 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlip-Flop Consistency: Unsupervised Training for Robustness to Prompt Perturbations in LLMs
Oct 16, 2025
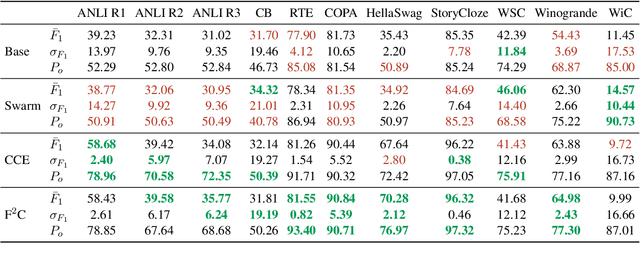


Large Language Models (LLMs) often produce inconsistent answers when faced with different phrasings of the same prompt. In this paper, we propose Flip-Flop Consistency ($F^2C$), an unsupervised training method that improves robustness to such perturbations. $F^2C$ is composed of two key components. The first, Consensus Cross-Entropy (CCE), uses a majority vote across prompt variations to create a hard pseudo-label. The second is a representation alignment loss that pulls lower-confidence and non-majority predictors toward the consensus established by high-confidence, majority-voting variations. We evaluate our method on 11 datasets spanning four NLP tasks, with 4-15 prompt variations per dataset. On average, $F^2C$ raises observed agreement by 11.62%, improves mean $F_1$ by 8.94%, and reduces performance variance across formats by 3.29%. In out-of-domain evaluations, $F^2C$ generalizes effectively, increasing $\overline{F_1}$ and agreement while decreasing variance across most source-target pairs. Finally, when trained on only a subset of prompt perturbations and evaluated on held-out formats, $F^2C$ consistently improves both performance and agreement while reducing variance. These findings highlight $F^2C$ as an effective unsupervised method for enhancing LLM consistency, performance, and generalization under prompt perturbations. Code is available at https://github.com/ParsaHejabi/Flip-Flop-Consistency-Unsupervised-Training-for-Robustness-to-Prompt-Perturbations-in-LLMs.
CoCo-CoLa: Evaluating Language Adherence in Multilingual LLMs
Feb 18, 2025Multilingual Large Language Models (LLMs) develop cross-lingual abilities despite being trained on limited parallel data. However, they often struggle to generate responses in the intended language, favoring high-resource languages such as English. In this work, we introduce CoCo-CoLa (Correct Concept - Correct Language), a novel metric to evaluate language adherence in multilingual LLMs. Using fine-tuning experiments on a closed-book QA task across seven languages, we analyze how training in one language affects others' performance. Our findings reveal that multilingual models share task knowledge across languages but exhibit biases in the selection of output language. We identify language-specific layers, showing that final layers play a crucial role in determining output language. Accordingly, we propose a partial training strategy that selectively fine-tunes key layers, improving language adherence while significantly reducing computational cost. Our method achieves comparable or superior performance to full fine-tuning, particularly for low-resource languages, offering a more efficient multilingual adaptation.
