data, for instance stereotypes associating certain attributes with specific identity groups. While whether and how these biases are mitigated may depend on the specific use cases, being able to effectively detect instances of stereotype perpetuation is a crucial first step. Current methods to assess presence of stereotypes in generated language rely on simple template or co-occurrence based measures, without accounting for the variety of sentential contexts they manifest in. We argue that understanding the sentential context is crucial for detecting instances of generalization. We distinguish two types of generalizations: (1) language that merely mentions the presence of a generalization ("people think the French are very rude"), and (2) language that reinforces such a generalization ("as French they must be rude"), from non-generalizing context ("My French friends think I am rude"). For meaningful stereotype evaluations, we need to reliably distinguish such instances of generalizations. We introduce the new task of detecting generalization in language, and build GeniL, a multilingual dataset of over 50K sentences from 9 languages (English, Arabic, Bengali, Spanish, French, Hindi, Indonesian, Malay, and Portuguese) annotated for instances of generalizations. We demonstrate that the likelihood of a co-occurrence being an instance of generalization is usually low, and varies across different languages, identity groups, and attributes. We build classifiers to detect generalization in language with an overall PR-AUC of 58.7, with varying degrees of performance across languages. Our research provides data and tools to enable a nuanced understanding of stereotype perpetuation, a crucial step towards more inclusive and responsible language technologies.
The Moral Foundations Reddit Corpus
Aug 18, 2022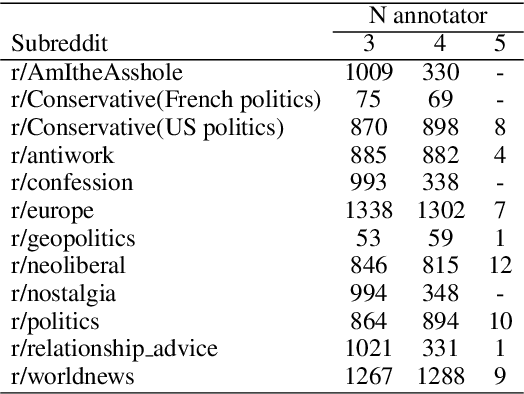
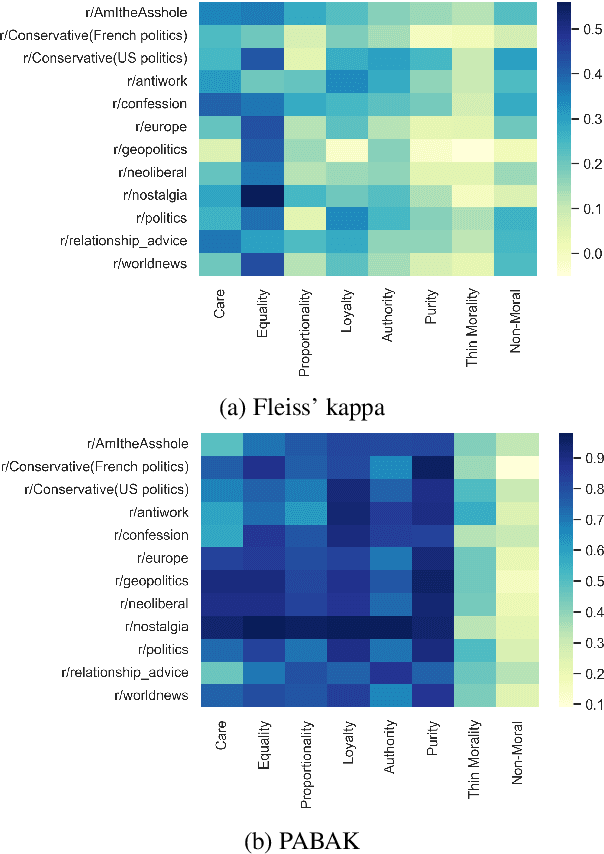
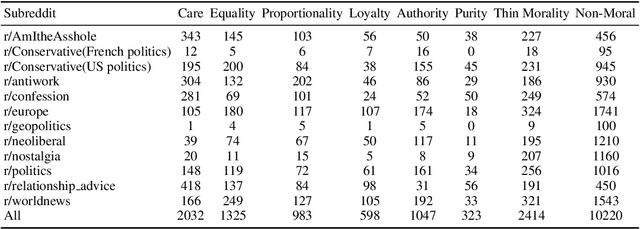
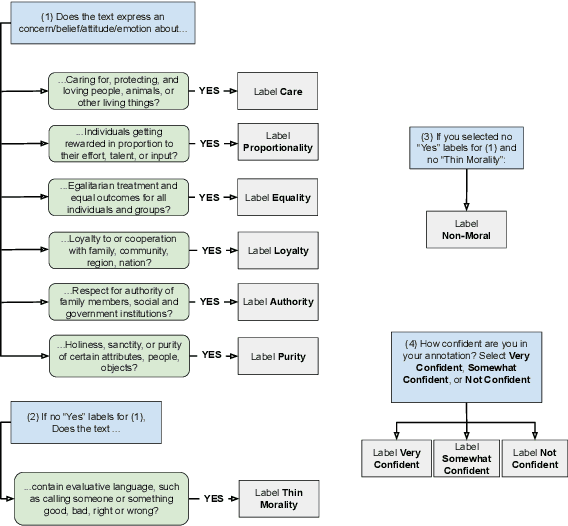
