 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Fake-News Detection with Node-Level Topological Features
Dec 18, 2025In recent years, the proliferation of misinformation and fake news has posed serious threats to individuals and society, spurring intense research into automated detection methods. Previous work showed that integrating content, user preferences, and propagation structure achieves strong performance, but leaves all graph-level representation learning entirely to the GNN, hiding any explicit topological cues. To close this gap, we introduce a lightweight enhancement: for each node, we append two classical graph-theoretic metrics, degree centrality and local clustering coefficient, to its original BERT and profile embeddings, thus explicitly flagging the roles of hub and community. In the UPFD Politifact subset, this simple modification boosts macro F1 from 0.7753 to 0.8344 over the original baseline. Our study not only demonstrates the practical value of explicit topology features in fake-news detection but also provides an interpretable, easily reproducible template for fusing graph metrics in other information-diffusion tasks.
Generative AI for Urban Planning: Synthesizing Satellite Imagery via Diffusion Models
May 13, 2025
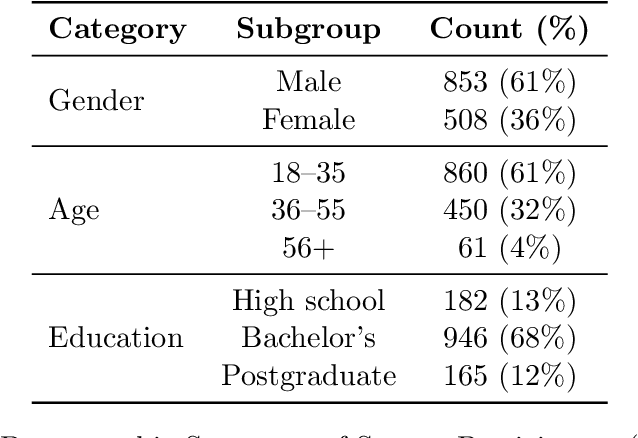
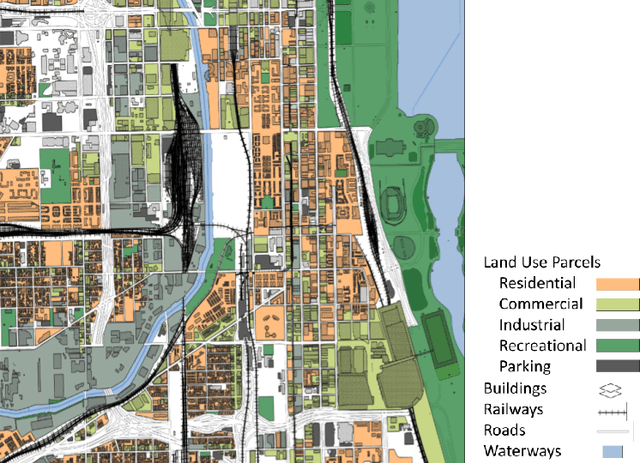
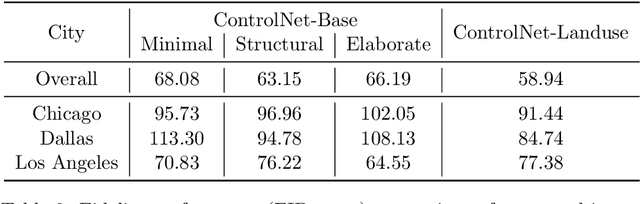
Generative AI offers new opportunities for automating urban planning by creating site-specific urban layouts and enabling flexible design exploration. However, existing approaches often struggle to produce realistic and practical designs at scale. Therefore, we adapt a state-of-the-art Stable Diffusion model, extended with ControlNet, to generate high-fidelity satellite imagery conditioned on land use descriptions, infrastructure, and natural environments. To overcome data availability limitations, we spatially link satellite imagery with structured land use and constraint information from OpenStreetMap. Using data from three major U.S. cities, we demonstrate that the proposed diffusion model generates realistic and diverse urban landscapes by varying land-use configurations, road networks, and water bodies, facilitating cross-city learning and design diversity. We also systematically evaluate the impacts of varying language prompts and control imagery on the quality of satellite imagery generation. Our model achieves high FID and KID scores and demonstrates robustness across diverse urban contexts. Qualitative assessments from urban planners and the general public show that generated images align closely with design descriptions and constraints, and are often preferred over real images. This work establishes a benchmark for controlled urban imagery generation and highlights the potential of generative AI as a tool for enhancing planning workflows and public engagement.
