 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Generation of Perspective API: Efficient Multilingual Character-level Transformers
Feb 22, 2022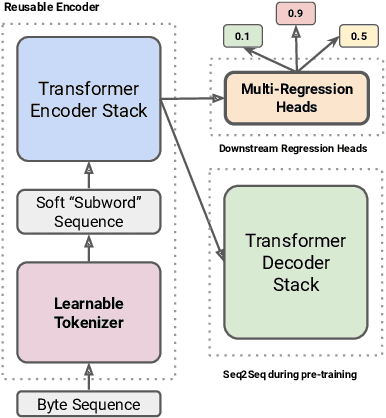
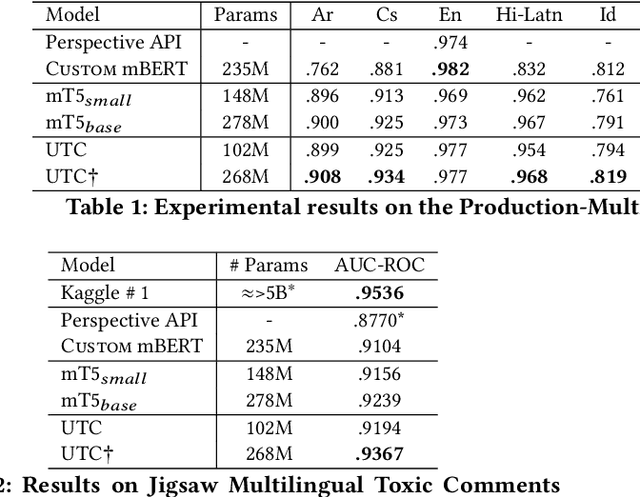
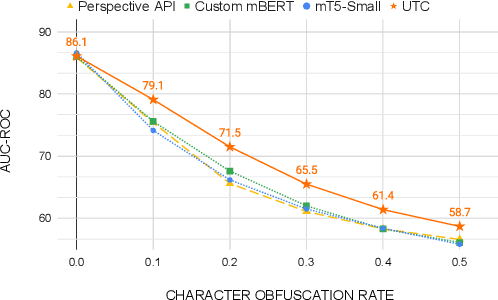
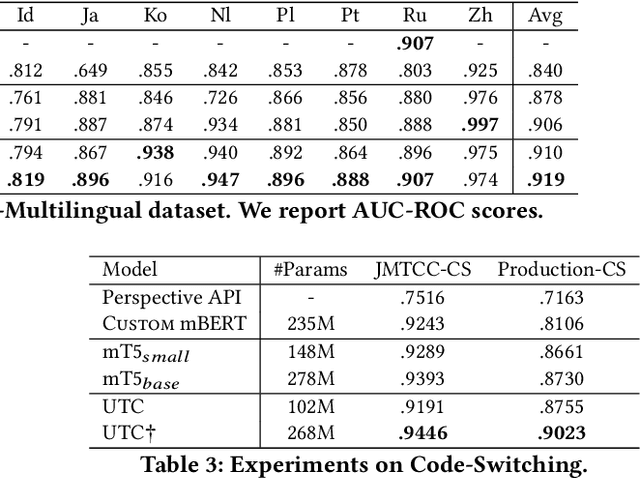
On the world wide web, toxic content detectors are a crucial line of defense against potentially hateful and offensive messages. As such, building highly effective classifiers that enable a safer internet is an important research area. Moreover, the web is a highly multilingual, cross-cultural community that develops its own lingo over time. As such, it is crucial to develop models that are effective across a diverse range of languages, usages, and styles. In this paper, we present the fundamentals behind the next version of the Perspective API from Google Jigsaw. At the heart of the approach is a single multilingual token-free Charformer model that is applicable across a range of languages, domains, and tasks. We demonstrate that by forgoing static vocabularies, we gain flexibility across a variety of settings. We additionally outline the techniques employed to make such a byte-level model efficient and feasible for productionization. Through extensive experiments on multilingual toxic comment classification benchmarks derived from real API traffic and evaluation on an array of code-switching, covert toxicity, emoji-based hate, human-readable obfuscation, distribution shift, and bias evaluation settings, we show that our proposed approach outperforms strong baselines. Finally, we present our findings from deploying this system in production.
