 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorRefine: Synergy-Manipulation Based on Trajectory Anchor and Residual Refinement for Vision-Language-Action Models
Apr 20, 2026Precision-critical manipulation requires both global trajectory organization and local execution correction, yet most vision-language-action (VLA) policies generate actions within a single unified space. This monolithic formulation forces macro-level transport and micro-level refinement to be optimized under the same objective, causing large motions to dominate learning while suppressing small but failure-critical corrective signals. In contrast, human manipulation is structured by global movement planning together with continuous local adjustment during execution. Motivated by this principle, we propose AnchorRefine, a hierarchical framework that factorizes VLA action modeling into trajectory anchor and residual refinement. The anchor planner predicts a coarse motion scaffold, while the refinement module corrects execution-level deviations to improve geometric and contact precision. We further introduce a decision-aware gripper refinement mechanism to better capture the discrete and boundary-sensitive nature of gripper control. Experiments on LIBERO, CALVIN, and real-robot tasks demonstrate that AnchorRefine consistently improves both regression-based and diffusion-based VLA backbones, yielding gains of up to 7.8% in simulation success rate and 18% in real-world success rate.
TagaVLM: Topology-Aware Global Action Reasoning for Vision-Language Navigation
Mar 03, 2026Vision-Language Navigation (VLN) presents a unique challenge for Large Vision-Language Models (VLMs) due to their inherent architectural mismatch: VLMs are primarily pretrained on static, disembodied vision-language tasks, which fundamentally clash with the dynamic, embodied, and spatially-structured nature of navigation. Existing large-model-based methods often resort to converting rich visual and spatial information into text, forcing models to implicitly infer complex visual-topological relationships or limiting their global action capabilities. To bridge this gap, we propose TagaVLM (Topology-Aware Global Action reasoning), an end-to-end framework that explicitly injects topological structures into the VLM backbone. To introduce topological edge information, Spatial Topology Aware Residual Attention (STAR-Att) directly integrates it into the VLM's self-attention mechanism, enabling intrinsic spatial reasoning while preserving pretrained knowledge. To enhance topological node information, an Interleaved Navigation Prompt strengthens node-level visual-text alignment. Finally, with the embedded topological graph, the model is capable of global action reasoning, allowing for robust path correction. On the R2R benchmark, TagaVLM achieves state-of-the-art performance among large-model-based methods, with a Success Rate (SR) of 51.09% and SPL of 47.18 in unseen environments, outperforming prior work by 3.39% in SR and 9.08 in SPL. This demonstrates that, for embodied spatial reasoning, targeted enhancements on smaller open-source VLMs can be more effective than brute-force model scaling. The code will be released upon publication.Project page: https://apex-bjut.github.io/Taga-VLM
Visual and Semantic Prompt Collaboration for Generalized Zero-Shot Learning
Mar 29, 2025Generalized zero-shot learning aims to recognize both seen and unseen classes with the help of semantic information that is shared among different classes. It inevitably requires consistent visual-semantic alignment. Existing approaches fine-tune the visual backbone by seen-class data to obtain semantic-related visual features, which may cause overfitting on seen classes with a limited number of training images. This paper proposes a novel visual and semantic prompt collaboration framework, which utilizes prompt tuning techniques for efficient feature adaptation. Specifically, we design a visual prompt to integrate the visual information for discriminative feature learning and a semantic prompt to integrate the semantic formation for visualsemantic alignment. To achieve effective prompt information integration, we further design a weak prompt fusion mechanism for the shallow layers and a strong prompt fusion mechanism for the deep layers in the network. Through the collaboration of visual and semantic prompts, we can obtain discriminative semantic-related features for generalized zero-shot image recognition. Extensive experiments demonstrate that our framework consistently achieves favorable performance in both conventional zero-shot learning and generalized zero-shot learning benchmarks compared to other state-of-the-art methods.
HC-LLM: Historical-Constrained Large Language Models for Radiology Report Generation
Dec 15, 2024



Radiology report generation (RRG) models typically focus on individual exams, often overlooking the integration of historical visual or textual data, which is crucial for patient follow-ups. Traditional methods usually struggle with long sequence dependencies when incorporating historical information, but large language models (LLMs) excel at in-context learning, making them well-suited for analyzing longitudinal medical data. In light of this, we propose a novel Historical-Constrained Large Language Models (HC-LLM) framework for RRG, empowering LLMs with longitudinal report generation capabilities by constraining the consistency and differences between longitudinal images and their corresponding reports. Specifically, our approach extracts both time-shared and time-specific features from longitudinal chest X-rays and diagnostic reports to capture disease progression. Then, we ensure consistent representation by applying intra-modality similarity constraints and aligning various features across modalities with multimodal contrastive and structural constraints. These combined constraints effectively guide the LLMs in generating diagnostic reports that accurately reflect the progression of the disease, achieving state-of-the-art results on the Longitudinal-MIMIC dataset. Notably, our approach performs well even without historical data during testing and can be easily adapted to other multimodal large models, enhancing its versatility.