Comparison of Centralized and Decentralized Approaches in Cooperative Coverage Problems with Energy-Constrained Agents
Aug 26, 2020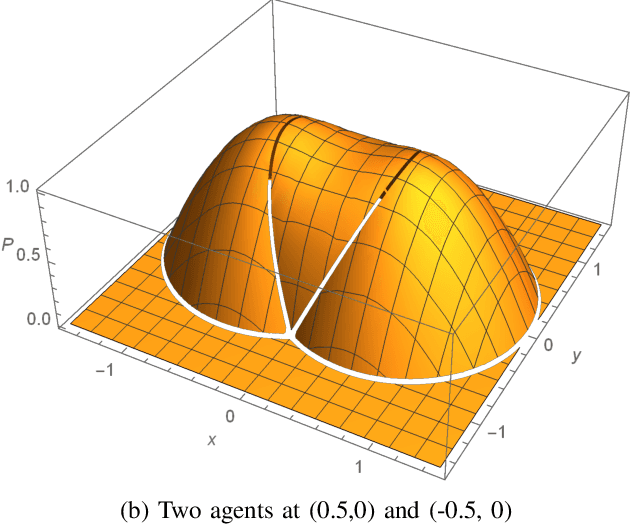
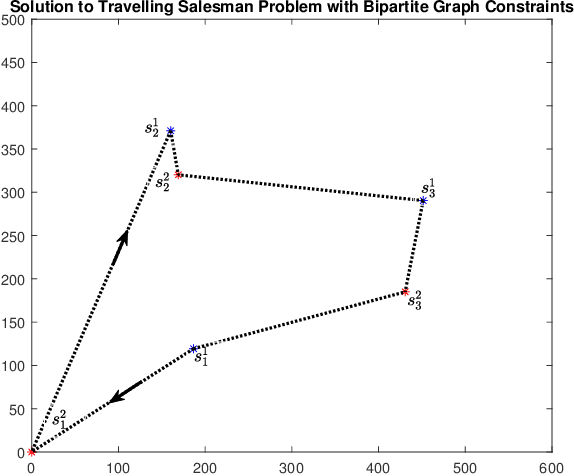
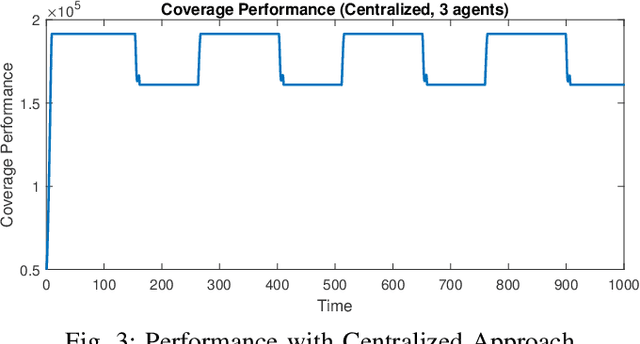
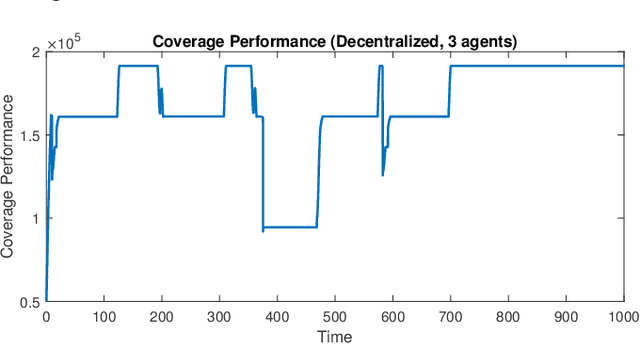
A multi-agent coverage problem is considered with energy-constrained agents. The objective of this paper is to compare the coverage performance between centralized and decentralized approaches. To this end, a near-optimal centralized coverage control method is developed under energy depletion and repletion constraints. The optimal coverage formation corresponds to the locations of agents where the coverage performance is maximized. The optimal charging formation corresponds to the locations of agents with one agent fixed at the charging station and the remaining agents maximizing the coverage performance. We control the behavior of this cooperative multi-agent system by switching between the optimal coverage formation and the optimal charging formation. Finally, the optimal dwell times at coverage locations, charging time, and agent trajectories are determined so as to maximize coverage over a given time interval. In particular, our controller guarantees that at any time there is at most one agent leaving the team for energy repletion.
