 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Economic Tradeoffs Between Human and AI Agents in Bargaining Games
Sep 11, 2025Coordination tasks traditionally performed by humans are increasingly being delegated to autonomous agents. As this pattern progresses, it becomes critical to evaluate not only these agents' performance but also the processes through which they negotiate in dynamic, multi-agent environments. Furthermore, different agents exhibit distinct advantages: traditional statistical agents, such as Bayesian models, may excel under well-specified conditions, whereas large language models (LLMs) can generalize across contexts. In this work, we compare humans (N = 216), LLMs (GPT-4o, Gemini 1.5 Pro), and Bayesian agents in a dynamic negotiation setting that enables direct, identical-condition comparisons across populations, capturing both outcomes and behavioral dynamics. Bayesian agents extract the highest surplus through aggressive optimization, at the cost of frequent trade rejections. Humans and LLMs can achieve similar overall surplus, but through distinct behaviors: LLMs favor conservative, concessionary trades with few rejections, while humans employ more strategic, risk-taking, and fairness-oriented behaviors. Thus, we find that performance parity -- a common benchmark in agent evaluation -- can conceal fundamental differences in process and alignment, which are critical for practical deployment in real-world coordination tasks.
Improving Neutral Point of View Text Generation through Parameter-Efficient Reinforcement Learning and a Small-Scale High-Quality Dataset
Mar 05, 2025This paper describes the construction of a dataset and the evaluation of training methods to improve generative large language models' (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e., to provide significantly more informative, diverse and impartial answers. The dataset, the SHQ-NPOV dataset, comprises 300 high-quality, human-written quadruplets: a query on a sensitive topic, an answer, an NPOV rating, and a set of links to source texts elaborating the various points of view. The first key contribution of this paper is a new methodology to create such datasets through iterative rounds of human peer-critique and annotator training, which we release alongside the dataset. The second key contribution is the identification of a highly effective training regime for parameter-efficient reinforcement learning (PE-RL) to improve NPOV generation. We compare and extensively evaluate PE-RL and multiple baselines-including LoRA finetuning (a strong baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06\%\rightarrow 99.08\%$), but also scores much higher on features linguists identify as key to separating good answers from the best answers ($60.25\%\rightarrow 85.21\%$ for presence of supportive details, $68.74\%\rightarrow 91.43\%$ for absence of oversimplification). A qualitative analysis corroborates this. Finally, our evaluation finds no statistical differences between results on topics that appear in the training dataset and those on separated evaluation topics, which provides strong evidence that our approach to training PE-RL exhibits very effective out of topic generalization.
Detecting Hallucination and Coverage Errors in Retrieval Augmented Generation for Controversial Topics
Mar 13, 2024We explore a strategy to handle controversial topics in LLM-based chatbots based on Wikipedia's Neutral Point of View (NPOV) principle: acknowledge the absence of a single true answer and surface multiple perspectives. We frame this as retrieval augmented generation, where perspectives are retrieved from a knowledge base and the LLM is tasked with generating a fluent and faithful response from the given perspectives. As a starting point, we use a deterministic retrieval system and then focus on common LLM failure modes that arise during this approach to text generation, namely hallucination and coverage errors. We propose and evaluate three methods to detect such errors based on (1) word-overlap, (2) salience, and (3) LLM-based classifiers. Our results demonstrate that LLM-based classifiers, even when trained only on synthetic errors, achieve high error detection performance, with ROC AUC scores of 95.3% for hallucination and 90.5% for coverage error detection on unambiguous error cases. We show that when no training data is available, our other methods still yield good results on hallucination (84.0%) and coverage error (85.2%) detection.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
ConstitutionalExperts: Training a Mixture of Principle-based Prompts
Mar 07, 2024



Large language models (LLMs) are highly capable at a variety of tasks given the right prompt, but writing one is still a difficult and tedious process. In this work, we introduce ConstitutionalExperts, a method for learning a prompt consisting of constitutional principles (i.e. rules), given a training dataset. Unlike prior methods that optimize the prompt as a single entity, our method incrementally improves the prompt by surgically editing individual principles. We also show that we can improve overall performance by learning unique prompts for different semantic regions of the training data and using a mixture-of-experts (MoE) architecture to route inputs at inference time. We compare our method to other state of the art prompt-optimization techniques across six benchmark datasets. We also investigate whether MoE improves these other techniques. Our results suggest that ConstitutionalExperts outperforms other prompt optimization techniques by 10.9% (F1) and that mixture-of-experts improves all techniques, suggesting its broad applicability.
