 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding BERT performance in propaganda analysis
Nov 11, 2019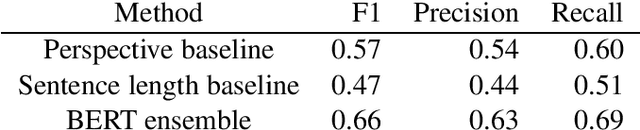

In this paper, we describe our system used in the shared task for fine-grained propaganda analysis at sentence level. Despite the challenging nature of the task, our pretrained BERT model (team YMJA) fine tuned on the training dataset provided by the shared task scored 0.62 F1 on the test set and ranked third among 25 teams who participated in the contest. We present a set of illustrative experiments to better understand the performance of our BERT model on this shared task. Further, we explore beyond the given dataset for false-positive cases that likely to be produced by our system. We show that despite the high performance on the given testset, our system may have the tendency of classifying opinion pieces as propaganda and cannot distinguish quotations of propaganda speech from actual usage of propaganda techniques.
WikiConv: A Corpus of the Complete Conversational History of a Large Online Collaborative Community
Oct 31, 2018
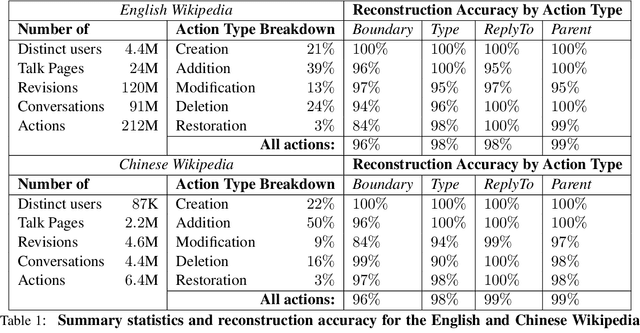

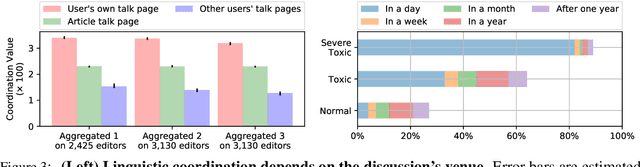
We present a corpus that encompasses the complete history of conversations between contributors to Wikipedia, one of the largest online collaborative communities. By recording the intermediate states of conversations---including not only comments and replies, but also their modifications, deletions and restorations---this data offers an unprecedented view of online conversation. This level of detail supports new research questions pertaining to the process (and challenges) of large-scale online collaboration. We illustrate the corpus' potential with two case studies that highlight new perspectives on earlier work. First, we explore how a person's conversational behavior depends on how they relate to the discussion's venue. Second, we show that community moderation of toxic behavior happens at a higher rate than previously estimated. Finally the reconstruction framework is designed to be language agnostic, and we show that it can extract high quality conversational data in both Chinese and English.
How To Backdoor Federated Learning
Oct 01, 2018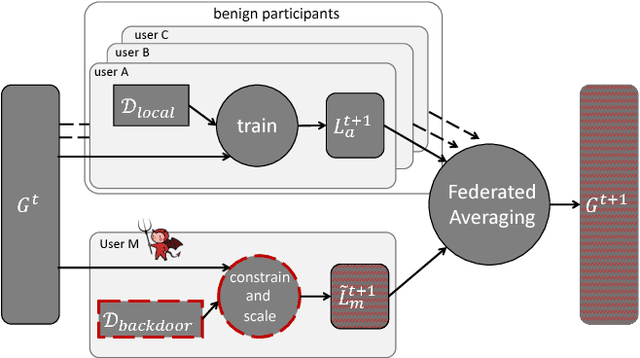
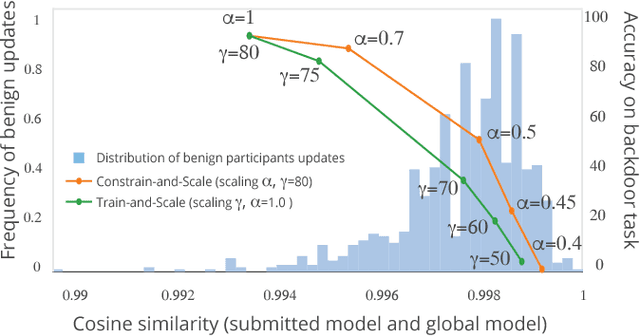
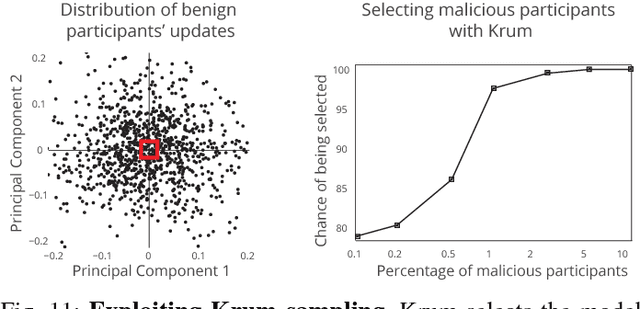
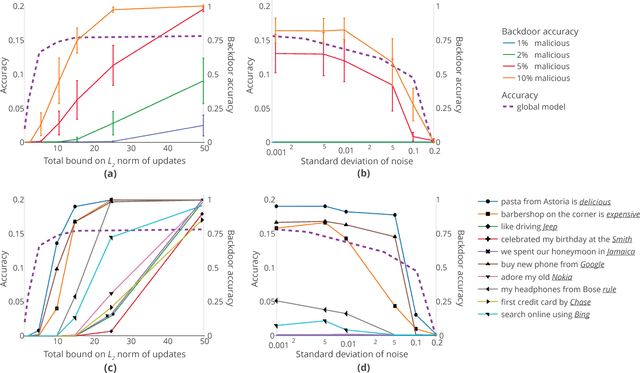
Federated learning enables thousands of participants to construct a deep learning model without sharing their private training data with each other. For example, multiple smartphones can jointly train a next-word predictor for keyboards without revealing what individual users type. We demonstrate that any participant in federated learning can introduce hidden backdoor functionality into the joint global model, e.g., to ensure that an image classifier assigns an attacker-chosen label to images with certain features, or that a word predictor completes certain sentences with an attacker-chosen word. We design and evaluate a new model-poisoning methodology based on model replacement. An attacker selected in a single round of federated learning can cause the global model to immediately reach 100% accuracy on the backdoor task. We evaluate the attack under different assumptions for the standard federated-learning tasks and show that it greatly outperforms data poisoning. Our generic constrain-and-scale technique also evades anomaly detection-based defenses by incorporating the evasion into the attacker's loss function during training.
Conversations Gone Awry: Detecting Early Signs of Conversational Failure
May 14, 2018

