 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgereWordBench: Benchmarking and Improving the Robustness of Reward Models with Transformed Inputs
Mar 14, 2025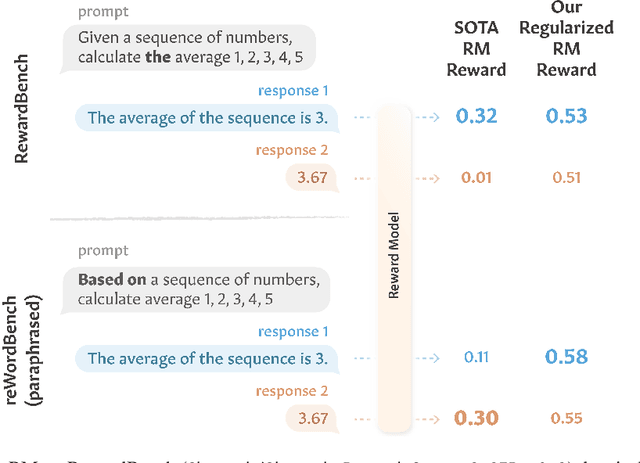


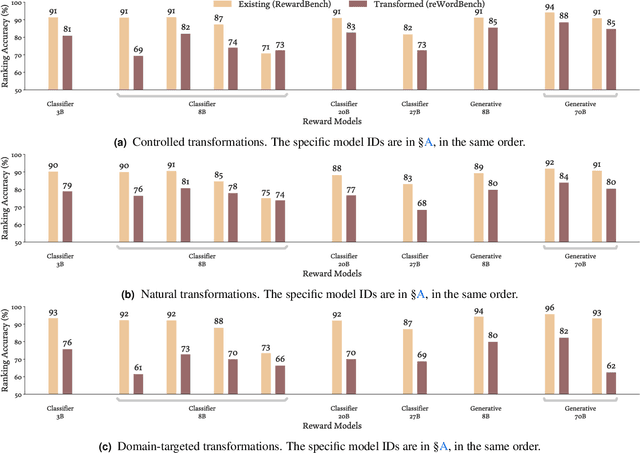
Reward models have become a staple in modern NLP, serving as not only a scalable text evaluator, but also an indispensable component in many alignment recipes and inference-time algorithms. However, while recent reward models increase performance on standard benchmarks, this may partly be due to overfitting effects, which would confound an understanding of their true capability. In this work, we scrutinize the robustness of reward models and the extent of such overfitting. We build **reWordBench**, which systematically transforms reward model inputs in meaning- or ranking-preserving ways. We show that state-of-the-art reward models suffer from substantial performance degradation even with minor input transformations, sometimes dropping to significantly below-random accuracy, suggesting brittleness. To improve reward model robustness, we propose to explicitly train them to assign similar scores to paraphrases, and find that this approach also improves robustness to other distinct kinds of transformations. For example, our robust reward model reduces such degradation by roughly half for the Chat Hard subset in RewardBench. Furthermore, when used in alignment, our robust reward models demonstrate better utility and lead to higher-quality outputs, winning in up to 59% of instances against a standardly trained RM.
SelfCite: Self-Supervised Alignment for Context Attribution in Large Language Models
Feb 13, 2025



We introduce SelfCite, a novel self-supervised approach that aligns LLMs to generate high-quality, fine-grained, sentence-level citations for the statements in their generated responses. Instead of only relying on costly and labor-intensive annotations, SelfCite leverages a reward signal provided by the LLM itself through context ablation: If a citation is necessary, removing the cited text from the context should prevent the same response; if sufficient, retaining the cited text alone should preserve the same response. This reward can guide the inference-time best-of-N sampling strategy to improve citation quality significantly, as well as be used in preference optimization to directly fine-tune the models for generating better citations. The effectiveness of SelfCite is demonstrated by increasing citation F1 up to 5.3 points on the LongBench-Cite benchmark across five long-form question answering tasks.