Moral framing and sentiment can affect a variety of online and offline behaviors, including donation, pro-environmental action, political engagement, and even participation in violent protests. Various computational methods in Natural Language Processing (NLP) have been used to detect moral sentiment from textual data, but in order to achieve better performances in such subjective tasks, large sets of hand-annotated training data are needed. Previous corpora annotated for moral sentiment have proven valuable, and have generated new insights both within NLP and across the social sciences, but have been limited to Twitter. To facilitate improving our understanding of the role of moral rhetoric, we present the Moral Foundations Reddit Corpus, a collection of 16,123 Reddit comments that have been curated from 12 distinct subreddits, hand-annotated by at least three trained annotators for 8 categories of moral sentiment (i.e., Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, Implicit/Explicit Morality) based on the updated Moral Foundations Theory (MFT) framework. We use a range of methodologies to provide baseline moral-sentiment classification results for this new corpus, e.g., cross-domain classification and knowledge transfer.
Hate Speech Classifiers Learn Human-Like Social Stereotypes
Oct 28, 2021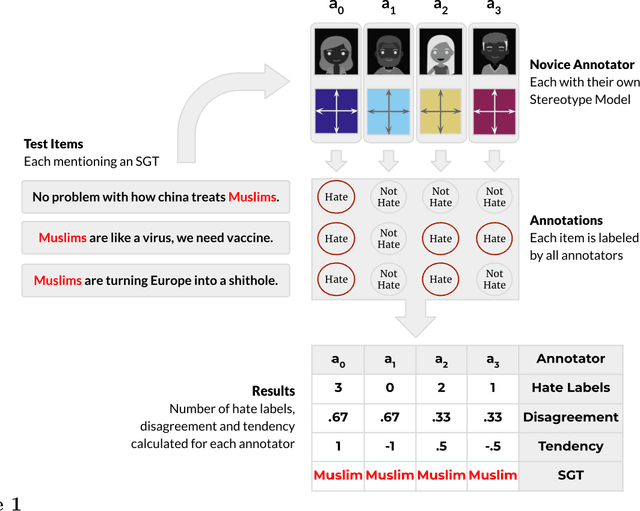
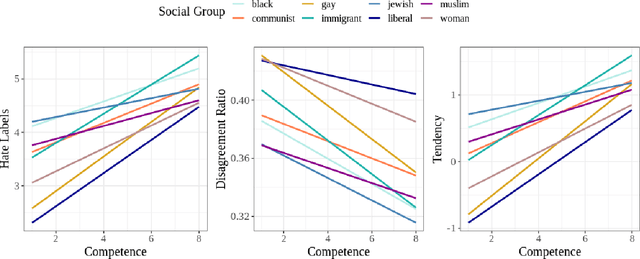

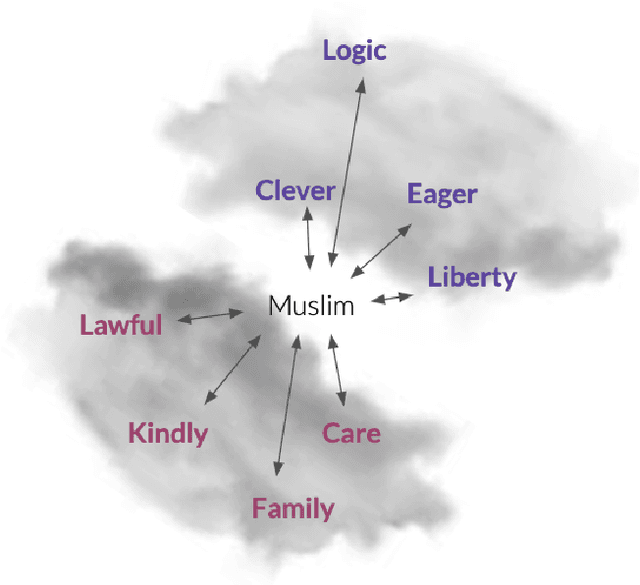
Social stereotypes negatively impact individuals' judgements about different groups and may have a critical role in how people understand language directed toward minority social groups. Here, we assess the role of social stereotypes in the automated detection of hateful language by examining the relation between individual annotator biases and erroneous classification of texts by hate speech classifiers. Specifically, in Study 1 we investigate the impact of novice annotators' stereotypes on their hate-speech-annotation behavior. In Study 2 we examine the effect of language-embedded stereotypes on expert annotators' aggregated judgements in a large annotated corpus. Finally, in Study 3 we demonstrate how language-embedded stereotypes are associated with systematic prediction errors in a neural-network hate speech classifier. Our results demonstrate that hate speech classifiers learn human-like biases which can further perpetuate social inequalities when propagated at scale. This framework, combining social psychological and computational linguistic methods, provides insights into additional sources of bias in hate speech moderation, informing ongoing debates regarding fairness in machine learning.
