 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Apr 02, 2026Large language model (LLM)-based evolution is a promising approach for open-ended discovery, where progress requires sustained search and knowledge accumulation. Existing methods still rely heavily on fixed heuristics and hard-coded exploration rules, which limit the autonomy of LLM agents. We present CORAL, the first framework for autonomous multi-agent evolution on open-ended problems. CORAL replaces rigid control with long-running agents that explore, reflect, and collaborate through shared persistent memory, asynchronous multi-agent execution, and heartbeat-based interventions. It also provides practical safeguards, including isolated workspaces, evaluator separation, resource management, and agent session and health management. Evaluated on diverse mathematical, algorithmic, and systems optimization tasks, CORAL sets new state-of-the-art results on 10 tasks, achieving 3-10 times higher improvement rates with far fewer evaluations than fixed evolutionary search baselines across tasks. On Anthropic's kernel engineering task, four co-evolving agents improve the best known score from 1363 to 1103 cycles. Mechanistic analyses further show how these gains arise from knowledge reuse and multi-agent exploration and communication. Together, these results suggest that greater agent autonomy and multi-agent evolution can substantially improve open-ended discovery. Code is available at https://github.com/Human-Agent-Society/CORAL.
Envisioning global urban development with satellite imagery and generative AI
Mar 27, 2026Urban development has been a defining force in human history, shaping cities for centuries. However, past studies mostly analyze such development as predictive tasks, failing to reflect its generative nature. Therefore, this study designs a multimodal generative AI framework to envision sustainable urban development at a global scale. By integrating prompts and geospatial controls, our framework can generate high-fidelity, diverse, and realistic urban satellite imagery across the 500 largest metropolitan areas worldwide. It enables users to specify urban development goals, creating new images that align with them while offering diverse scenarios whose appearance can be controlled with text prompts and geospatial constraints. It also facilitates urban redevelopment practices by learning from the surrounding environment. Beyond visual synthesis, we find that it encodes and interprets latent representations of urban form for global cross-city learning, successfully transferring styles of urban environments across a global spatial network. The latent representations can also enhance downstream prediction tasks such as carbon emission prediction. Further, human expert evaluation confirms that our generated urban images are comparable to real urban images. Overall, this study presents innovative approaches for accelerated urban planning and supports scenario-based planning processes for worldwide cities.
Risk-Controllable Multi-View Diffusion for Driving Scenario Generation
Mar 12, 2026Generating safety-critical driving scenarios is crucial for evaluating and improving autonomous driving systems, but long-tail risky situations are rarely observed in real-world data and difficult to specify through manual scenario design. Existing generative approaches typically treat risk as an after-the-fact label and struggle to maintain geometric consistency in multi-view driving scenes. We present RiskMV-DPO, a general and systematic pipeline for physically-informed, risk-controllable multi-view scenario generation. By integrating target risk levels with physically-grounded risk modeling, we autonomously synthesize diverse and high-stakes dynamic trajectories that serve as explicit geometric anchors for a diffusion-based video generator. To ensure spatial-temporal coherence and geometric fidelity, we introduce a geometry-appearance alignment module and a region-aware direct preference optimization (RA-DPO) strategy with motion-aware masking to focus learning on localized dynamic regions.Experiments on the nuScenes dataset show that RiskMV-DPO can freely generate a wide spectrum of diverse long-tail scenarios while maintaining state-of-the-art visual quality, improving 3D detection mAP from 18.17 to 30.50 and reducing FID to 15.70. Our work shifts the role of world models from passive environment prediction to proactive, risk-controllable synthesis, providing a scalable toolchain for the safety-oriented development of embodied intelligence.