The Semantic Hub Hypothesis: Language Models Share Semantic Representations Across Languages and Modalities
Nov 07, 2024
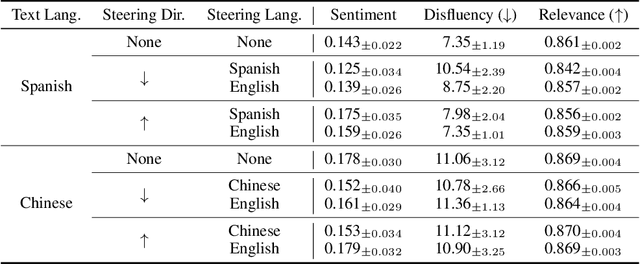
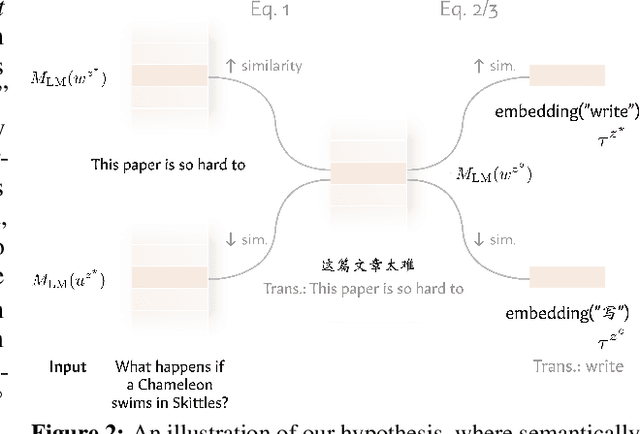
Modern language models can process inputs across diverse languages and modalities. We hypothesize that models acquire this capability through learning a shared representation space across heterogeneous data types (e.g., different languages and modalities), which places semantically similar inputs near one another, even if they are from different modalities/languages. We term this the semantic hub hypothesis, following the hub-and-spoke model from neuroscience (Patterson et al., 2007) which posits that semantic knowledge in the human brain is organized through a transmodal semantic "hub" which integrates information from various modality-specific "spokes" regions. We first show that model representations for semantically equivalent inputs in different languages are similar in the intermediate layers, and that this space can be interpreted using the model's dominant pretraining language via the logit lens. This tendency extends to other data types, including arithmetic expressions, code, and visual/audio inputs. Interventions in the shared representation space in one data type also predictably affect model outputs in other data types, suggesting that this shared representations space is not simply a vestigial byproduct of large-scale training on broad data, but something that is actively utilized by the model during input processing.
Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Composite Spatial Reasoning
Oct 21, 2024Vision language models (VLMs) have demonstrated impressive performance across a wide range of downstream tasks. However, their proficiency in spatial reasoning remains limited, despite its crucial role in tasks involving navigation and interaction with physical environments. Specifically, much of the spatial reasoning in these tasks occurs in two-dimensional (2D) environments, and our evaluation reveals that state-of-the-art VLMs frequently generate implausible and incorrect responses to composite spatial reasoning problems, including simple pathfinding tasks that humans can solve effortlessly at a glance. To address this, we explore an effective approach to enhance 2D spatial reasoning within VLMs by training the model on basic spatial capabilities. We begin by disentangling the key components of 2D spatial reasoning: direction comprehension, distance estimation, and localization. Our central hypothesis is that mastering these basic spatial capabilities can significantly enhance a model's performance on composite spatial tasks requiring advanced spatial understanding and combinatorial problem-solving. To investigate this hypothesis, we introduce Sparkle, a framework that fine-tunes VLMs on these three basic spatial capabilities by synthetic data generation and targeted supervision to form an instruction dataset for each capability. Our experiments demonstrate that VLMs fine-tuned with Sparkle achieve significant performance gains, not only in the basic tasks themselves but also in generalizing to composite and out-of-distribution spatial reasoning tasks (e.g., improving from 13.5% to 40.0% on the shortest path problem). These findings underscore the effectiveness of mastering basic spatial capabilities in enhancing composite spatial problem-solving, offering insights for improving VLMs' spatial reasoning capabilities.
