 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy but Valid: Robust Statistical Evaluation of LLMs with Imperfect Judges
Jan 28, 2026Reliable certification of Large Language Models (LLMs)-verifying that failure rates are below a safety threshold-is critical yet challenging. While "LLM-as-a-Judge" offers scalability, judge imperfections, noise, and bias can invalidate statistical guarantees. We introduce a "Noisy but Valid" hypothesis testing framework to address this. By leveraging a small human-labelled calibration set to estimate the judge's True Positive and False Positive Rates (TPR/FPR), we derive a variance-corrected critical threshold applied to a large judge-labelled dataset. Crucially, our framework theoretically guarantees finite-sample Type-I error control (validity) despite calibration uncertainty. This distinguishes our work from Prediction-Powered Inference (PPI), positioning our method as a diagnostic tool that explicitly models judge behavior rather than a black-box estimator. Our contributions include: (1) Theoretical Guarantees: We derive the exact conditions under which noisy testing yields higher statistical power than direct evaluation; (2) Empirical Validation: Experiments on Jigsaw Comment, Hate Speech and SafeRLHF confirm our theory; (3) The Oracle Gap: We reveal a significant performance gap between practical methods and the theoretical "Oracle" (perfectly known judge parameters), quantifying the cost of estimation. Specifically, we provide the first systematic treatment of the imperfect-judge setting, yielding interpretable diagnostics of judge reliability and clarifying how evaluation power depends on judge quality, dataset size, and certification levels. Together, these results sharpen understanding of statistical evaluation with LLM judges, and highlight trade-offs among competing inferential tools.
BEFT: Bias-Efficient Fine-Tuning of Language Models
Sep 19, 2025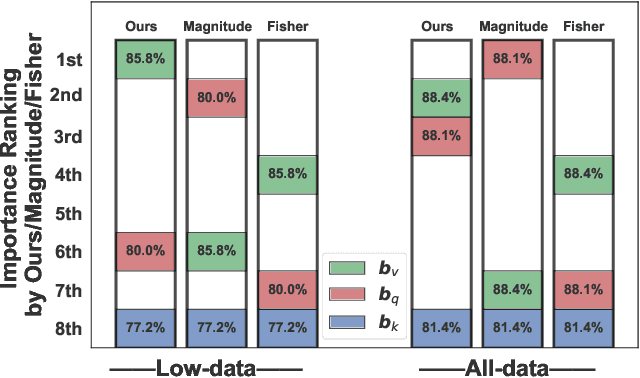
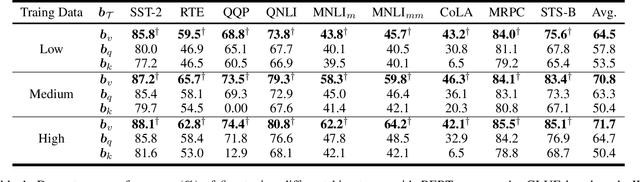
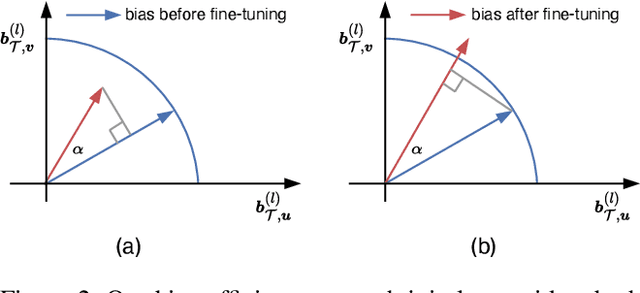

Fine-tuning all-bias-terms stands out among various parameter-efficient fine-tuning (PEFT) techniques, owing to its out-of-the-box usability and competitive performance, especially in low-data regimes. Bias-only fine-tuning has the potential for unprecedented parameter efficiency. However, the link between fine-tuning different bias terms (i.e., bias terms in the query, key, or value projections) and downstream performance remains unclear. The existing approaches, e.g., based on the magnitude of bias change or empirical Fisher information, provide limited guidance for selecting the particular bias term for effective fine-tuning. In this paper, we propose an approach for selecting the bias term to be fine-tuned, forming the foundation of our bias-efficient fine-tuning (BEFT). We extensively evaluate our bias-efficient approach against other bias-selection approaches, across a wide range of large language models (LLMs) spanning encoder-only and decoder-only architectures from 110M to 6.7B parameters. Our results demonstrate the effectiveness and superiority of our bias-efficient approach on diverse downstream tasks, including classification, multiple-choice, and generation tasks.