Adapter-Enhanced Semantic Prompting for Continual Learning
Dec 15, 2024



Continual learning (CL) enables models to adapt to evolving data streams. A major challenge of CL is catastrophic forgetting, where new knowledge will overwrite previously acquired knowledge. Traditional methods usually retain the past data for replay or add additional branches in the model to learn new knowledge, which has high memory requirements. In this paper, we propose a novel lightweight CL framework, Adapter-Enhanced Semantic Prompting (AESP), which integrates prompt tuning and adapter techniques. Specifically, we design semantic-guided prompts to enhance the generalization ability of visual features and utilize adapters to efficiently fuse the semantic information, aiming to learn more adaptive features for the continual learning task. Furthermore, to choose the right task prompt for feature adaptation, we have developed a novel matching mechanism for prompt selection. Extensive experiments on three CL datasets demonstrate that our approach achieves favorable performance across multiple metrics, showing its potential for advancing CL.
Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification
Jul 14, 2024
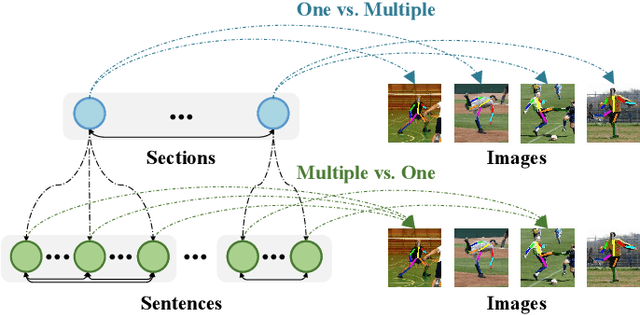
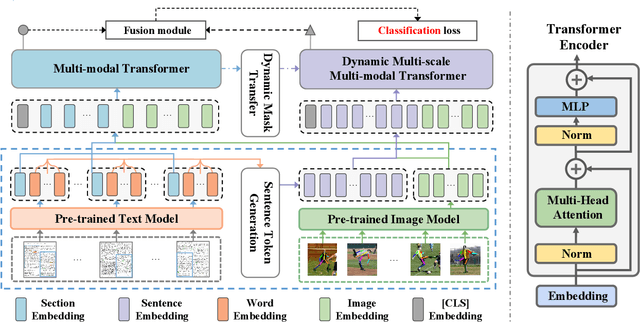
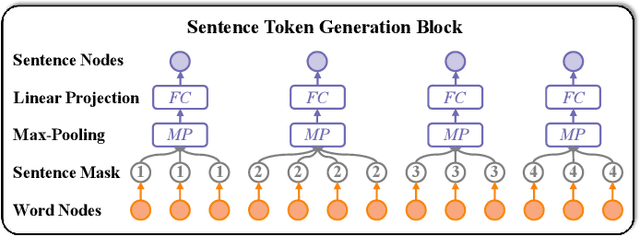
Long Document Classification (LDC) has gained significant attention recently. However, multi-modal data in long documents such as texts and images are not being effectively utilized. Prior studies in this area have attempted to integrate texts and images in document-related tasks, but they have only focused on short text sequences and images of pages. How to classify long documents with hierarchical structure texts and embedding images is a new problem and faces multi-modal representation difficulties. In this paper, we propose a novel approach called Hierarchical Multi-modal Transformer (HMT) for cross-modal long document classification. The HMT conducts multi-modal feature interaction and fusion between images and texts in a hierarchical manner. Our approach uses a multi-modal transformer and a dynamic multi-scale multi-modal transformer to model the complex relationships between image features, and the section and sentence features. Furthermore, we introduce a new interaction strategy called the dynamic mask transfer module to integrate these two transformers by propagating features between them. To validate our approach, we conduct cross-modal LDC experiments on two newly created and two publicly available multi-modal long document datasets, and the results show that the proposed HMT outperforms state-of-the-art single-modality and multi-modality methods.