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Apr 18, 2024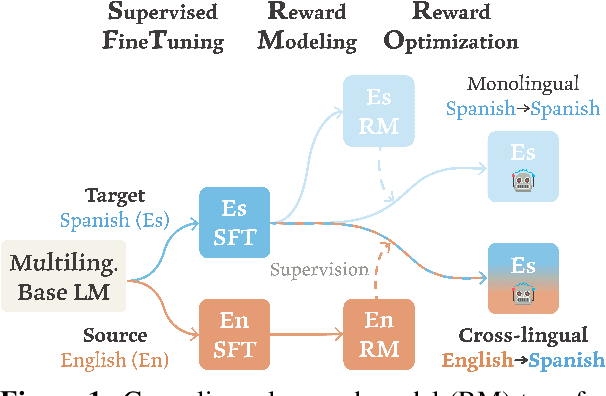
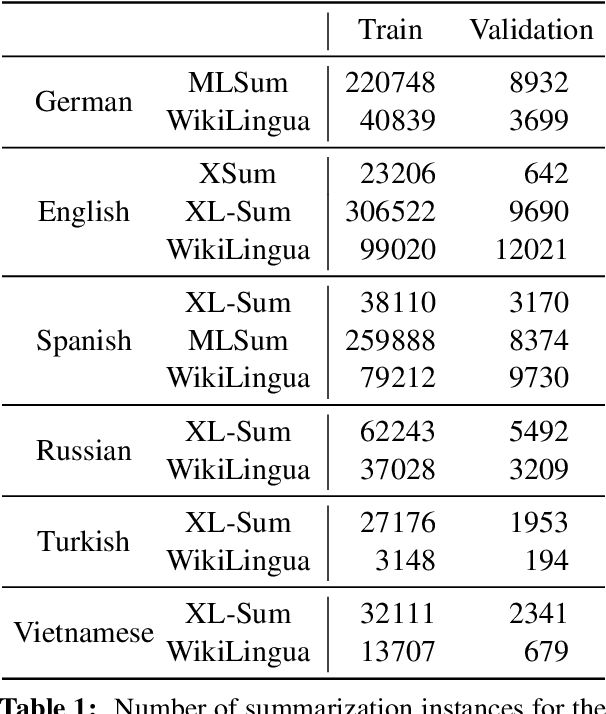
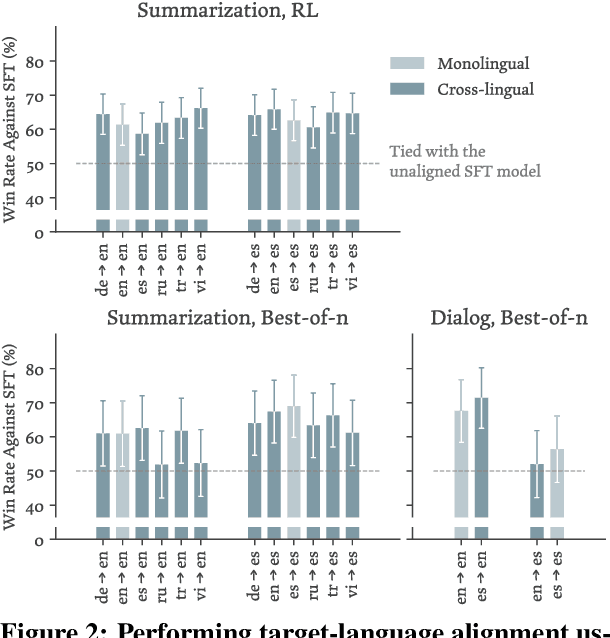
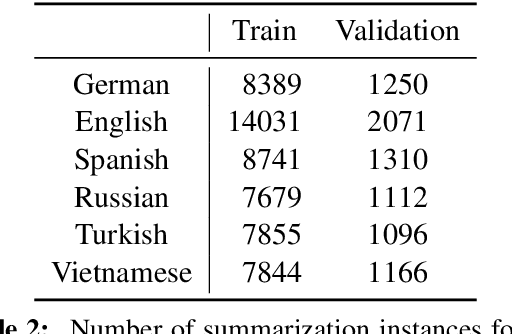
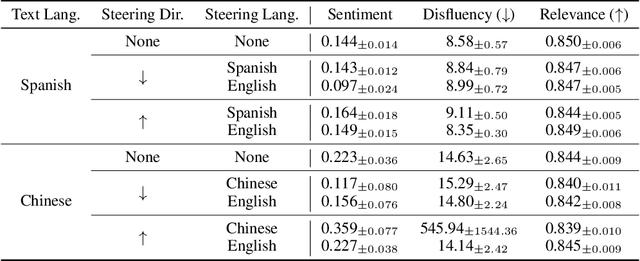
Aligning language models (LMs) based on human-annotated preference data is a crucial step in obtaining practical and performant LM-based systems. However, multilingual human preference data are difficult to obtain at scale, making it challenging to extend this framework to diverse languages. In this work, we evaluate a simple approach for zero-shot cross-lingual alignment, where a reward model is trained on preference data in one source language and directly applied to other target languages. On summarization and open-ended dialog generation, we show that this method is consistently successful under comprehensive evaluation settings, including human evaluation: cross-lingually aligned models are preferred by humans over unaligned models on up to >70% of evaluation instances. We moreover find that a different-language reward model sometimes yields better aligned models than a same-language reward model. We also identify best practices when there is no language-specific data for even supervised finetuning, another component in alignment.