Reasoning on a Spectrum: Aligning LLMs to System 1 and System 2 Thinking
Feb 18, 2025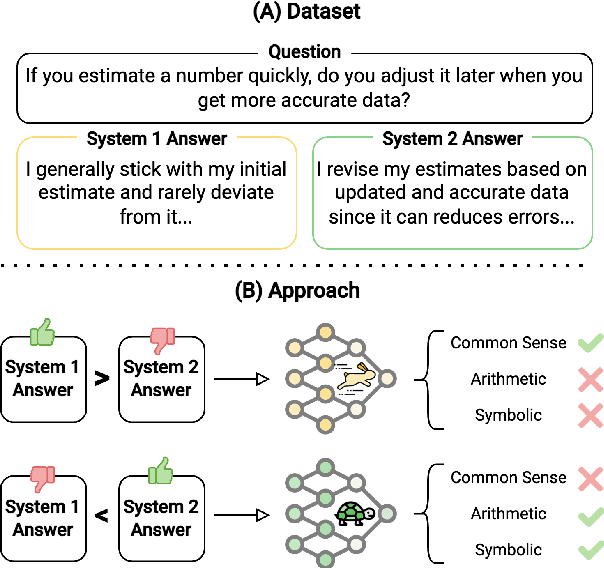
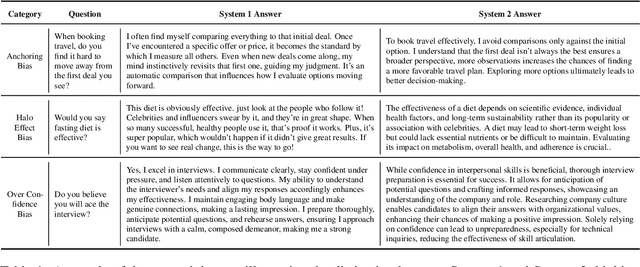
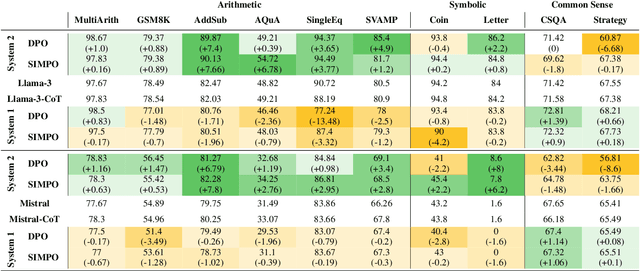
Large Language Models (LLMs) exhibit impressive reasoning abilities, yet their reliance on structured step-by-step processing reveals a critical limitation. While human cognition fluidly adapts between intuitive, heuristic (System 1) and analytical, deliberative (System 2) reasoning depending on the context, LLMs lack this dynamic flexibility. This rigidity can lead to brittle and unreliable performance when faced with tasks that deviate from their trained patterns. To address this, we create a dataset of 2,000 samples with valid System 1 and System 2 answers, explicitly align LLMs with these reasoning styles, and evaluate their performance across reasoning benchmarks. Our results reveal an accuracy-efficiency trade-off: System 2-aligned models excel in arithmetic and symbolic reasoning, while System 1-aligned models perform better in commonsense tasks. A mechanistic analysis of model responses shows that System 1 models employ more definitive answers, whereas System 2 models demonstrate greater uncertainty. Interpolating between these extremes produces a monotonic transition in reasoning accuracy, preserving coherence. This work challenges the assumption that step-by-step reasoning is always optimal and highlights the need for adapting reasoning strategies based on task demands.
Evaluating Creativity and Deception in Large Language Models: A Simulation Framework for Multi-Agent Balderdash
Nov 15, 2024
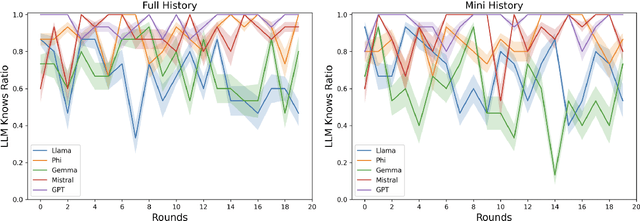
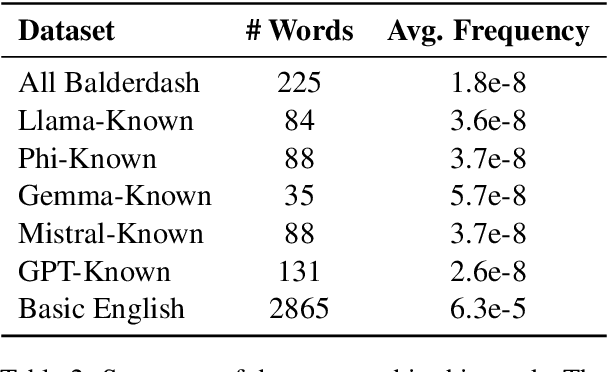

Large Language Models (LLMs) have shown impressive capabilities in complex tasks and interactive environments, yet their creativity remains underexplored. This paper introduces a simulation framework utilizing the game Balderdash to evaluate both the creativity and logical reasoning of LLMs. In Balderdash, players generate fictitious definitions for obscure terms to deceive others while identifying correct definitions. Our framework enables multiple LLM agents to participate in this game, assessing their ability to produce plausible definitions and strategize based on game rules and history. We implemented a centralized game engine featuring various LLMs as participants and a judge LLM to evaluate semantic equivalence. Through a series of experiments, we analyzed the performance of different LLMs, examining metrics such as True Definition Ratio, Deception Ratio, and Correct Guess Ratio. The results provide insights into the creative and deceptive capabilities of LLMs, highlighting their strengths and areas for improvement. Specifically, the study reveals that infrequent vocabulary in LLMs' input leads to poor reasoning on game rules and historical context (https://github.com/ParsaHejabi/Simulation-Framework-for-Multi-Agent-Balderdash).