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
Oct 12, 2021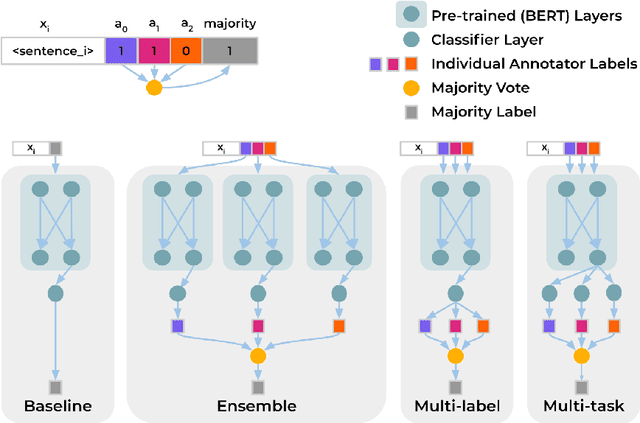

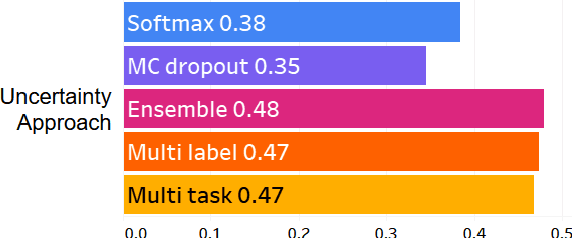

Majority voting and averaging are common approaches employed to resolve annotator disagreements and derive single ground truth labels from multiple annotations. However, annotators may systematically disagree with one another, often reflecting their individual biases and values, especially in the case of subjective tasks such as detecting affect, aggression, and hate speech. Annotator disagreements may capture important nuances in such tasks that are often ignored while aggregating annotations to a single ground truth. In order to address this, we investigate the efficacy of multi-annotator models. In particular, our multi-task based approach treats predicting each annotators' judgements as separate subtasks, while sharing a common learned representation of the task. We show that this approach yields same or better performance than aggregating labels in the data prior to training across seven different binary classification tasks. Our approach also provides a way to estimate uncertainty in predictions, which we demonstrate better correlate with annotation disagreements than traditional methods. Being able to model uncertainty is especially useful in deployment scenarios where knowing when not to make a prediction is important.