Adaptive Adversarial Logits Pairing
May 25, 2020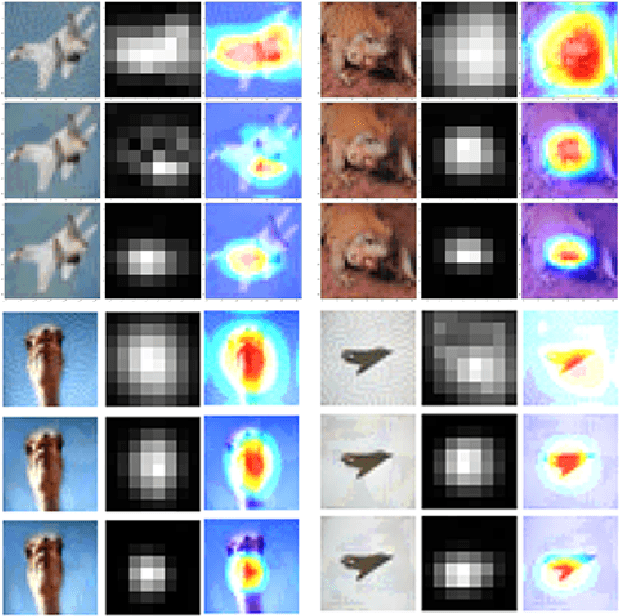
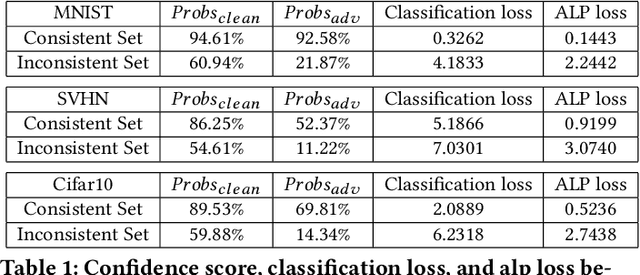
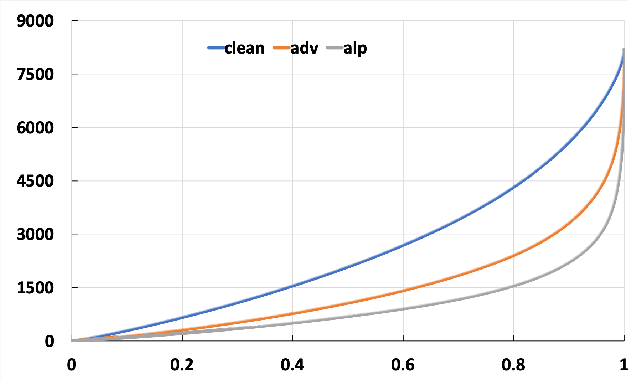
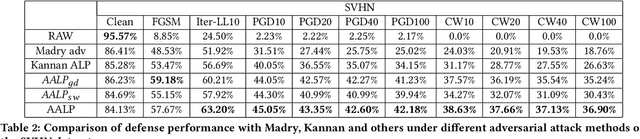
Adversarial examples provide an opportunity as well as impose a challenge for understanding image classification systems. Based on the analysis of state-of-the-art defense solution Adversarial Logits Pairing (ALP), we observed in this work that: (1) The inference of adversarially robust models tends to rely on fewer high-contribution features compared with vulnerable ones. (2) The training target of ALP doesn't fit well to a noticeable part of samples, where the logits pairing loss is overemphasized and obstructs minimizing the classification loss. Motivated by these observations, we designed an Adaptive Adversarial Logits Pairing (AALP) solution by modifying the training process and training target of ALP. Specifically, AALP consists of an adaptive feature optimization module with Guided Dropout to systematically pursue few high-contribution features, and an adaptive sample weighting module by setting sample-specific training weights to balance between logits pairing loss and classification loss. The proposed AALP solution demonstrates superior defense performance on multiple datasets with extensive experiments.
