 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Generation of Perspective API: Efficient Multilingual Character-level Transformers
Feb 22, 2022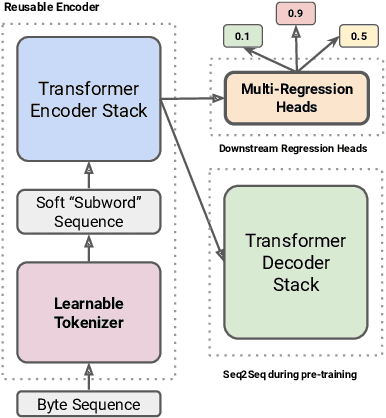
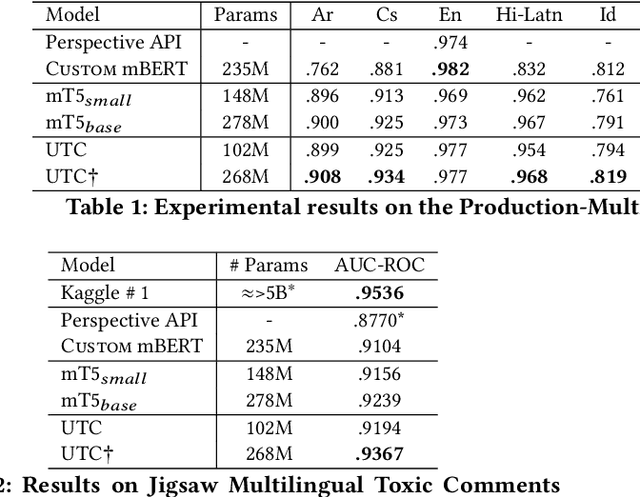
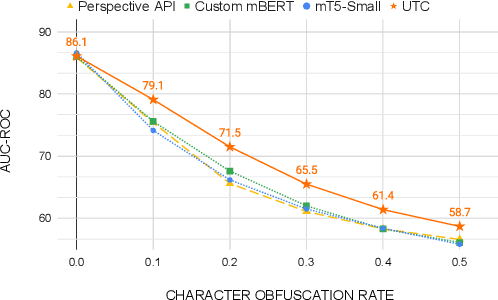
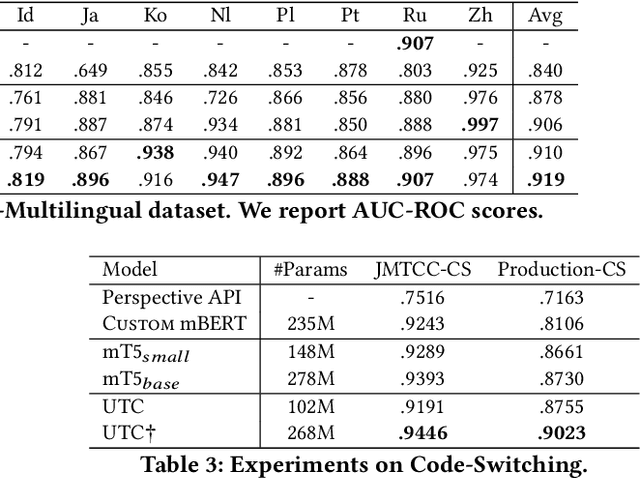
On the world wide web, toxic content detectors are a crucial line of defense against potentially hateful and offensive messages. As such, building highly effective classifiers that enable a safer internet is an important research area. Moreover, the web is a highly multilingual, cross-cultural community that develops its own lingo over time. As such, it is crucial to develop models that are effective across a diverse range of languages, usages, and styles. In this paper, we present the fundamentals behind the next version of the Perspective API from Google Jigsaw. At the heart of the approach is a single multilingual token-free Charformer model that is applicable across a range of languages, domains, and tasks. We demonstrate that by forgoing static vocabularies, we gain flexibility across a variety of settings. We additionally outline the techniques employed to make such a byte-level model efficient and feasible for productionization. Through extensive experiments on multilingual toxic comment classification benchmarks derived from real API traffic and evaluation on an array of code-switching, covert toxicity, emoji-based hate, human-readable obfuscation, distribution shift, and bias evaluation settings, we show that our proposed approach outperforms strong baselines. Finally, we present our findings from deploying this system in production.
ReasonBERT: Pre-trained to Reason with Distant Supervision
Sep 10, 2021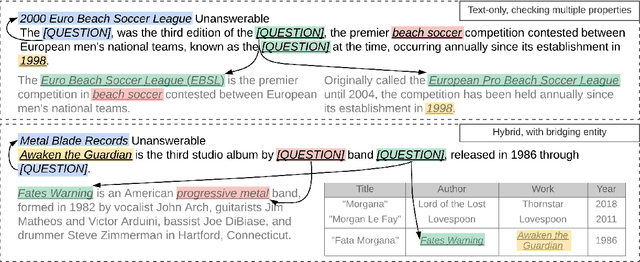