On Releasing Annotator-Level Labels and Information in Datasets
Oct 12, 2021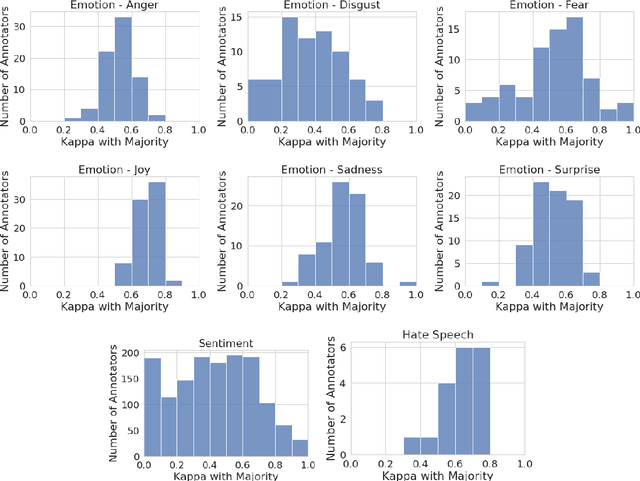
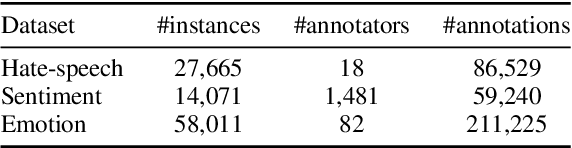

A common practice in building NLP datasets, especially using crowd-sourced annotations, involves obtaining multiple annotator judgements on the same data instances, which are then flattened to produce a single "ground truth" label or score, through majority voting, averaging, or adjudication. While these approaches may be appropriate in certain annotation tasks, such aggregations overlook the socially constructed nature of human perceptions that annotations for relatively more subjective tasks are meant to capture. In particular, systematic disagreements between annotators owing to their socio-cultural backgrounds and/or lived experiences are often obfuscated through such aggregations. In this paper, we empirically demonstrate that label aggregation may introduce representational biases of individual and group perspectives. Based on this finding, we propose a set of recommendations for increased utility and transparency of datasets for downstream use cases.
Improving Counterfactual Generation for Fair Hate Speech Detection
Aug 03, 2021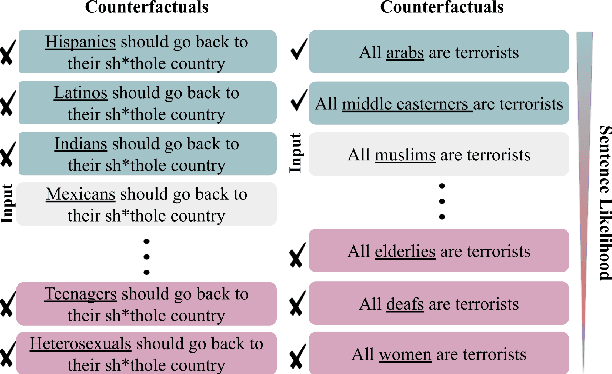


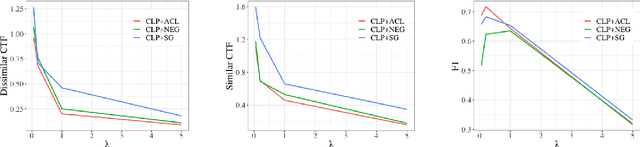
Bias mitigation approaches reduce models' dependence on sensitive features of data, such as social group tokens (SGTs), resulting in equal predictions across the sensitive features. In hate speech detection, however, equalizing model predictions may ignore important differences among targeted social groups, as hate speech can contain stereotypical language specific to each SGT. Here, to take the specific language about each SGT into account, we rely on counterfactual fairness and equalize predictions among counterfactuals, generated by changing the SGTs. Our method evaluates the similarity in sentence likelihoods (via pre-trained language models) among counterfactuals, to treat SGTs equally only within interchangeable contexts. By applying logit pairing to equalize outcomes on the restricted set of counterfactuals for each instance, we improve fairness metrics while preserving model performance on hate speech detection.
Efficiently Mitigating Classification Bias via Transfer Learning
Oct 24, 2020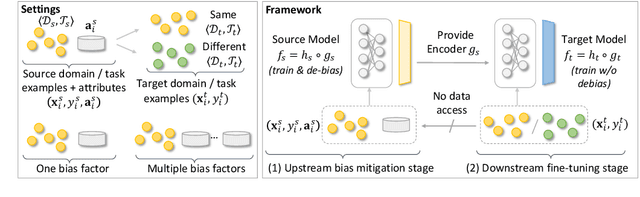
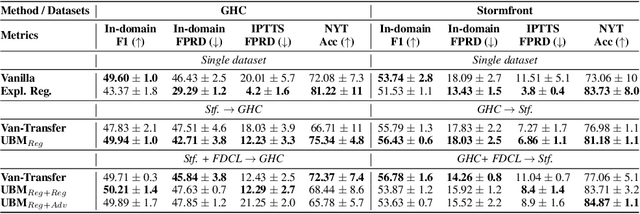
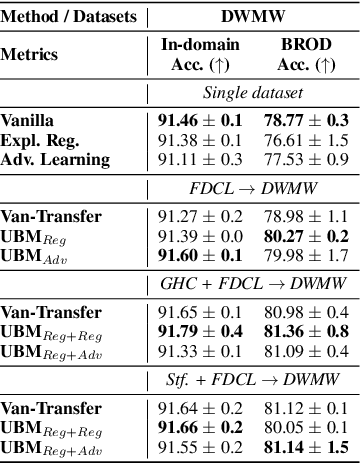
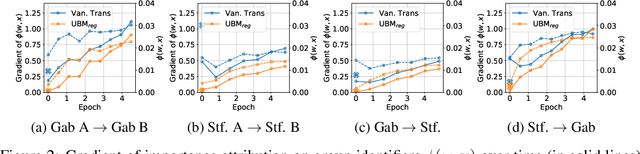
