 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep neural network based i-vector mapping for speaker verification using short utterances
Oct 16, 2018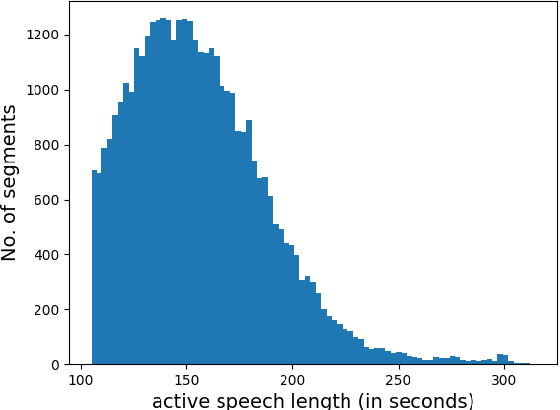
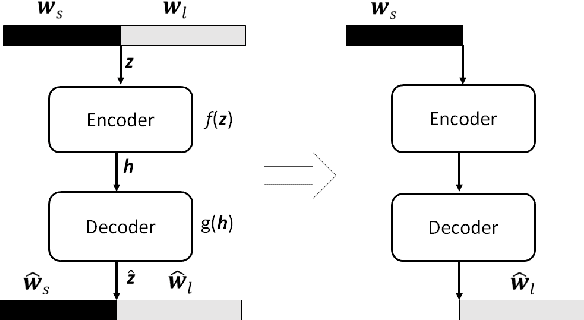

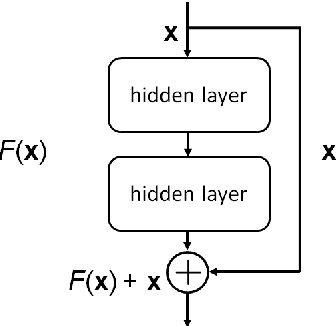
Text-independent speaker recognition using short utterances is a highly challenging task due to the large variation and content mismatch between short utterances. I-vector based systems have become the standard in speaker verification applications, but they are less effective with short utterances. In this paper, we first compare two state-of-the-art universal background model training methods for i-vector modeling using full-length and short utterance evaluation tasks. The two methods are Gaussian mixture model (GMM) based and deep neural network (DNN) based methods. The results indicate that the I-vector_DNN system outperforms the I-vector_GMM system under various durations. However, the performances of both systems degrade significantly as the duration of the utterances decreases. To address this issue, we propose two novel nonlinear mapping methods which train DNN models to map the i-vectors extracted from short utterances to their corresponding long-utterance i-vectors. The mapped i-vector can restore missing information and reduce the variance of the original short-utterance i-vectors. The proposed methods both model the joint representation of short and long utterance i-vectors by using autoencoder. Experimental results using the NIST SRE 2010 dataset show that both methods provide significant improvement and result in a max of 28.43% relative improvement in Equal Error Rates from a baseline system, when using deep encoder with residual blocks and adding an additional phoneme vector. When further testing the best-validated models of SRE10 on the Speaker In The Wild dataset, the methods result in a 23.12% improvement on arbitrary-duration (1-5 s) short-utterance conditions.