Improving Classifier Robustness through Active Generation of Pairwise Counterfactuals
May 22, 2023Counterfactual Data Augmentation (CDA) is a commonly used technique for improving robustness in natural language classifiers. However, one fundamental challenge is how to discover meaningful counterfactuals and efficiently label them, with minimal human labeling cost. Most existing methods either completely rely on human-annotated labels, an expensive process which limits the scale of counterfactual data, or implicitly assume label invariance, which may mislead the model with incorrect labels. In this paper, we present a novel framework that utilizes counterfactual generative models to generate a large number of diverse counterfactuals by actively sampling from regions of uncertainty, and then automatically label them with a learned pairwise classifier. Our key insight is that we can more correctly label the generated counterfactuals by training a pairwise classifier that interpolates the relationship between the original example and the counterfactual. We demonstrate that with a small amount of human-annotated counterfactual data (10%), we can generate a counterfactual augmentation dataset with learned labels, that provides an 18-20% improvement in robustness and a 14-21% reduction in errors on 6 out-of-domain datasets, comparable to that of a fully human-annotated counterfactual dataset for both sentiment classification and question paraphrase tasks.
Towards Agile Text Classifiers for Everyone
Feb 13, 2023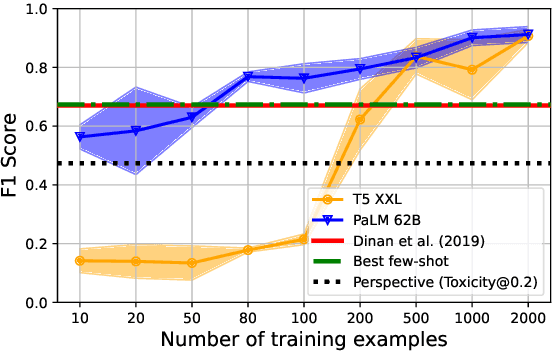
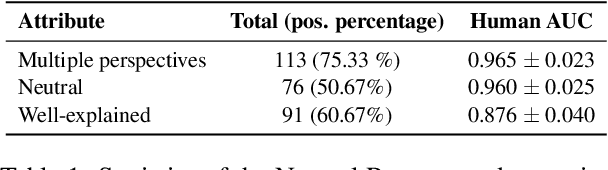
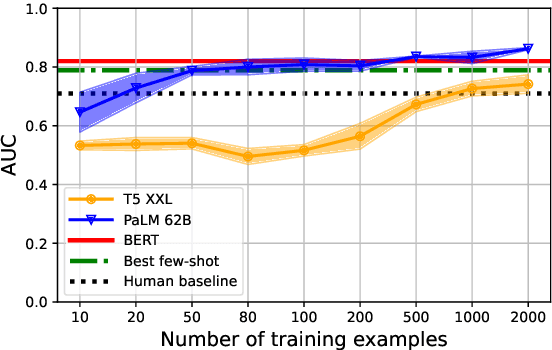