Query-Enhanced Adaptive Semantic Path Reasoning for Inductive Knowledge Graph Completion
Jun 04, 2024Conventional Knowledge graph completion (KGC) methods aim to infer missing information in incomplete Knowledge Graphs (KGs) by leveraging existing information, which struggle to perform effectively in scenarios involving emerging entities. Inductive KGC methods can handle the emerging entities and relations in KGs, offering greater dynamic adaptability. While existing inductive KGC methods have achieved some success, they also face challenges, such as susceptibility to noisy structural information during reasoning and difficulty in capturing long-range dependencies in reasoning paths. To address these challenges, this paper proposes the Query-Enhanced Adaptive Semantic Path Reasoning (QASPR) framework, which simultaneously captures both the structural and semantic information of KGs to enhance the inductive KGC task. Specifically, the proposed QASPR employs a query-dependent masking module to adaptively mask noisy structural information while retaining important information closely related to the targets. Additionally, QASPR introduces a global semantic scoring module that evaluates both the individual contributions and the collective impact of nodes along the reasoning path within KGs. The experimental results demonstrate that QASPR achieves state-of-the-art performance.
Large Language Models-guided Dynamic Adaptation for Temporal Knowledge Graph Reasoning
May 23, 2024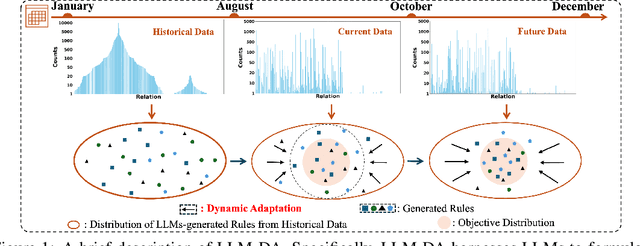
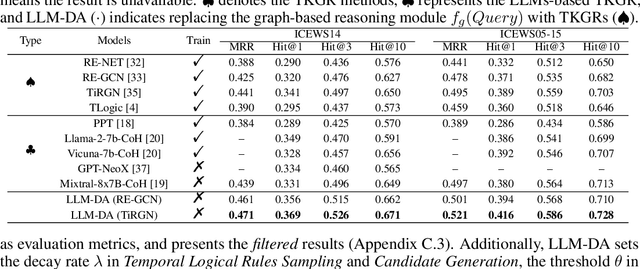
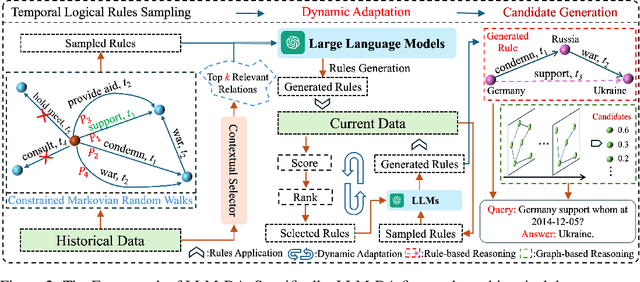

Temporal Knowledge Graph Reasoning (TKGR) is the process of utilizing temporal information to capture complex relations within a Temporal Knowledge Graph (TKG) to infer new knowledge. Conventional methods in TKGR typically depend on deep learning algorithms or temporal logical rules. However, deep learning-based TKGRs often lack interpretability, whereas rule-based TKGRs struggle to effectively learn temporal rules that capture temporal patterns. Recently, Large Language Models (LLMs) have demonstrated extensive knowledge and remarkable proficiency in temporal reasoning. Consequently, the employment of LLMs for Temporal Knowledge Graph Reasoning (TKGR) has sparked increasing interest among researchers. Nonetheless, LLMs are known to function as black boxes, making it challenging to comprehend their reasoning process. Additionally, due to the resource-intensive nature of fine-tuning, promptly updating LLMs to integrate evolving knowledge within TKGs for reasoning is impractical. To address these challenges, in this paper, we propose a Large Language Models-guided Dynamic Adaptation (LLM-DA) method for reasoning on TKGs. Specifically, LLM-DA harnesses the capabilities of LLMs to analyze historical data and extract temporal logical rules. These rules unveil temporal patterns and facilitate interpretable reasoning. To account for the evolving nature of TKGs, a dynamic adaptation strategy is proposed to update the LLM-generated rules with the latest events. This ensures that the extracted rules always incorporate the most recent knowledge and better generalize to the predictions on future events. Experimental results show that without the need of fine-tuning, LLM-DA significantly improves the accuracy of reasoning over several common datasets, providing a robust framework for TKGR tasks.
