 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Framework for Adaptable Problematic Content Detection via Continual Learning
Sep 29, 2023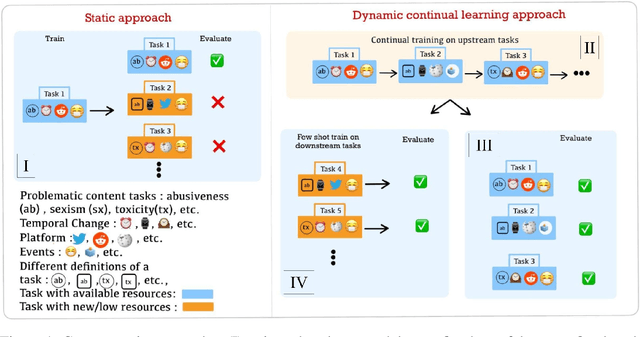
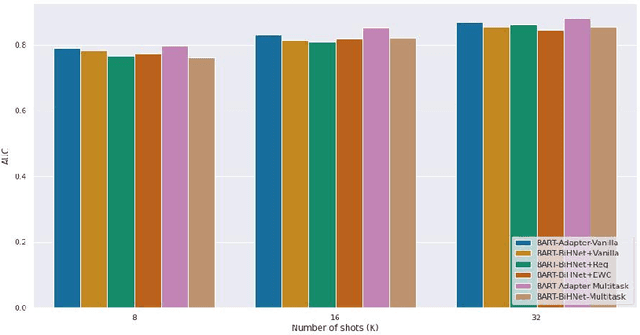
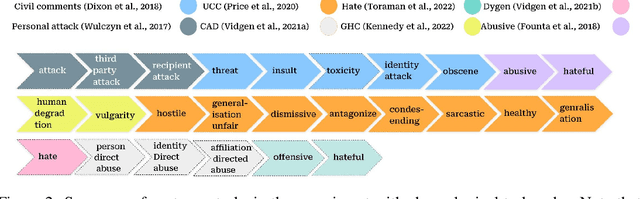
Detecting problematic content, such as hate speech, is a multifaceted and ever-changing task, influenced by social dynamics, user populations, diversity of sources, and evolving language. There has been significant efforts, both in academia and in industry, to develop annotated resources that capture various aspects of problematic content. Due to researchers' diverse objectives, the annotations are inconsistent and hence, reports of progress on detection of problematic content are fragmented. This pattern is expected to persist unless we consolidate resources considering the dynamic nature of the problem. We propose integrating the available resources, and leveraging their dynamic nature to break this pattern. In this paper, we introduce a continual learning benchmark and framework for problematic content detection comprising over 84 related tasks encompassing 15 annotation schemas from 8 sources. Our benchmark creates a novel measure of progress: prioritizing the adaptability of classifiers to evolving tasks over excelling in specific tasks. To ensure the continuous relevance of our framework, we designed it so that new tasks can easily be integrated into the benchmark. Our baseline results demonstrate the potential of continual learning in capturing the evolving content and adapting to novel manifestations of problematic content.
WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community
Oct 31, 2018
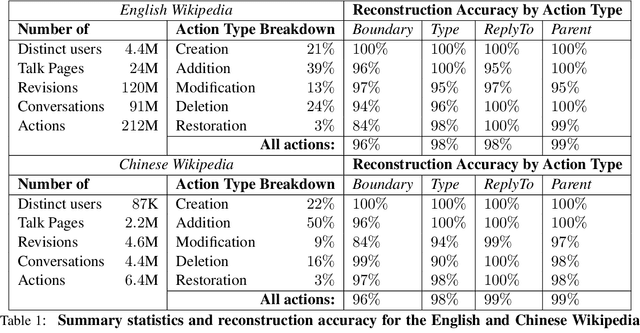

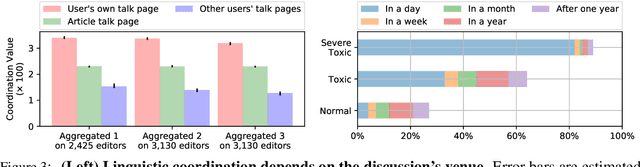
We present a corpus that encompasses the complete history of conversations between contributors to Wikipedia, one of the largest online collaborative communities. By recording the intermediate states of conversations---including not only comments and replies, but also their modifications, deletions and restorations---this data offers an unprecedented view of online conversation. This level of detail supports new research questions pertaining to the process (and challenges) of large-scale online collaboration. We illustrate the corpus' potential with two case studies that highlight new perspectives on earlier work. First, we explore how a person's conversational behavior depends on how they relate to the discussion's venue. Second, we show that community moderation of toxic behavior happens at a higher rate than previously estimated. Finally the reconstruction framework is designed to be language agnostic, and we show that it can extract high quality conversational data in both Chinese and English.