Butterfly detection and classification based on integrated YOLO algorithm
Jan 02, 2020


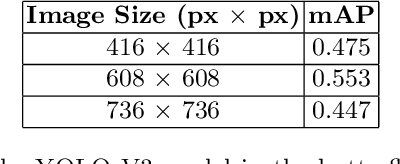
Insects are abundant species on the earth, and the task of identification and identification of insects is complex and arduous. How to apply artificial intelligence technology and digital image processing methods to automatic identification of insect species is a hot issue in current research. In this paper, the problem of automatic detection and classification recognition of butterfly photographs is studied, and a method of bio-labeling suitable for butterfly classification is proposed. On the basis of YOLO algorithm, by synthesizing the results of YOLO models with different training mechanisms, a butterfly automatic detection and classification recognition algorithm based on YOLO algorithm is proposed. It greatly improves the generalization ability of YOLO algorithm and makes it have better ability to solve small sample problems. The experimental results show that the proposed annotation method and integrated YOLO algorithm have high accuracy and recognition rate in butterfly automatic detection and recognition.
blessing in disguise: Designing Robust Turing Test by Employing Algorithm Unrobustness
Apr 22, 2019
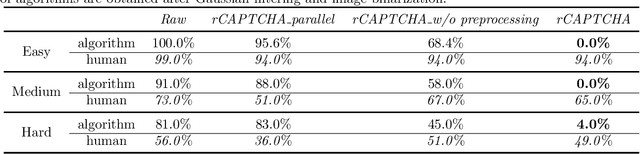
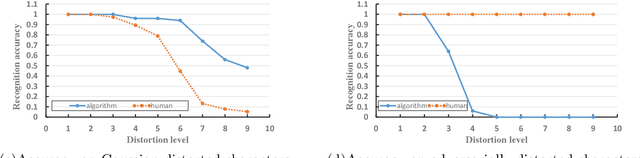
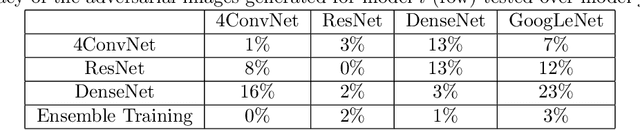
Turing test was originally proposed to examine whether machine's behavior is indistinguishable from a human. The most popular and practical Turing test is CAPTCHA, which is to discriminate algorithm from human by offering recognition-alike questions. The recent development of deep learning has significantly advanced the capability of algorithm in solving CAPTCHA questions, forcing CAPTCHA designers to increase question complexity. Instead of designing questions difficult for both algorithm and human, this study attempts to employ the limitations of algorithm to design robust CAPTCHA questions easily solvable to human. Specifically, our data analysis observes that human and algorithm demonstrates different vulnerability to visual distortions: adversarial perturbation is significantly annoying to algorithm yet friendly to human. We are motivated to employ adversarially perturbed images for robust CAPTCHA design in the context of character-based questions. Three modules of multi-target attack, ensemble adversarial training, and image preprocessing differentiable approximation are proposed to address the characteristics of character-based CAPTCHA cracking. Qualitative and quantitative experimental results demonstrate the effectiveness of the proposed solution. We hope this study can lead to the discussions around adversarial attack/defense in CAPTCHA design and also inspire the future attempts in employing algorithm limitation for practical usage.