Toxicity Detection can be Sensitive to the Conversational Context
Nov 19, 2021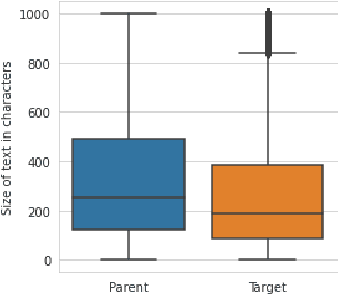

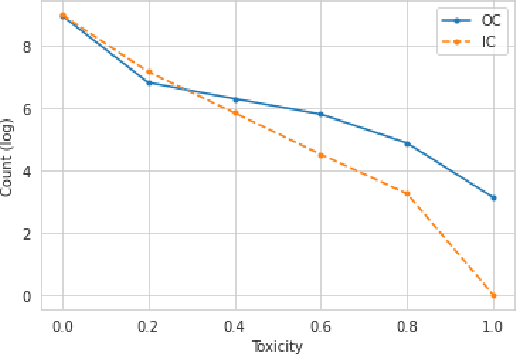
User posts whose perceived toxicity depends on the conversational context are rare in current toxicity detection datasets. Hence, toxicity detectors trained on existing datasets will also tend to disregard context, making the detection of context-sensitive toxicity harder when it does occur. We construct and publicly release a dataset of 10,000 posts with two kinds of toxicity labels: (i) annotators considered each post with the previous one as context; and (ii) annotators had no additional context. Based on this, we introduce a new task, context sensitivity estimation, which aims to identify posts whose perceived toxicity changes if the context (previous post) is also considered. We then evaluate machine learning systems on this task, showing that classifiers of practical quality can be developed, and we show that data augmentation with knowledge distillation can improve the performance further. Such systems could be used to enhance toxicity detection datasets with more context-dependent posts, or to suggest when moderators should consider the parent posts, which often may be unnecessary and may otherwise introduce significant additional cost.
Civil Rephrases Of Toxic Texts With Self-Supervised Transformers
Feb 11, 2021
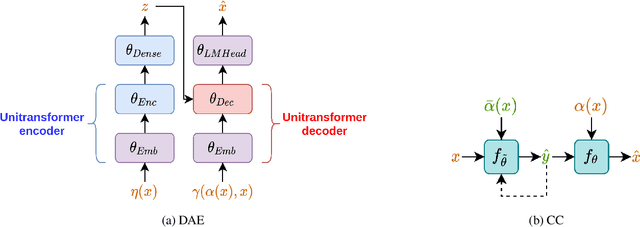
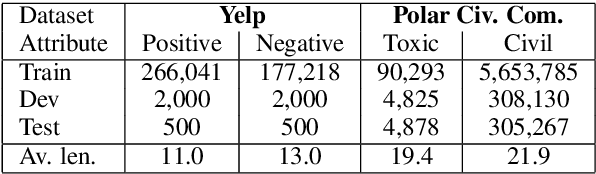
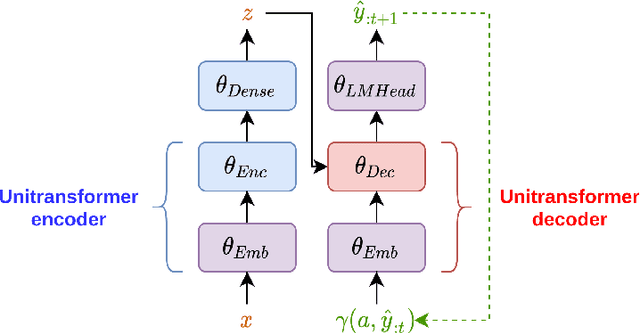
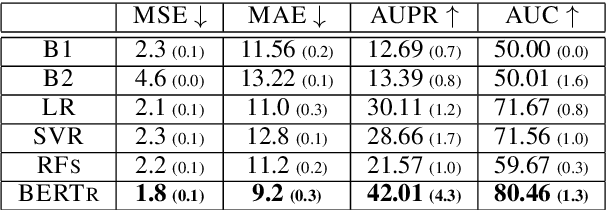
Platforms that support online commentary, from social networks to news sites, are increasingly leveraging machine learning to assist their moderation efforts. But this process does not typically provide feedback to the author that would help them contribute according to the community guidelines. This is prohibitively time-consuming for human moderators to do, and computational approaches are still nascent. This work focuses on models that can help suggest rephrasings of toxic comments in a more civil manner. Inspired by recent progress in unpaired sequence-to-sequence tasks, a self-supervised learning model is introduced, called CAE-T5. CAE-T5 employs a pre-trained text-to-text transformer, which is fine tuned with a denoising and cyclic auto-encoder loss. Experimenting with the largest toxicity detection dataset to date (Civil Comments) our model generates sentences that are more fluent and better at preserving the initial content compared to earlier text style transfer systems which we compare with using several scoring systems and human evaluation.