Center Focusing Network for Real-Time LiDAR Panoptic Segmentation
Nov 16, 2023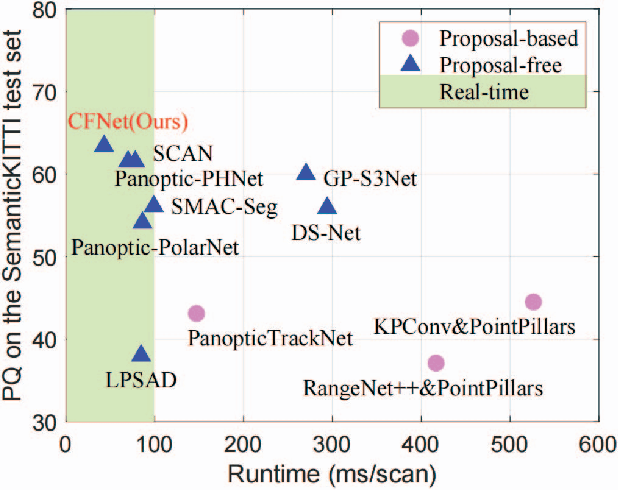
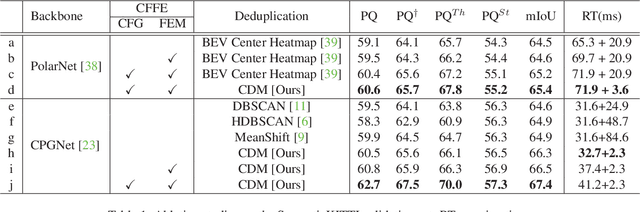
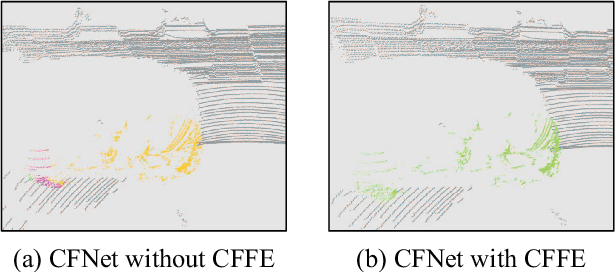
LiDAR panoptic segmentation facilitates an autonomous vehicle to comprehensively understand the surrounding objects and scenes and is required to run in real time. The recent proposal-free methods accelerate the algorithm, but their effectiveness and efficiency are still limited owing to the difficulty of modeling non-existent instance centers and the costly center-based clustering modules. To achieve accurate and real-time LiDAR panoptic segmentation, a novel center focusing network (CFNet) is introduced. Specifically, the center focusing feature encoding (CFFE) is proposed to explicitly understand the relationships between the original LiDAR points and virtual instance centers by shifting the LiDAR points and filling in the center points. Moreover, to leverage the redundantly detected centers, a fast center deduplication module (CDM) is proposed to select only one center for each instance. Experiments on the SemanticKITTI and nuScenes panoptic segmentation benchmarks demonstrate that our CFNet outperforms all existing methods by a large margin and is 1.6 times faster than the most efficient method. The code is available at https://github.com/GangZhang842/CFNet.
A Survey on Temporal Knowledge Graph Completion: Taxonomy, Progress, and Prospects
Aug 04, 2023Temporal characteristics are prominently evident in a substantial volume of knowledge, which underscores the pivotal role of Temporal Knowledge Graphs (TKGs) in both academia and industry. However, TKGs often suffer from incompleteness for three main reasons: the continuous emergence of new knowledge, the weakness of the algorithm for extracting structured information from unstructured data, and the lack of information in the source dataset. Thus, the task of Temporal Knowledge Graph Completion (TKGC) has attracted increasing attention, aiming to predict missing items based on the available information. In this paper, we provide a comprehensive review of TKGC methods and their details. Specifically, this paper mainly consists of three components, namely, 1)Background, which covers the preliminaries of TKGC methods, loss functions required for training, as well as the dataset and evaluation protocol; 2)Interpolation, that estimates and predicts the missing elements or set of elements through the relevant available information. It further categorizes related TKGC methods based on how to process temporal information; 3)Extrapolation, which typically focuses on continuous TKGs and predicts future events, and then classifies all extrapolation methods based on the algorithms they utilize. We further pinpoint the challenges and discuss future research directions of TKGC.