RAST-MoE-RL: A Regime-Aware Spatio-Temporal MoE Framework for Deep Reinforcement Learning in Ride-Hailing
Dec 13, 2025Ride-hailing platforms face the challenge of balancing passenger waiting times with overall system efficiency under highly uncertain supply-demand conditions. Adaptive delayed matching creates a trade-off between matching and pickup delays by deciding whether to assign drivers immediately or batch requests. Since outcomes accumulate over long horizons with stochastic dynamics, reinforcement learning (RL) is a suitable framework. However, existing approaches often oversimplify traffic dynamics or use shallow encoders that miss complex spatiotemporal patterns. We introduce the Regime-Aware Spatio-Temporal Mixture-of-Experts (RAST-MoE), which formalizes adaptive delayed matching as a regime-aware MDP equipped with a self-attention MoE encoder. Unlike monolithic networks, our experts specialize automatically, improving representation capacity while maintaining computational efficiency. A physics-informed congestion surrogate preserves realistic density-speed feedback, enabling millions of efficient rollouts, while an adaptive reward scheme guards against pathological strategies. With only 12M parameters, our framework outperforms strong baselines. On real-world Uber trajectory data (San Francisco), it improves total reward by over 13%, reducing average matching and pickup delays by 10% and 15% respectively. It demonstrates robustness across unseen demand regimes and stable training. These findings highlight the potential of MoE-enhanced RL for large-scale decision-making with complex spatiotemporal dynamics.
Reproducibility in the Control of Autonomous Mobility-on-Demand Systems
Jun 09, 2025



Autonomous Mobility-on-Demand (AMoD) systems, powered by advances in robotics, control, and Machine Learning (ML), offer a promising paradigm for future urban transportation. AMoD offers fast and personalized travel services by leveraging centralized control of autonomous vehicle fleets to optimize operations and enhance service performance. However, the rapid growth of this field has outpaced the development of standardized practices for evaluating and reporting results, leading to significant challenges in reproducibility. As AMoD control algorithms become increasingly complex and data-driven, a lack of transparency in modeling assumptions, experimental setups, and algorithmic implementation hinders scientific progress and undermines confidence in the results. This paper presents a systematic study of reproducibility in AMoD research. We identify key components across the research pipeline, spanning system modeling, control problems, simulation design, algorithm specification, and evaluation, and analyze common sources of irreproducibility. We survey prevalent practices in the literature, highlight gaps, and propose a structured framework to assess and improve reproducibility. Specifically, concrete guidelines are offered, along with a "reproducibility checklist", to support future work in achieving replicable, comparable, and extensible results. While focused on AMoD, the principles and practices we advocate generalize to a broader class of cyber-physical systems that rely on networked autonomy and data-driven control. This work aims to lay the foundation for a more transparent and reproducible research culture in the design and deployment of intelligent mobility systems.
Position: Simulating Society Requires Simulating Thought
Jun 08, 2025Simulating society with large language models (LLMs), we argue, requires more than generating plausible behavior -- it demands cognitively grounded reasoning that is structured, revisable, and traceable. LLM-based agents are increasingly used to emulate individual and group behavior -- primarily through prompting and supervised fine-tuning. Yet they often lack internal coherence, causal reasoning, and belief traceability -- making them unreliable for analyzing how people reason, deliberate, or respond to interventions. To address this, we present a conceptual modeling paradigm, Generative Minds (GenMinds), which draws from cognitive science to support structured belief representations in generative agents. To evaluate such agents, we introduce the RECAP (REconstructing CAusal Paths) framework, a benchmark designed to assess reasoning fidelity via causal traceability, demographic grounding, and intervention consistency. These contributions advance a broader shift: from surface-level mimicry to generative agents that simulate thought -- not just language -- for social simulations.