Six Attributes of Unhealthy Conversation
Oct 14, 2020
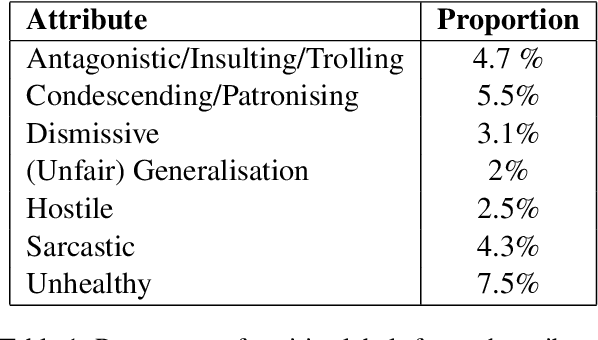
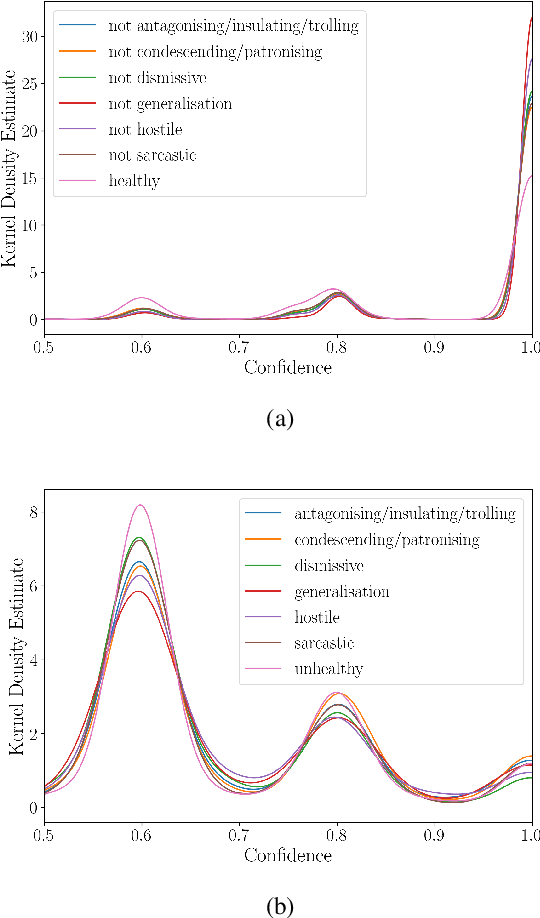

We present a new dataset of approximately 44000 comments labeled by crowdworkers. Each comment is labelled as either 'healthy' or 'unhealthy', in addition to binary labels for the presence of six potentially 'unhealthy' sub-attributes: (1) hostile; (2) antagonistic, insulting, provocative or trolling; (3) dismissive; (4) condescending or patronising; (5) sarcastic; and/or (6) an unfair generalisation. Each label also has an associated confidence score. We argue that there is a need for datasets which enable research based on a broad notion of 'unhealthy online conversation'. We build this typology to encompass a substantial proportion of the individual comments which contribute to unhealthy online conversation. For some of these attributes, this is the first publicly available dataset of this scale. We explore the quality of the dataset, present some summary statistics and initial models to illustrate the utility of this data, and highlight limitations and directions for further research.
Toxicity Detection: Does Context Really Matter?
Jun 01, 2020



Moderation is crucial to promoting healthy on-line discussions. Although several `toxicity' detection datasets and models have been published, most of them ignore the context of the posts, implicitly assuming that comments maybe judged independently. We investigate this assumption by focusing on two questions: (a) does context affect the human judgement, and (b) does conditioning on context improve performance of toxicity detection systems? We experiment with Wikipedia conversations, limiting the notion of context to the previous post in the thread and the discussion title. We find that context can both amplify or mitigate the perceived toxicity of posts. Moreover, a small but significant subset of manually labeled posts (5% in one of our experiments) end up having the opposite toxicity labels if the annotators are not provided with context. Surprisingly, we also find no evidence that context actually improves the performance of toxicity classifiers, having tried a range of classifiers and mechanisms to make them context aware. This points to the need for larger datasets of comments annotated in context. We make our code and data publicly available.