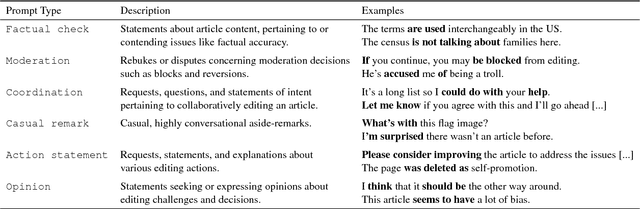
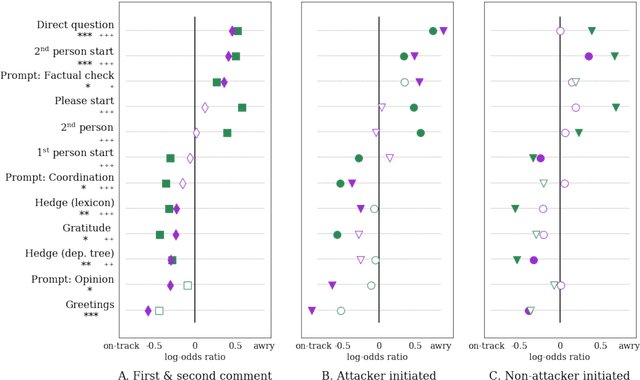
One of the main challenges online social systems face is the prevalence of antisocial behavior, such as harassment and personal attacks. In this work, we introduce the task of predicting from the very start of a conversation whether it will get out of hand. As opposed to detecting undesirable behavior after the fact, this task aims to enable early, actionable prediction at a time when the conversation might still be salvaged. To this end, we develop a framework for capturing pragmatic devices---such as politeness strategies and rhetorical prompts---used to start a conversation, and analyze their relation to its future trajectory. Applying this framework in a controlled setting, we demonstrate the feasibility of detecting early warning signs of antisocial behavior in online discussions.