Generative AI for Urban Design: A Stepwise Approach Integrating Human Expertise with Multimodal Diffusion Models
May 30, 2025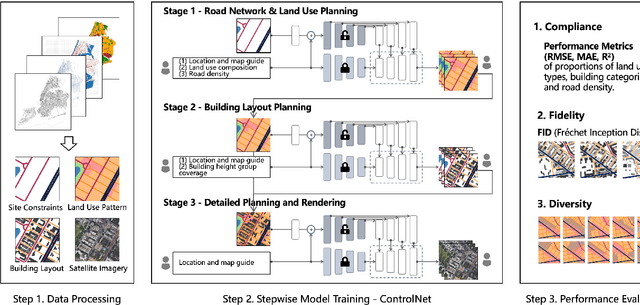
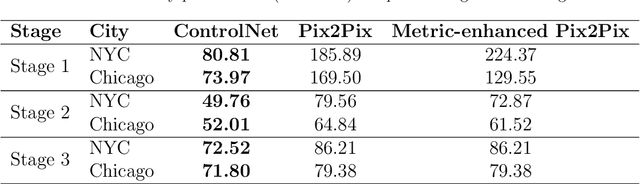
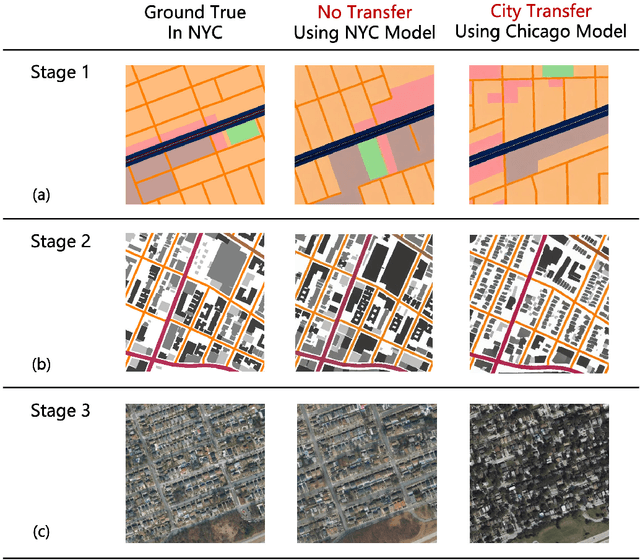
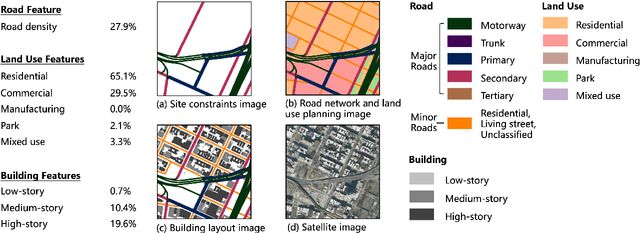
Urban design is a multifaceted process that demands careful consideration of site-specific constraints and collaboration among diverse professionals and stakeholders. The advent of generative artificial intelligence (GenAI) offers transformative potential by improving the efficiency of design generation and facilitating the communication of design ideas. However, most existing approaches are not well integrated with human design workflows. They often follow end-to-end pipelines with limited control, overlooking the iterative nature of real-world design. This study proposes a stepwise generative urban design framework that integrates multimodal diffusion models with human expertise to enable more adaptive and controllable design processes. Instead of generating design outcomes in a single end-to-end process, the framework divides the process into three key stages aligned with established urban design workflows: (1) road network and land use planning, (2) building layout planning, and (3) detailed planning and rendering. At each stage, multimodal diffusion models generate preliminary designs based on textual prompts and image-based constraints, which can then be reviewed and refined by human designers. We design an evaluation framework to assess the fidelity, compliance, and diversity of the generated designs. Experiments using data from Chicago and New York City demonstrate that our framework outperforms baseline models and end-to-end approaches across all three dimensions. This study underscores the benefits of multimodal diffusion models and stepwise generation in preserving human control and facilitating iterative refinements, laying the groundwork for human-AI interaction in urban design solutions.