Classifying Constructive Comments
Apr 14, 2020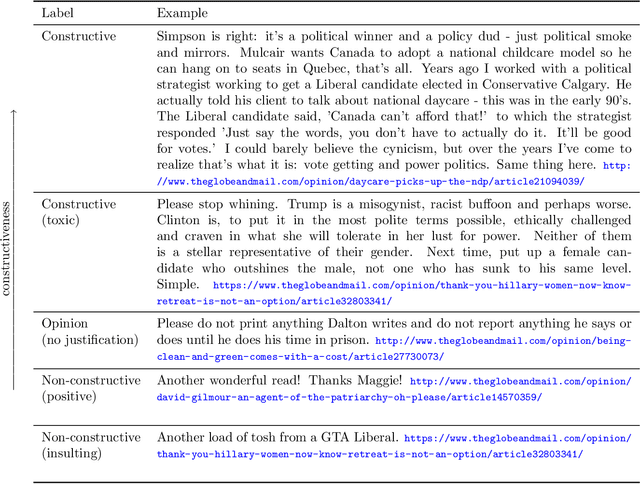
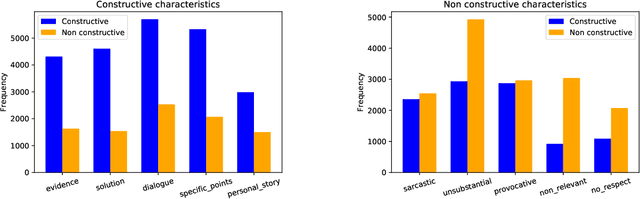
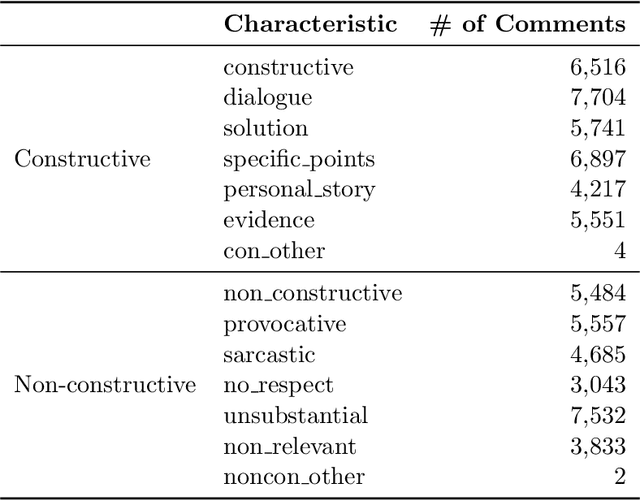

We introduce the Constructive Comments Corpus (C3), comprised of 12,000 annotated news comments, intended to help build new tools for online communities to improve the quality of their discussions. We define constructive comments as high-quality comments that make a contribution to the conversation. We explain the crowd worker annotation scheme and define a taxonomy of sub-characteristics of constructiveness. The quality of the annotation scheme and the resulting dataset is evaluated using measurements of inter-annotator agreement, expert assessment of a sample, and by the constructiveness sub-characteristics, which we show provide a proxy for the general constructiveness concept. We provide models for constructiveness trained on C3 using both feature-based and a variety of deep learning approaches and demonstrate that these models capture general rather than topic- or domain-specific characteristics of constructiveness, through domain adaptation experiments. We examine the role that length plays in our models, as comment length could be easily gamed if models depend heavily upon this feature. By examining the errors made by each model and their distribution by length, we show that the best performing models are less correlated with comment length.The constructiveness corpus and our experiments pave the way for a moderation tool focused on promoting comments that make a contribution, rather than only filtering out undesirable content.
Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification
Mar 11, 2019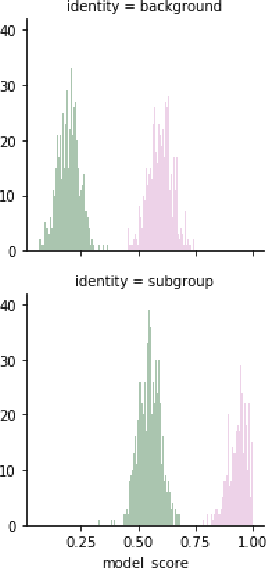
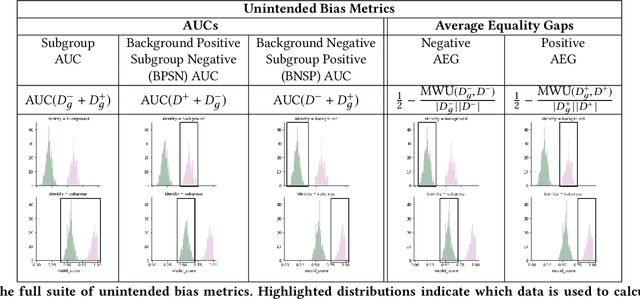
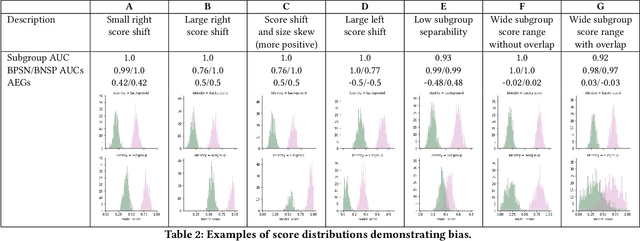
Unintended bias in Machine Learning can manifest as systemic differences in performance for different demographic groups, potentially compounding existing challenges to fairness in society at large. In this paper, we introduce a suite of threshold-agnostic metrics that provide a nuanced view of this unintended bias, by considering the various ways that a classifier's score distribution can vary across designated groups. We also introduce a large new test set of online comments with crowd-sourced annotations for identity references. We use this to show how our metrics can be used to find new and potentially subtle unintended bias in existing public models.
Limitations of Pinned AUC for Measuring Unintended Bias
Mar 05, 2019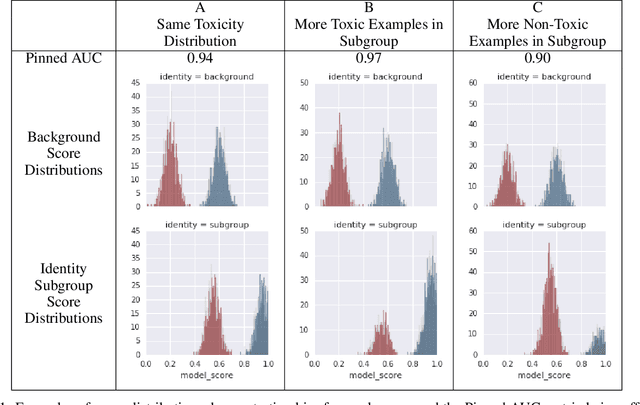
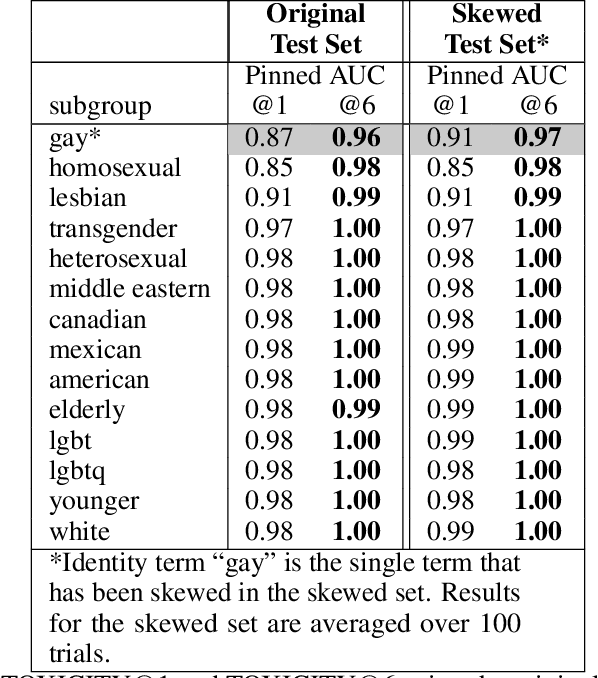
This report examines the Pinned AUC metric introduced and highlights some of its limitations. Pinned AUC provides a threshold-agnostic measure of unintended bias in a classification model, inspired by the ROC-AUC metric. However, as we highlight in this report, there are ways that the metric can obscure different kinds of unintended biases when the underlying class distributions on which bias is being measured are not carefully controlled.