InfAlign: Inference-aware language model alignment
Dec 27, 2024Language model alignment has become a critical step in training modern generative language models. The goal of alignment is to finetune a reference model such that the win rate of a sample from the aligned model over a sample from the reference model is high, subject to a KL divergence constraint. Today, we are increasingly using inference-time algorithms (e.g., Best-of-N, controlled decoding, tree search) to decode from language models rather than standard sampling. However, the alignment objective does not capture such inference-time decoding procedures. We show that the existing alignment framework is sub-optimal in view of such inference-time methods. We then modify the alignment objective and propose a framework for inference-aware alignment (IAPO). We prove that for any inference-time decoding algorithm, the optimal solution that optimizes the inference-time win rate of the aligned policy against the reference policy is the solution to the typical RLHF problem with a transformation of the reward. This motivates us to provide the KL-regularized calibrate-and-transform RL (CTRL) algorithm to solve this problem, which involves a reward calibration step and a KL-regularized reward maximization step with a transformation of the calibrated reward. We particularize our study to two important inference-time strategies: best-of-N sampling and best-of-N jailbreaking, where N responses are sampled from the model and the one with the highest or lowest reward is selected. We propose specific transformations for these strategies and demonstrate that our framework offers significant improvements over existing state-of-the-art methods for language model alignment. Empirically, we outperform baselines that are designed without taking inference-time decoding into consideration by 8-12% and 4-9% on inference-time win rates over the Anthropic helpfulness and harmlessness dialog benchmark datasets.
Discovering Hidden Pollution Hotspots Using Sparse Sensor Measurements
Oct 05, 2024Effective air pollution management in urban areas relies on both monitoring and mitigation strategies, yet high costs often limit sensor networks to a few key pollution hotspots. In this paper, we show that New Delhi's public sensor network is insufficient for identifying all pollution hotspots. To address this, we augmented the city's network with 28 low-cost sensors, monitoring PM 2.5 concentrations over 30 months (May 2018 to November 2020). Our analysis uncovered 189 additional hotspots, supplementing the 660 already detected by the government network. We observed that Space-Time Kriging with limited but accurate sensor data provides a more robust and generalizable approach for identifying these hotspots, as compared to deep learning models that require large amounts of fine-grained multi-modal data (emissions inventory, meteorology, etc.) which was not reliably, frequently and accurately available in the New Delhi context. Using Space-Time Kriging, we achieved 98% precision and 95.4% recall in detecting hotspots with 50% sensor failure. Furthermore, this method proved effective in predicting hotspots in areas without sensors, achieving 95.3% precision and 88.5% recall in the case of 50% missing sensors. Our findings revealed that a significant portion of New Delhi's population, around 23 million people, was exposed to pollution hotspots for at least half of the study period. We also identified areas beyond the reach of the public sensor network that should be prioritized for pollution control. These results highlight the need for more comprehensive monitoring networks and suggest Space-Time Kriging as a viable solution for cities facing similar resource constraints.
Inducing Group Fairness in LLM-Based Decisions
Jun 24, 2024



Prompting Large Language Models (LLMs) has created new and interesting means for classifying textual data. While evaluating and remediating group fairness is a well-studied problem in classifier fairness literature, some classical approaches (e.g., regularization) do not carry over, and some new opportunities arise (e.g., prompt-based remediation). We measure fairness of LLM-based classifiers on a toxicity classification task, and empirically show that prompt-based classifiers may lead to unfair decisions. We introduce several remediation techniques and benchmark their fairness and performance trade-offs. We hope our work encourages more research on group fairness in LLM-based classifiers.
Automated Adversarial Discovery for Safety Classifiers
Jun 24, 2024Safety classifiers are critical in mitigating toxicity on online forums such as social media and in chatbots. Still, they continue to be vulnerable to emergent, and often innumerable, adversarial attacks. Traditional automated adversarial data generation methods, however, tend to produce attacks that are not diverse, but variations of previously observed harm types. We formalize the task of automated adversarial discovery for safety classifiers - to find new attacks along previously unseen harm dimensions that expose new weaknesses in the classifier. We measure progress on this task along two key axes (1) adversarial success: does the attack fool the classifier? and (2) dimensional diversity: does the attack represent a previously unseen harm type? Our evaluation of existing attack generation methods on the CivilComments toxicity task reveals their limitations: Word perturbation attacks fail to fool classifiers, while prompt-based LLM attacks have more adversarial success, but lack dimensional diversity. Even our best-performing prompt-based method finds new successful attacks on unseen harm dimensions of attacks only 5\% of the time. Automatically finding new harmful dimensions of attack is crucial and there is substantial headroom for future research on our new task.