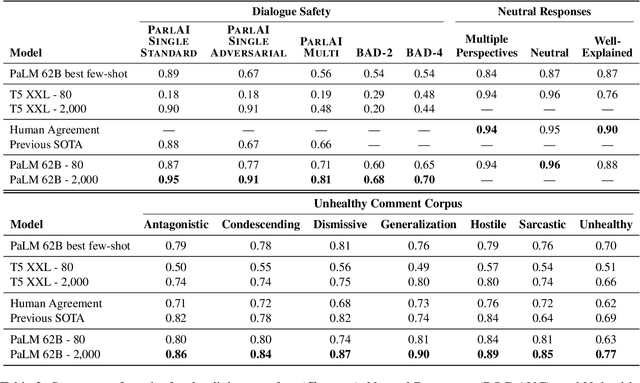
Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
Gradient-Based Automated Iterative Recovery for Parameter-Efficient Tuning
Feb 13, 2023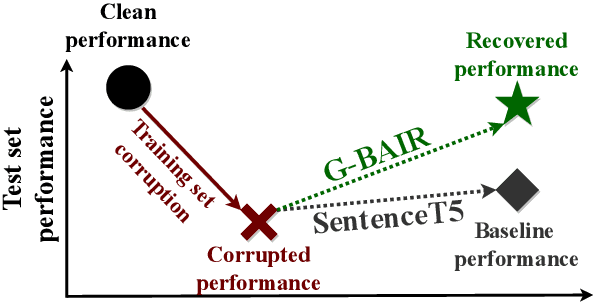

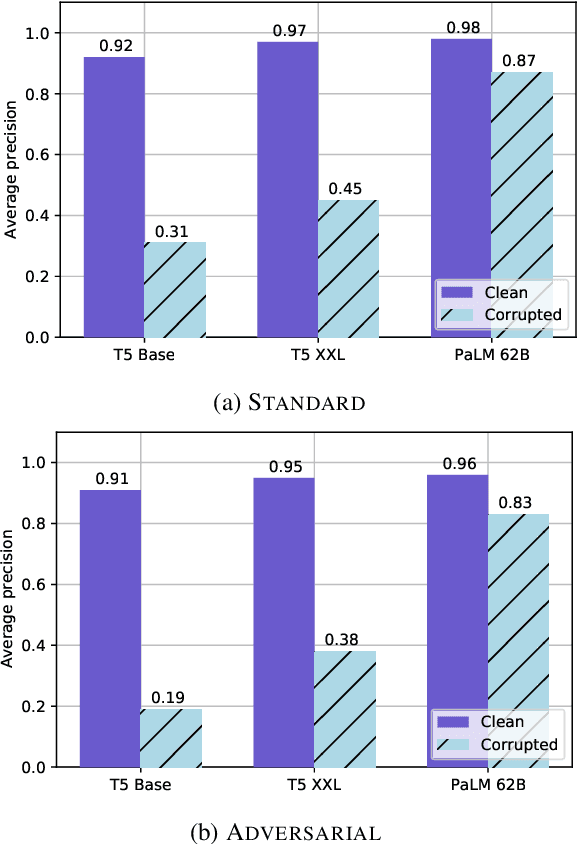
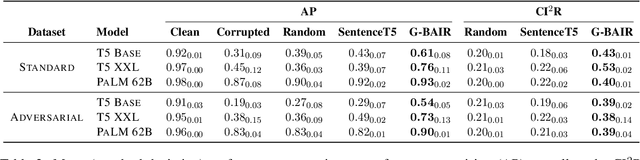
Pretrained large language models (LLMs) are able to solve a wide variety of tasks through transfer learning. Various explainability methods have been developed to investigate their decision making process. TracIn (Pruthi et al., 2020) is one such gradient-based method which explains model inferences based on the influence of training examples. In this paper, we explore the use of TracIn to improve model performance in the parameter-efficient tuning (PET) setting. We develop conversational safety classifiers via the prompt-tuning PET method and show how the unique characteristics of the PET regime enable TracIn to identify the cause for certain misclassifications by LLMs. We develop a new methodology for using gradient-based explainability techniques to improve model performance, G-BAIR: gradient-based automated iterative recovery. We show that G-BAIR can recover LLM performance on benchmarks after manually corrupting training labels. This suggests that influence methods like TracIn can be used to automatically perform data cleaning, and introduces the potential for interactive debugging and relabeling for PET-based transfer learning methods.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022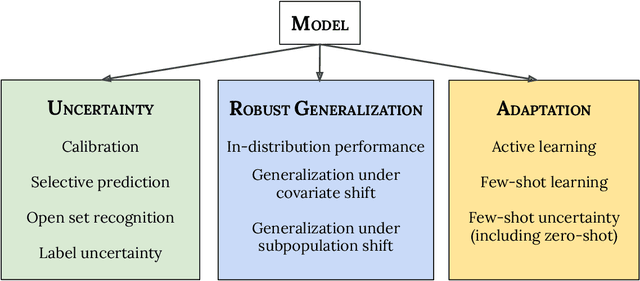

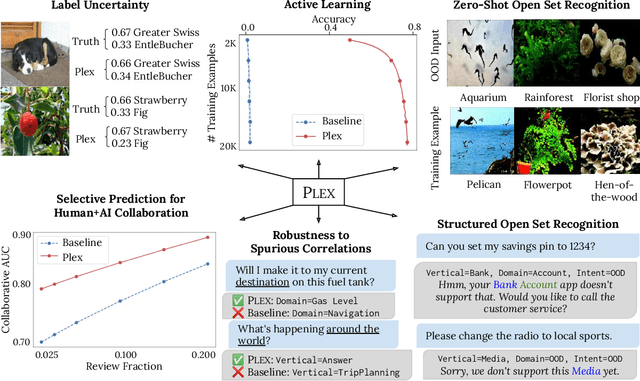

