 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan You Learn Semantics Through Next-Word Prediction? The Case of Entailment
Paper and Code
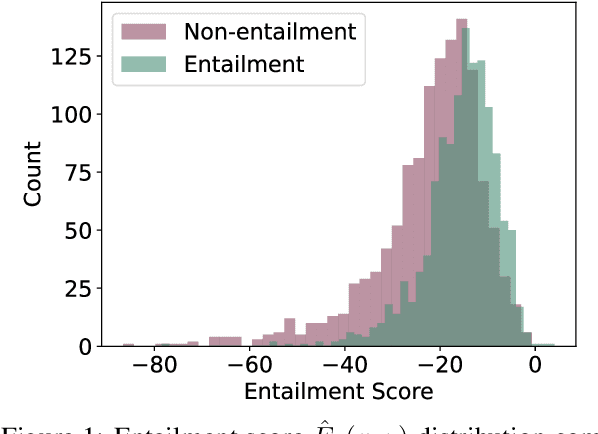
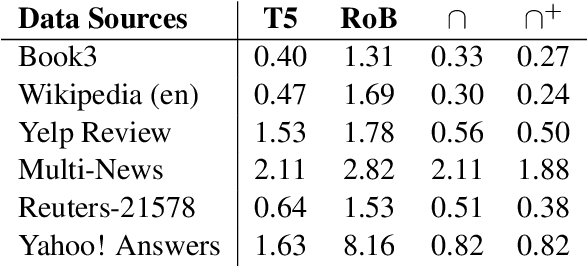
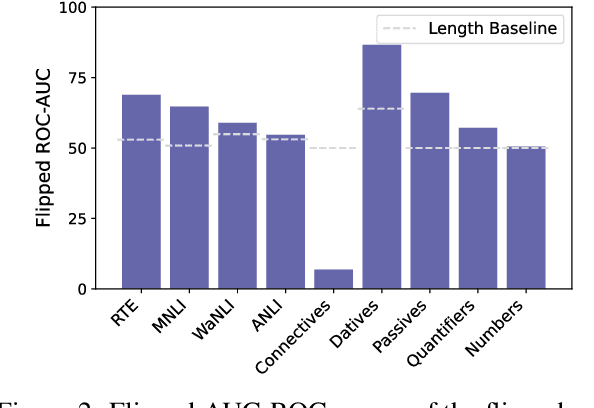
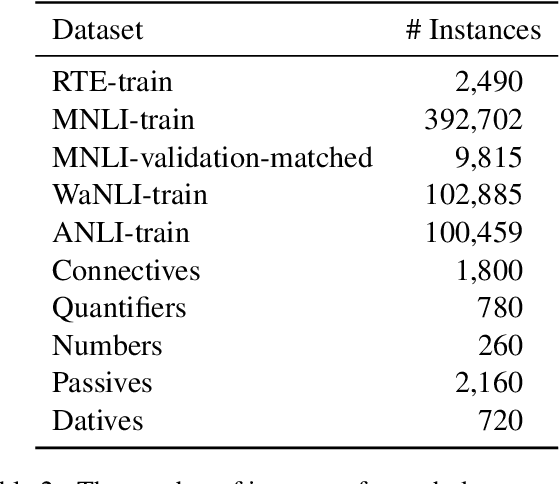
Do LMs infer the semantics of text from co-occurrence patterns in their training data? Merrill et al. (2022) argue that, in theory, probabilities predicted by an optimal LM encode semantic information about entailment relations, but it is unclear whether neural LMs trained on corpora learn entailment in this way because of strong idealizing assumptions made by Merrill et al. In this work, we investigate whether their theory can be used to decode entailment judgments from neural LMs. We find that a test similar to theirs can decode entailment relations between natural sentences, well above random chance, though not perfectly, across many datasets and LMs. This suggests LMs implicitly model aspects of semantics to predict semantic effects on sentence co-occurrence patterns. However, we find the test that predicts entailment in practice works in the opposite direction to the theoretical test. We thus revisit the assumptions underlying the original test, finding its derivation did not adequately account for redundancy in human-written text. We argue that correctly accounting for redundancy related to explanations might derive the observed flipped test and, more generally, improve linguistic theories of human speakers.