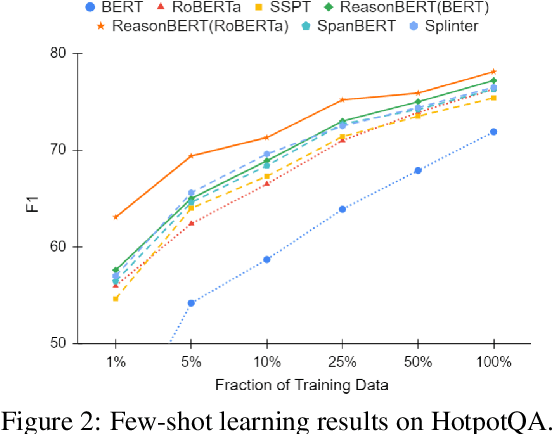
We present ReasonBert, a pre-training method that augments language models with the ability to reason over long-range relations and multiple, possibly hybrid contexts. Unlike existing pre-training methods that only harvest learning signals from local contexts of naturally occurring texts, we propose a generalized notion of distant supervision to automatically connect multiple pieces of text and tables to create pre-training examples that require long-range reasoning. Different types of reasoning are simulated, including intersecting multiple pieces of evidence, bridging from one piece of evidence to another, and detecting unanswerable cases. We conduct a comprehensive evaluation on a variety of extractive question answering datasets ranging from single-hop to multi-hop and from text-only to table-only to hybrid that require various reasoning capabilities and show that ReasonBert achieves remarkable improvement over an array of strong baselines. Few-shot experiments further demonstrate that our pre-training method substantially improves sample efficiency.
TURL: Table Understanding through Representation Learning
Jun 26, 2020

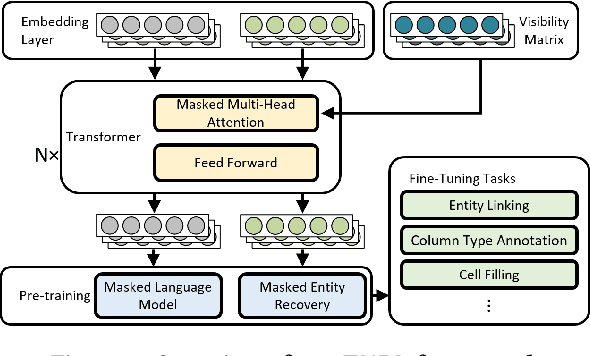
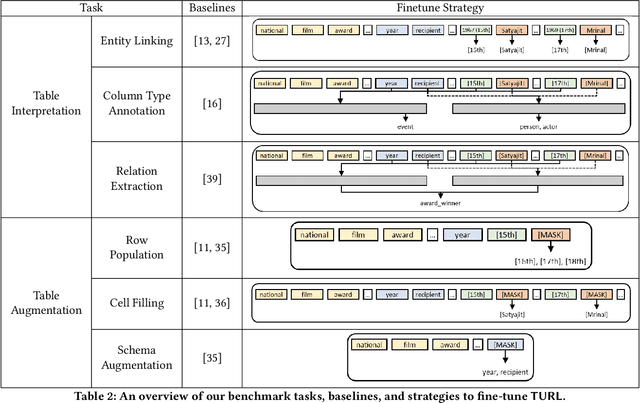
Relational tables on the Web store a vast amount of knowledge. Owing to the wealth of such tables, there has been tremendous progress on a variety of tasks in the area of table understanding. However, existing work generally relies on heavily-engineered task specific features and model architectures. In this paper, we present TURL, a novel framework that introduces the pre-training/finetuning paradigm to relational Web tables. During pre-training, our framework learns deep contextualized representations on relational tables in an unsupervised manner. Its universal model design with pre-trained representations can be applied to a wide range of tasks with minimal task-specific fine-tuning. Specifically, we propose a structure-aware Transformer encoder to model the row-column structure of relational tables, and present a new Masked Entity Recovery (MER) objective for pre-training to capture the semantics and knowledge in large-scale unlabeled data. We systematically evaluate TURL with a benchmark consisting of 6 different tasks for table understanding (e.g., relation extraction, cell filling). We show that TURL generalizes well to all tasks and substantially outperforms existing methods in almost all instances.
What is Fair? Exploring Pareto-Efficiency for Fairness Constrained Classifiers
Oct 30, 2019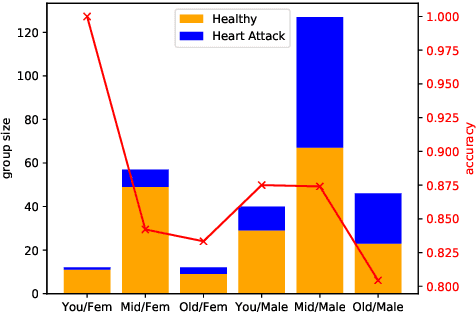