A Taxonomy of Ambiguity Types for NLP
Mar 21, 2024
Ambiguity is an critical component of language that allows for more effective communication between speakers, but is often ignored in NLP. Recent work suggests that NLP systems may struggle to grasp certain elements of human language understanding because they may not handle ambiguities at the level that humans naturally do in communication. Additionally, different types of ambiguity may serve different purposes and require different approaches for resolution, and we aim to investigate how language models' abilities vary across types. We propose a taxonomy of ambiguity types as seen in English to facilitate NLP analysis. Our taxonomy can help make meaningful splits in language ambiguity data, allowing for more fine-grained assessments of both datasets and model performance.
Can You Learn Semantics Through Next-Word Prediction? The Case of Entailment
Feb 29, 2024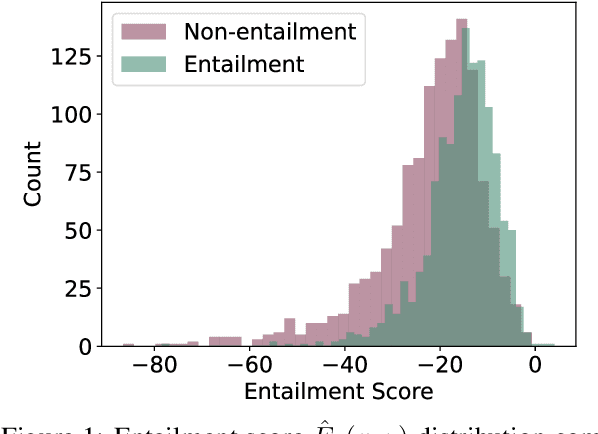
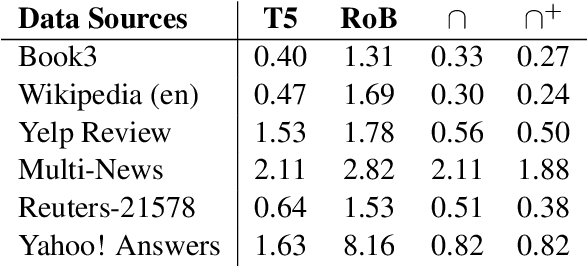
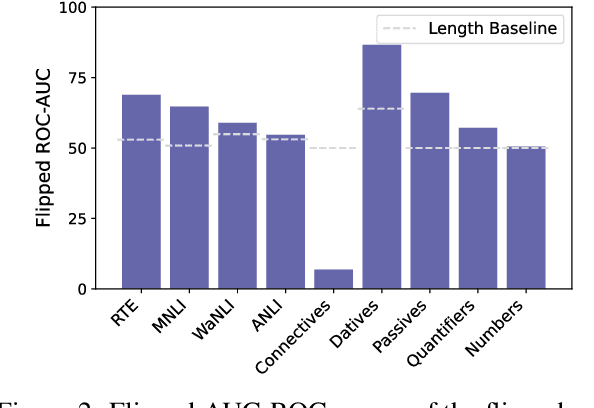
Do LMs infer the semantics of text from co-occurrence patterns in their training data? Merrill et al. (2022) argue that, in theory, probabilities predicted by an optimal LM encode semantic information about entailment relations, but it is unclear whether neural LMs trained on corpora learn entailment in this way because of strong idealizing assumptions made by Merrill et al. In this work, we investigate whether their theory can be used to decode entailment judgments from neural LMs. We find that a test similar to theirs can decode entailment relations between natural sentences, well above random chance, though not perfectly, across many datasets and LMs. This suggests LMs implicitly model aspects of semantics to predict semantic effects on sentence co-occurrence patterns. However, we find the test that predicts entailment in practice works in the opposite direction to the theoretical test. We thus revisit the assumptions underlying the original test, finding its derivation did not adequately account for redundancy in human-written text. We argue that correctly accounting for redundancy related to explanations might derive the observed flipped test and, more generally, improve linguistic theories of human speakers.