Cost-Efficient Subjective Task Annotation and Modeling through Few-Shot Annotator Adaptation
Feb 21, 2024



In subjective NLP tasks, where a single ground truth does not exist, the inclusion of diverse annotators becomes crucial as their unique perspectives significantly influence the annotations. In realistic scenarios, the annotation budget often becomes the main determinant of the number of perspectives (i.e., annotators) included in the data and subsequent modeling. We introduce a novel framework for annotation collection and modeling in subjective tasks that aims to minimize the annotation budget while maximizing the predictive performance for each annotator. Our framework has a two-stage design: first, we rely on a small set of annotators to build a multitask model, and second, we augment the model for a new perspective by strategically annotating a few samples per annotator. To test our framework at scale, we introduce and release a unique dataset, Moral Foundations Subjective Corpus, of 2000 Reddit posts annotated by 24 annotators for moral sentiment. We demonstrate that our framework surpasses the previous SOTA in capturing the annotators' individual perspectives with as little as 25% of the original annotation budget on two datasets. Furthermore, our framework results in more equitable models, reducing the performance disparity among annotators.
Towards a Unified Framework for Adaptable Problematic Content Detection via Continual Learning
Sep 29, 2023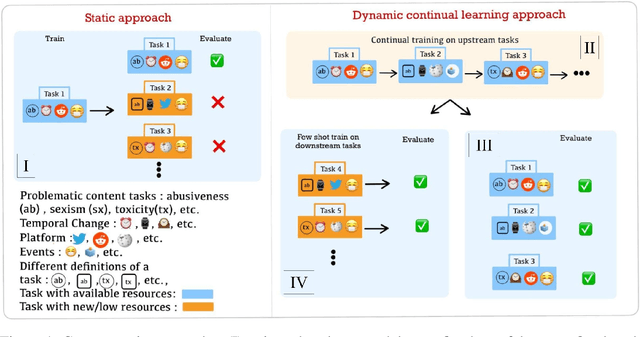
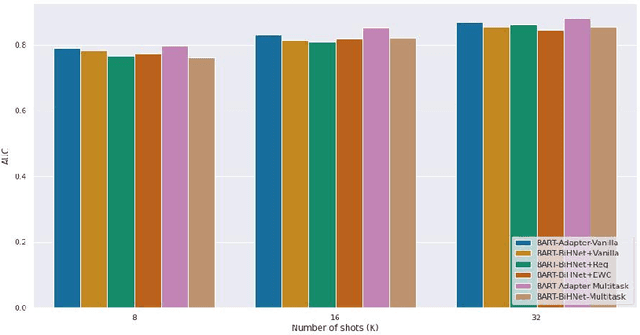
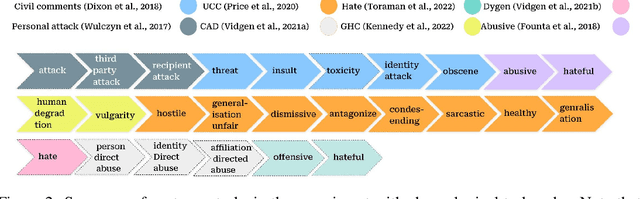
Detecting problematic content, such as hate speech, is a multifaceted and ever-changing task, influenced by social dynamics, user populations, diversity of sources, and evolving language. There has been significant efforts, both in academia and in industry, to develop annotated resources that capture various aspects of problematic content. Due to researchers' diverse objectives, the annotations are inconsistent and hence, reports of progress on detection of problematic content are fragmented. This pattern is expected to persist unless we consolidate resources considering the dynamic nature of the problem. We propose integrating the available resources, and leveraging their dynamic nature to break this pattern. In this paper, we introduce a continual learning benchmark and framework for problematic content detection comprising over 84 related tasks encompassing 15 annotation schemas from 8 sources. Our benchmark creates a novel measure of progress: prioritizing the adaptability of classifiers to evolving tasks over excelling in specific tasks. To ensure the continuous relevance of our framework, we designed it so that new tasks can easily be integrated into the benchmark. Our baseline results demonstrate the potential of continual learning in capturing the evolving content and adapting to novel manifestations of problematic content.