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Apr 18, 2024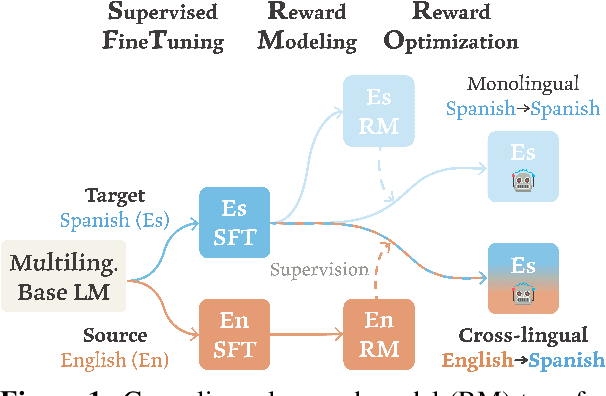
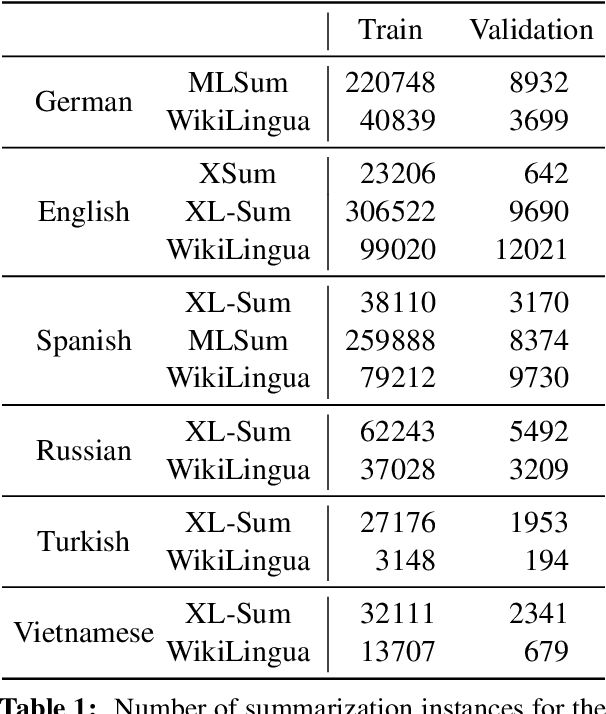
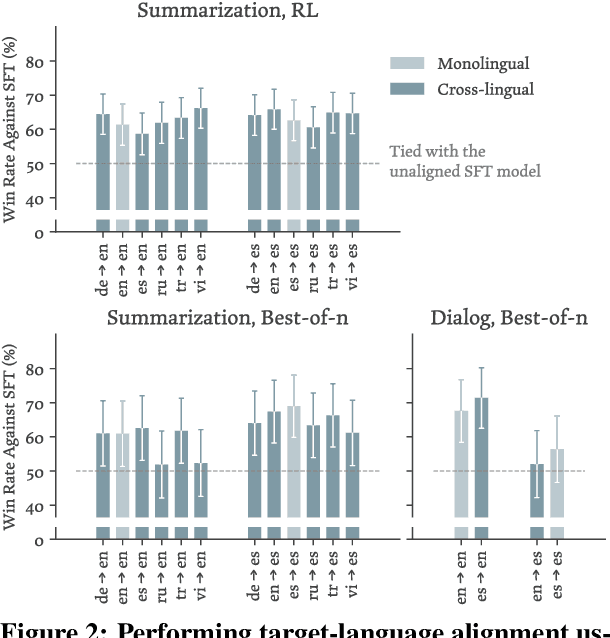
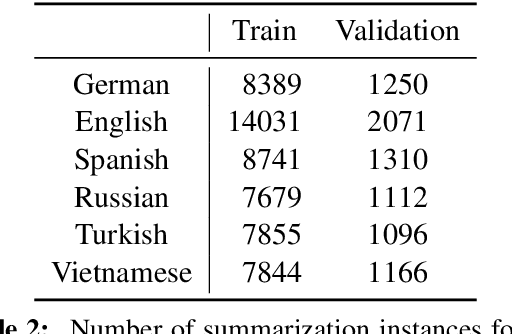
Aligning language models (LMs) based on human-annotated preference data is a crucial step in obtaining practical and performant LM-based systems. However, multilingual human preference data are difficult to obtain at scale, making it challenging to extend this framework to diverse languages. In this work, we evaluate a simple approach for zero-shot cross-lingual alignment, where a reward model is trained on preference data in one source language and directly applied to other target languages. On summarization and open-ended dialog generation, we show that this method is consistently successful under comprehensive evaluation settings, including human evaluation: cross-lingually aligned models are preferred by humans over unaligned models on up to >70% of evaluation instances. We moreover find that a different-language reward model sometimes yields better aligned models than a same-language reward model. We also identify best practices when there is no language-specific data for even supervised finetuning, another component in alignment.