Generative AI for Urban Planning: Synthesizing Satellite Imagery via Diffusion Models
May 13, 2025
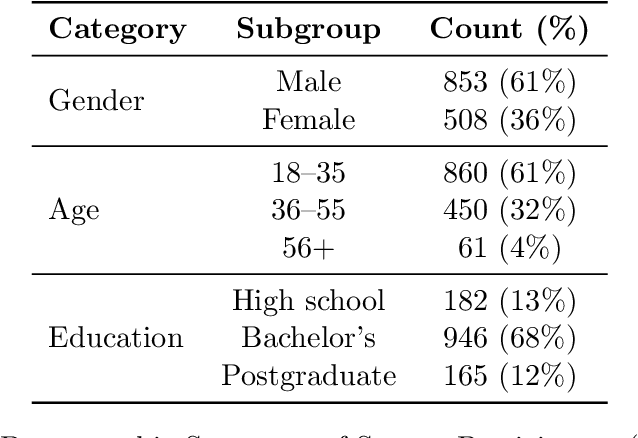
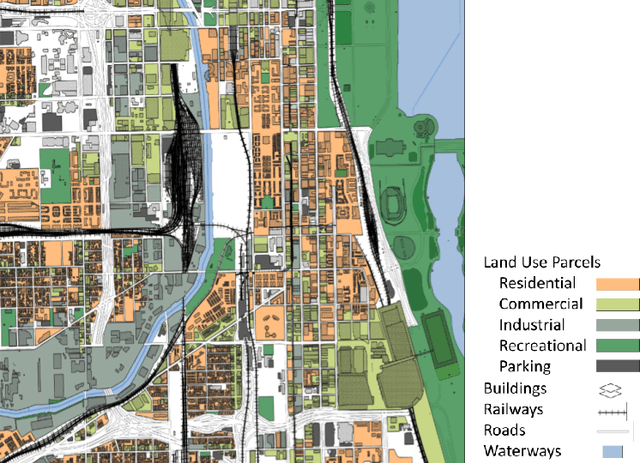
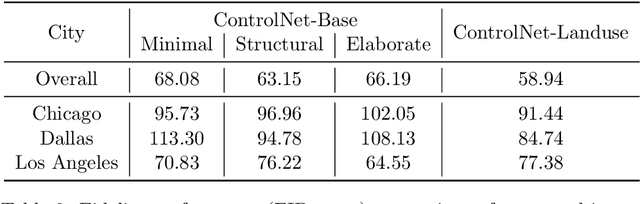
Generative AI offers new opportunities for automating urban planning by creating site-specific urban layouts and enabling flexible design exploration. However, existing approaches often struggle to produce realistic and practical designs at scale. Therefore, we adapt a state-of-the-art Stable Diffusion model, extended with ControlNet, to generate high-fidelity satellite imagery conditioned on land use descriptions, infrastructure, and natural environments. To overcome data availability limitations, we spatially link satellite imagery with structured land use and constraint information from OpenStreetMap. Using data from three major U.S. cities, we demonstrate that the proposed diffusion model generates realistic and diverse urban landscapes by varying land-use configurations, road networks, and water bodies, facilitating cross-city learning and design diversity. We also systematically evaluate the impacts of varying language prompts and control imagery on the quality of satellite imagery generation. Our model achieves high FID and KID scores and demonstrates robustness across diverse urban contexts. Qualitative assessments from urban planners and the general public show that generated images align closely with design descriptions and constraints, and are often preferred over real images. This work establishes a benchmark for controlled urban imagery generation and highlights the potential of generative AI as a tool for enhancing planning workflows and public engagement.