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Measuring Recommender System Effects with Simulated Users
Jan 12, 2021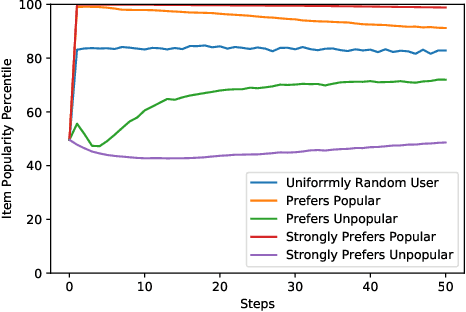

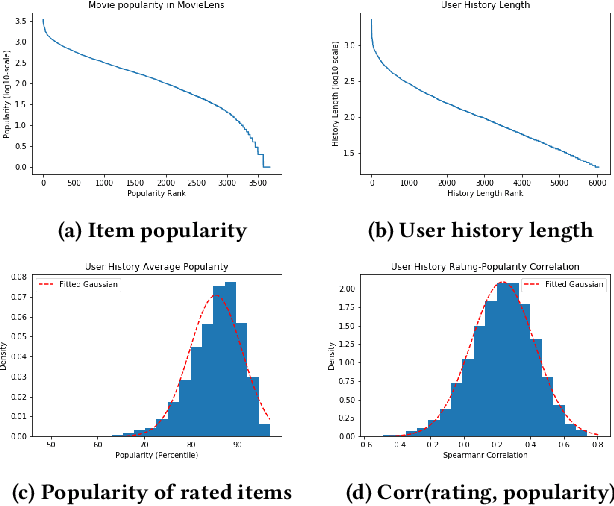
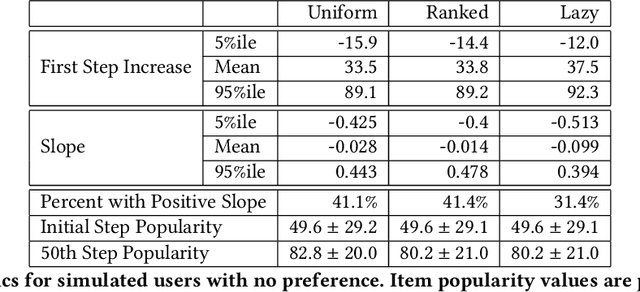
Imagine a food recommender system -- how would we check if it is \emph{causing} and fostering unhealthy eating habits or merely reflecting users' interests? How much of a user's experience over time with a recommender is caused by the recommender system's choices and biases, and how much is based on the user's preferences and biases? Popularity bias and filter bubbles are two of the most well-studied recommender system biases, but most of the prior research has focused on understanding the system behavior in a single recommendation step. How do these biases interplay with user behavior, and what types of user experiences are created from repeated interactions? In this work, we offer a simulation framework for measuring the impact of a recommender system under different types of user behavior. Using this simulation framework, we can (a) isolate the effect of the recommender system from the user preferences, and (b) examine how the system performs not just on average for an "average user" but also the extreme experiences under atypical user behavior. As part of the simulation framework, we propose a set of evaluation metrics over the simulations to understand the recommender system's behavior. Finally, we present two empirical case studies -- one on traditional collaborative filtering in MovieLens and one on a large-scale production recommender system -- to understand how popularity bias manifests over time.