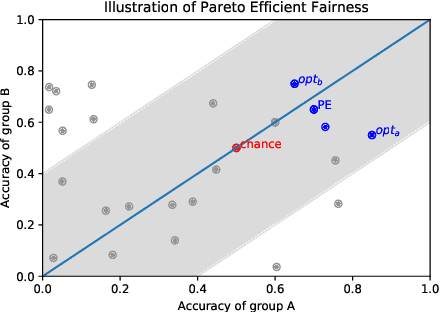

The potential for learned models to amplify existing societal biases has been broadly recognized. Fairness-aware classifier constraints, which apply equality metrics of performance across subgroups defined on sensitive attributes such as race and gender, seek to rectify inequity but can yield non-uniform degradation in performance for skewed datasets. In certain domains, imbalanced degradation of performance can yield another form of unintentional bias. In the spirit of constructing fairness-aware algorithms as societal imperative, we explore an alternative: Pareto-Efficient Fairness (PEF). Theoretically, we prove that PEF identifies the operating point on the Pareto curve of subgroup performances closest to the fairness hyperplane, maximizing multiple subgroup accuracy. Empirically we demonstrate that PEF outperforms by achieving Pareto levels in accuracy for all subgroups compared to strict fairness constraints in several UCI datasets.
Fairness Sample Complexity and the Case for Human Intervention
Oct 24, 2019



With the aim of building machine learning systems that incorporate standards of fairness and accountability, we explore explicit subgroup sample complexity bounds. The work is motivated by the observation that classifier predictions for real world datasets often demonstrate drastically different metrics, such as accuracy, when subdivided by specific sensitive variable subgroups. The reasons for these discrepancies are varied and not limited to the influence of mitigating variables, institutional bias, underlying population distributions as well as sampling bias. Among the numerous definitions of fairness that exist, we argue that at a minimum, principled ML practices should ensure that classification predictions are able to mirror the underlying sub-population distributions. However, as the number of sensitive variables increase, populations meeting at the intersectionality of these variables may simply not exist or may not be large enough to provide accurate samples for classification. In these increasingly likely scenarios, we make the case for human intervention and applying situational and individual definitions of fairness. In this paper we present lower bounds of subgroup sample complexity for metric-fair learning based on the theory of Probably Approximately Metric Fair Learning. We demonstrate that for a classifier to approach a definition of fairness in terms of specific sensitive variables, adequate subgroup population samples need to exist and the model dimensionality has to be aligned with subgroup population distributions. In cases where this is not feasible, we propose an approach using individual fairness definitions for achieving alignment. We look at two commonly explored UCI datasets under this lens and suggest human interventions for data collection for specific subgroups to achieve approximate individual fairness for linear hypotheses.