Prediction bias in machine learning models refers to unintended model behaviors that discriminate against inputs mentioning or produced by certain groups; for example, hate speech classifiers predict more false positives for neutral text mentioning specific social groups. Mitigating bias for each task or domain is inefficient, as it requires repetitive model training, data annotation (e.g., demographic information), and evaluation. In pursuit of a more accessible solution, we propose the Upstream Bias Mitigation for Downstream Fine-Tuning (UBM) framework, which mitigate one or multiple bias factors in downstream classifiers by transfer learning from an upstream model. In the upstream bias mitigation stage, explanation regularization and adversarial training are applied to mitigate multiple bias factors. In the downstream fine-tuning stage, the classifier layer of the model is re-initialized, and the entire model is fine-tuned to downstream tasks in potentially novel domains without any further bias mitigation. We expect downstream classifiers to be less biased by transfer learning from de-biased upstream models. We conduct extensive experiments varying the similarity between the source and target data, as well as varying the number of dimensions of bias (e.g., discrimination against specific social groups or dialects). Our results indicate the proposed UBM framework can effectively reduce bias in downstream classifiers.
Fair Hate Speech Detection through Evaluation of Social Group Counterfactuals
Oct 24, 2020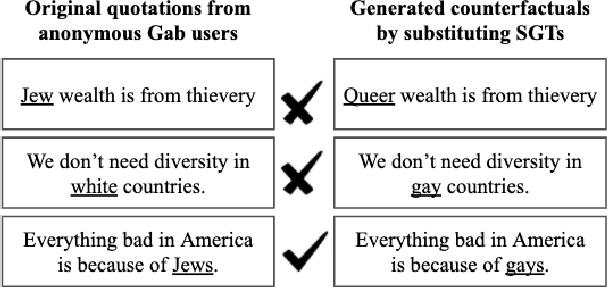
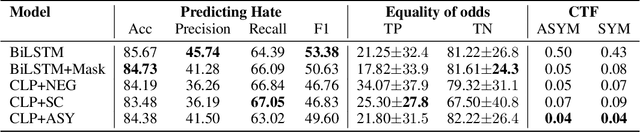
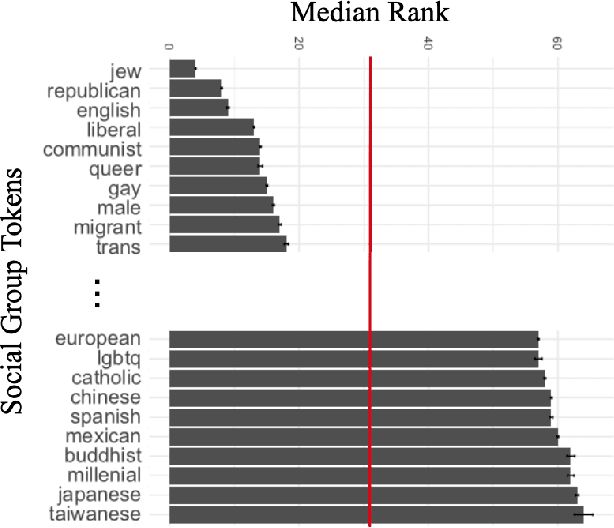
Approaches for mitigating bias in supervised models are designed to reduce models' dependence on specific sensitive features of the input data, e.g., mentioned social groups. However, in the case of hate speech detection, it is not always desirable to equalize the effects of social groups because of their essential role in distinguishing outgroup-derogatory hate, such that particular types of hateful rhetoric carry the intended meaning only when contextualized around certain social group tokens. Counterfactual token fairness for a mentioned social group evaluates the model's predictions as to whether they are the same for (a) the actual sentence and (b) a counterfactual instance, which is generated by changing the mentioned social group in the sentence. Our approach assures robust model predictions for counterfactuals that imply similar meaning as the actual sentence. To quantify the similarity of a sentence and its counterfactual, we compare their likelihood score calculated by generative language models. By equalizing model behaviors on each sentence and its counterfactuals, we mitigate bias in the proposed model while preserving the overall classification performance.