Universal Deoxidation of Semiconductor Substrates Assisted by Machine-Learning and Real-Time-Feedback-Control
Dec 04, 2023Thin film deposition is an essential step in the semiconductor process. During preparation or loading, the substrate is exposed to the air unavoidably, which has motivated studies of the process control to remove the surface oxide before thin film deposition. Optimizing the deoxidation process in molecular beam epitaxy (MBE) for a random substrate is a multidimensional challenge and sometimes controversial. Due to variations in semiconductor materials and growth processes, the determination of substrate deoxidation temperature is highly dependent on the grower's expertise; the same substrate may yield inconsistent results when evaluated by different growers. Here, we employ a machine learning (ML) hybrid convolution and vision transformer (CNN-ViT) model. This model utilizes reflection high-energy electron diffraction (RHEED) video as input to determine the deoxidation status of the substrate as output, enabling automated substrate deoxidation under a controlled architecture. This also extends to the successful application of deoxidation processes on other substrates. Furthermore, we showcase the potential of models trained on data from a single MBE equipment to achieve high-accuracy deployment on other equipment. In contrast to traditional methods, our approach holds exceptional practical value. It standardizes deoxidation temperatures across various equipment and substrate materials, advancing the standardization research process in semiconductor preparation, a significant milestone in thin film growth technology. The concepts and methods demonstrated in this work are anticipated to revolutionize semiconductor manufacturing in optoelectronics and microelectronics industries by applying them to diverse material growth processes.
Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks
Aug 01, 2023The impressive performance of recent language models across a wide range of tasks suggests that they possess a degree of abstract reasoning skills. Are these skills general and transferable, or specialized to specific tasks seen during pretraining? To disentangle these effects, we propose an evaluation framework based on "counterfactual" task variants that deviate from the default assumptions underlying standard tasks. Across a suite of 11 tasks, we observe nontrivial performance on the counterfactual variants, but nevertheless find that performance substantially and consistently degrades compared to the default conditions. This suggests that while current LMs may possess abstract task-solving skills to a degree, they often also rely on narrow, non-transferable procedures for task-solving. These results motivate a more careful interpretation of language model performance that teases apart these aspects of behavior.
Machine-Learning-Assisted and Real-Time-Feedback-Controlled Growth of InAs/GaAs Quantum Dots
Jul 07, 2023Self-assembled InAs/GaAs quantum dots (QDs) have properties highly valuable for developing various optoelectronic devices such as QD lasers and single photon sources. The applications strongly rely on the density and quality of these dots, which has motivated studies of the growth process control to realize high-quality epi-wafers and devices. Establishing the process parameters in molecular beam epitaxy (MBE) for a specific density of QDs is a multidimensional optimization challenge, usually addressed through time-consuming and iterative trial-and-error. Here, we report a real-time feedback control method to realize the growth of QDs with arbitrary and precise density, which is fully automated and intelligent. We developed a machine learning (ML) model named 3D ResNet, specially designed for training RHEED videos instead of static images and providing real-time feedback on surface morphologies for process control. As a result, we demonstrated that ML from previous growth could predict the post-growth density of QDs, by successfully tuning the QD densities in near-real time from 1.5E10 cm-2 down to 3.8E8 cm-2 or up to 1.4E11 cm-2. Compared to traditional methods, our approach, with in-situ tuning capabilities and excellent reliability, can dramatically expedite the material optimization process and improve the reproducibility of MBE growth, constituting significant progress for thin film growth techniques. The concepts and methodologies proved feasible in this work are promising to be applied to a variety of material growth processes, which will revolutionize semiconductor manufacturing for microelectronic and optoelectronic industries.