Attention, Please! Adversarial Defense via Attention Rectification and Preservation
Nov 24, 2018



This study provides a new understanding of the adversarial attack problem by examining the correlation between adversarial attack and visual attention change. In particular, we observed that: (1) images with incomplete attention regions are more vulnerable to adversarial attacks; and (2) successful adversarial attacks lead to deviated and scattered attention map. Accordingly, an attention-based adversarial defense framework is designed to simultaneously rectify the attention map for prediction and preserve the attention area between adversarial and original images. The problem of adding iteratively attacked samples is also discussed in the context of visual attention change. We hope the attention-related data analysis and defense solution in this study will shed some light on the mechanism behind the adversarial attack and also facilitate future adversarial defense/attack model design.
Deep neural network based i-vector mapping for speaker verification using short utterances
Oct 16, 2018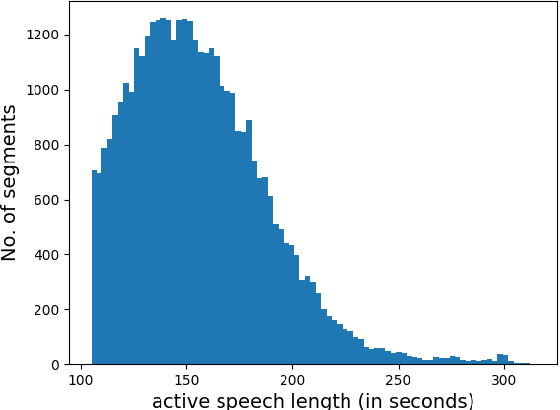
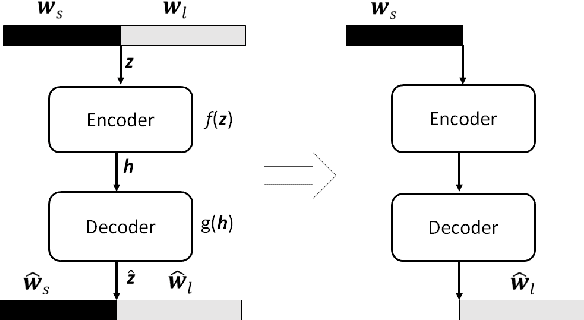

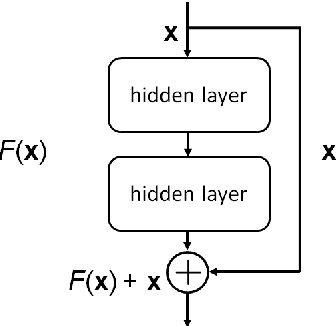
Text-independent speaker recognition using short utterances is a highly challenging task due to the large variation and content mismatch between short utterances. I-vector based systems have become the standard in speaker verification applications, but they are less effective with short utterances. In this paper, we first compare two state-of-the-art universal background model training methods for i-vector modeling using full-length and short utterance evaluation tasks. The two methods are Gaussian mixture model (GMM) based and deep neural network (DNN) based methods. The results indicate that the I-vector_DNN system outperforms the I-vector_GMM system under various durations. However, the performances of both systems degrade significantly as the duration of the utterances decreases. To address this issue, we propose two novel nonlinear mapping methods which train DNN models to map the i-vectors extracted from short utterances to their corresponding long-utterance i-vectors. The mapped i-vector can restore missing information and reduce the variance of the original short-utterance i-vectors. The proposed methods both model the joint representation of short and long utterance i-vectors by using autoencoder. Experimental results using the NIST SRE 2010 dataset show that both methods provide significant improvement and result in a max of 28.43% relative improvement in Equal Error Rates from a baseline system, when using deep encoder with residual blocks and adding an additional phoneme vector. When further testing the best-validated models of SRE10 on the Speaker In The Wild dataset, the methods result in a 23.12% improvement on arbitrary-duration (1-5 s) short-utterance conditions.