Reimagining Urban Science: Scaling Causal Inference with Large Language Models
Apr 15, 2025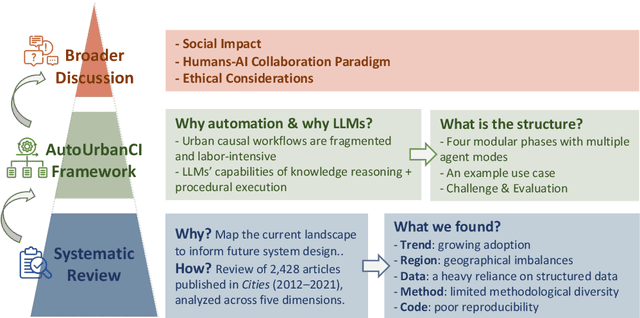
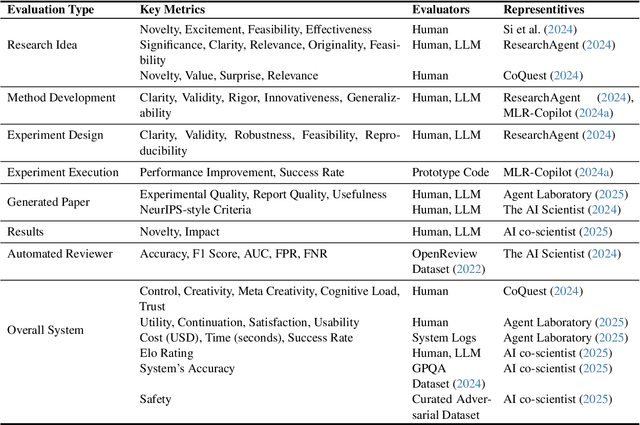
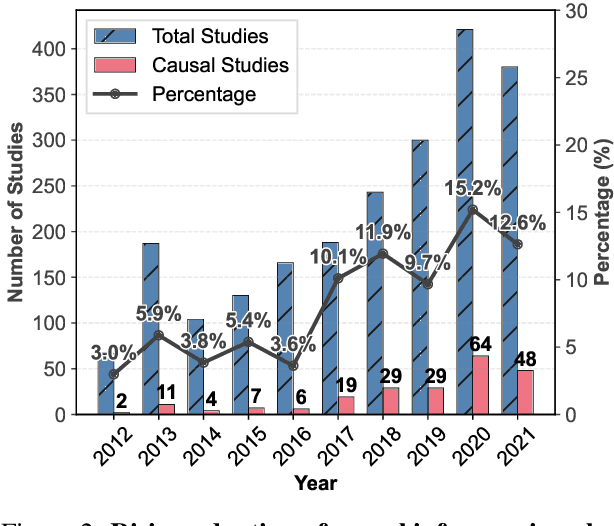

Urban causal research is essential for understanding the complex dynamics of cities and informing evidence-based policies. However, it is challenged by the inefficiency and bias of hypothesis generation, barriers to multimodal data complexity, and the methodological fragility of causal experimentation. Recent advances in large language models (LLMs) present an opportunity to rethink how urban causal analysis is conducted. This Perspective examines current urban causal research by analyzing taxonomies that categorize research topics, data sources, and methodological approaches to identify structural gaps. We then introduce an LLM-driven conceptual framework, AutoUrbanCI, composed of four distinct modular agents responsible for hypothesis generation, data engineering, experiment design and execution, and results interpretation with policy recommendations. We propose evaluation criteria for rigor and transparency and reflect on implications for human-AI collaboration, equity, and accountability. We call for a new research agenda that embraces AI-augmented workflows not as replacements for human expertise but as tools to broaden participation, improve reproducibility, and unlock more inclusive forms of urban causal reasoning.
Analyzing sequential activity and travel decisions with interpretable deep inverse reinforcement learning
Mar 17, 2025Travel demand modeling has shifted from aggregated trip-based models to behavior-oriented activity-based models because daily trips are essentially driven by human activities. To analyze the sequential activity-travel decisions, deep inverse reinforcement learning (DIRL) has proven effective in learning the decision mechanisms by approximating a reward function to represent preferences and a policy function to replicate observed behavior using deep neural networks (DNNs). However, most existing research has focused on using DIRL to enhance only prediction accuracy, with limited exploration into interpreting the underlying decision mechanisms guiding sequential decision-making. To address this gap, we introduce an interpretable DIRL framework for analyzing activity-travel decision processes, bridging the gap between data-driven machine learning and theory-driven behavioral models. Our proposed framework adapts an adversarial IRL approach to infer the reward and policy functions of activity-travel behavior. The policy function is interpreted through a surrogate interpretable model based on choice probabilities from the policy function, while the reward function is interpreted by deriving both short-term rewards and long-term returns for various activity-travel patterns. Our analysis of real-world travel survey data reveals promising results in two key areas: (i) behavioral pattern insights from the policy function, highlighting critical factors in decision-making and variations among socio-demographic groups, and (ii) behavioral preference insights from the reward function, indicating the utility individuals gain from specific activity sequences.