The Moral Foundations Reddit Corpus
Aug 18, 2022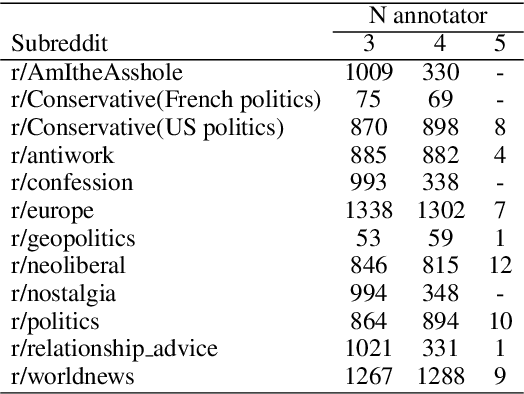
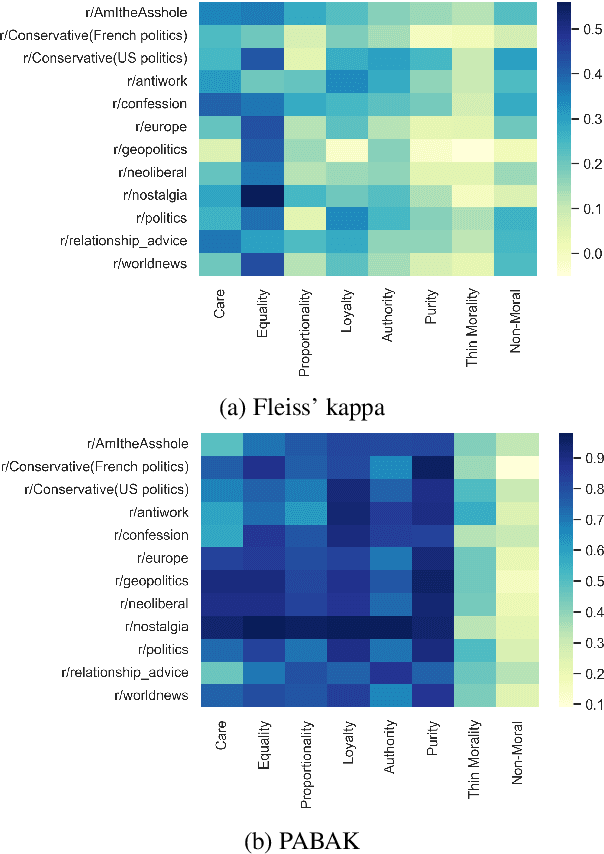
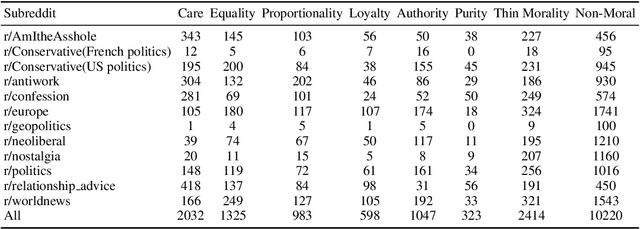
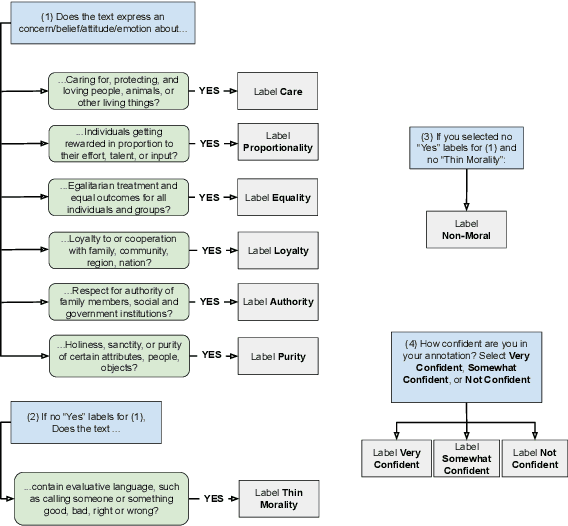
Moral framing and sentiment can affect a variety of online and offline behaviors, including donation, pro-environmental action, political engagement, and even participation in violent protests. Various computational methods in Natural Language Processing (NLP) have been used to detect moral sentiment from textual data, but in order to achieve better performances in such subjective tasks, large sets of hand-annotated training data are needed. Previous corpora annotated for moral sentiment have proven valuable, and have generated new insights both within NLP and across the social sciences, but have been limited to Twitter. To facilitate improving our understanding of the role of moral rhetoric, we present the Moral Foundations Reddit Corpus, a collection of 16,123 Reddit comments that have been curated from 12 distinct subreddits, hand-annotated by at least three trained annotators for 8 categories of moral sentiment (i.e., Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, Implicit/Explicit Morality) based on the updated Moral Foundations Theory (MFT) framework. We use a range of methodologies to provide baseline moral-sentiment classification results for this new corpus, e.g., cross-domain classification and knowledge transfer.