 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Generation of Perspective API: Efficient Multilingual Character-level Transformers
Paper and Code
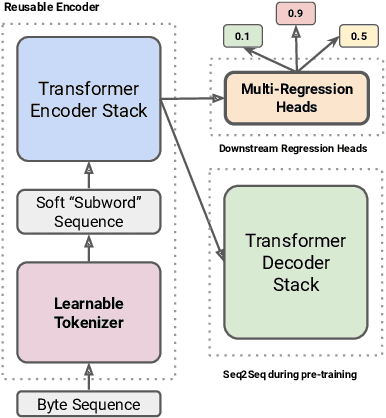
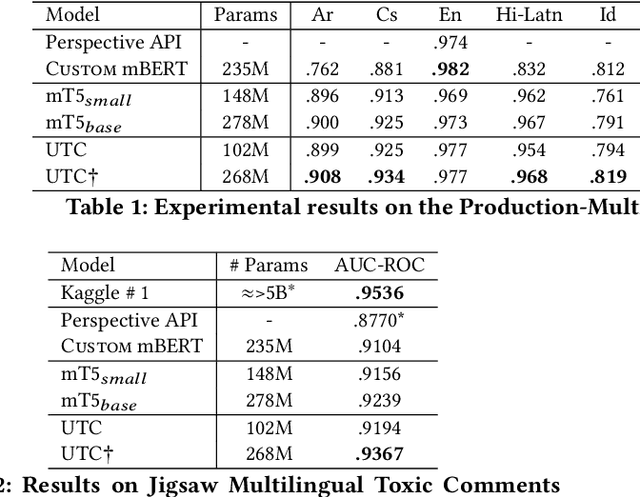
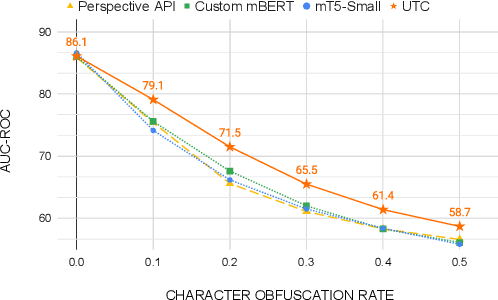
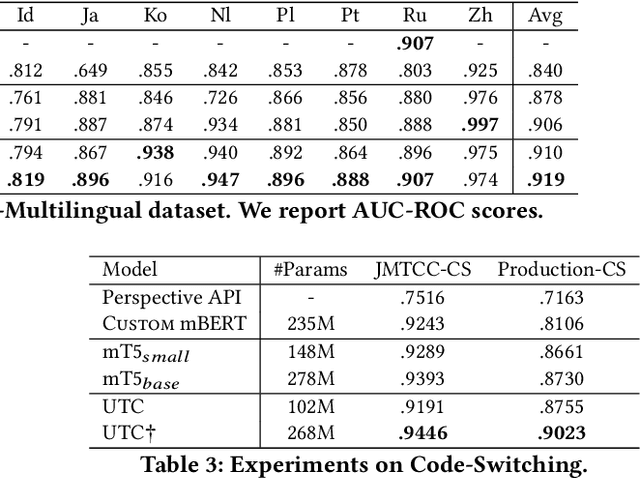
On the world wide web, toxic content detectors are a crucial line of defense against potentially hateful and offensive messages. As such, building highly effective classifiers that enable a safer internet is an important research area. Moreover, the web is a highly multilingual, cross-cultural community that develops its own lingo over time. As such, it is crucial to develop models that are effective across a diverse range of languages, usages, and styles. In this paper, we present the fundamentals behind the next version of the Perspective API from Google Jigsaw. At the heart of the approach is a single multilingual token-free Charformer model that is applicable across a range of languages, domains, and tasks. We demonstrate that by forgoing static vocabularies, we gain flexibility across a variety of settings. We additionally outline the techniques employed to make such a byte-level model efficient and feasible for productionization. Through extensive experiments on multilingual toxic comment classification benchmarks derived from real API traffic and evaluation on an array of code-switching, covert toxicity, emoji-based hate, human-readable obfuscation, distribution shift, and bias evaluation settings, we show that our proposed approach outperforms strong baselines. Finally, we present our findings from deploying this system in production.