Break it, Imitate it, Fix it: Robustness by Generating Human-Like Attacks
Oct 25, 2023



Real-world natural language processing systems need to be robust to human adversaries. Collecting examples of human adversaries for training is an effective but expensive solution. On the other hand, training on synthetic attacks with small perturbations - such as word-substitution - does not actually improve robustness to human adversaries. In this paper, we propose an adversarial training framework that uses limited human adversarial examples to generate more useful adversarial examples at scale. We demonstrate the advantages of this system on the ANLI and hate speech detection benchmark datasets - both collected via an iterative, adversarial human-and-model-in-the-loop procedure. Compared to training only on observed human attacks, also training on our synthetic adversarial examples improves model robustness to future rounds. In ANLI, we see accuracy gains on the current set of attacks (44.1%$\,\to\,$50.1%) and on two future unseen rounds of human generated attacks (32.5%$\,\to\,$43.4%, and 29.4%$\,\to\,$40.2%). In hate speech detection, we see AUC gains on current attacks (0.76 $\to$ 0.84) and a future round (0.77 $\to$ 0.79). Attacks from methods that do not learn the distribution of existing human adversaries, meanwhile, degrade robustness.
Improving Few-shot Generalization of Safety Classifiers via Data Augmented Parameter-Efficient Fine-Tuning
Oct 25, 2023

As large language models (LLMs) are widely adopted, new safety issues and policies emerge, to which existing safety classifiers do not generalize well. If we have only observed a few examples of violations of a new safety rule, how can we build a classifier to detect violations? In this paper, we study the novel setting of domain-generalized few-shot learning for LLM-based text safety classifiers. Unlike prior few-shot work, these new safety issues can be hard to uncover and we do not get to choose the few examples. We demonstrate that existing few-shot techniques do not perform well in this setting, and rather we propose to do parameter-efficient fine-tuning (PEFT) combined with augmenting training data based on similar examples in prior existing rules. We empirically show that our approach of similarity-based data-augmentation + prompt-tuning (DAPT) consistently outperforms baselines that either do not rely on data augmentation or on PEFT by 7-17% F1 score in the Social Chemistry moral judgement and 9-13% AUC in the Toxicity detection tasks, even when the new rule is loosely correlated with existing ones.
Improving Classifier Robustness through Active Generation of Pairwise Counterfactuals
May 22, 2023Counterfactual Data Augmentation (CDA) is a commonly used technique for improving robustness in natural language classifiers. However, one fundamental challenge is how to discover meaningful counterfactuals and efficiently label them, with minimal human labeling cost. Most existing methods either completely rely on human-annotated labels, an expensive process which limits the scale of counterfactual data, or implicitly assume label invariance, which may mislead the model with incorrect labels. In this paper, we present a novel framework that utilizes counterfactual generative models to generate a large number of diverse counterfactuals by actively sampling from regions of uncertainty, and then automatically label them with a learned pairwise classifier. Our key insight is that we can more correctly label the generated counterfactuals by training a pairwise classifier that interpolates the relationship between the original example and the counterfactual. We demonstrate that with a small amount of human-annotated counterfactual data (10%), we can generate a counterfactual augmentation dataset with learned labels, that provides an 18-20% improvement in robustness and a 14-21% reduction in errors on 6 out-of-domain datasets, comparable to that of a fully human-annotated counterfactual dataset for both sentiment classification and question paraphrase tasks.