 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Geometric Framework for Absolute Pose and Velocity Estimation with Event Cameras
Jun 08, 2026Despite the rapid advancements in event-based motion estimation, current geometric methods primarily focus on velocity estimation. However, absolute pose estimation, which is equally crucial for key applications such as robotic navigation and augmented reality, remains relatively underexplored. Consequently, the simultaneous recovery of absolute pose and velocity from event streams remains an open and challenging problem. To address this gap, we propose a geometric framework for absolute pose and velocity estimation by leveraging 3D lines in the scene and the events they trigger. At the core of the framework lie two key geometric constraints: the orthogonality between a 3D line and the normal vector of its corresponding event plane, and the collinearity of an event with the 2D projection of its associated line. Based on these constraints, we present both linear and polynomial solvers for absolute pose estimation. The former enables efficient computation, while the latter provides a globally optimal solution for rotation. For velocity estimation, we develop an efficient linear solver and a more accurate optimization-based solver to recover both angular and linear velocities. Notably, our methods require a minimum of three event-line correspondences to determine the 6-DoF absolute pose or velocities independently. Extensive experiments in simulation and on real-world datasets demonstrate that our methods achieve state-of-the-art performance, with significant improvements in accuracy and computational efficiency compared to existing methods. The demo code is publicly available at https://github.com/Zibin6/EventPoseVelocity.
SecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Late-to-Early Training: LET LLMs Learn Earlier, So Faster and Better
Feb 05, 2026As Large Language Models (LLMs) achieve remarkable empirical success through scaling model and data size, pretraining has become increasingly critical yet computationally prohibitive, hindering rapid development. Despite the availability of numerous pretrained LLMs developed at significant computational expense, a fundamental real-world question remains underexplored: \textit{Can we leverage existing small pretrained models to accelerate the training of larger models?} In this paper, we propose a Late-to-Early Training (LET) paradigm that enables LLMs to explicitly learn later knowledge in earlier steps and earlier layers. The core idea is to guide the early layers of an LLM during early training using representations from the late layers of a pretrained (i.e. late training phase) model. We identify two key mechanisms that drive LET's effectiveness: late-to-early-step learning and late-to-early-layer learning. These mechanisms significantly accelerate training convergence while robustly enhancing both language modeling capabilities and downstream task performance, enabling faster training with superior performance. Extensive experiments on 1.4B and 7B parameter models demonstrate LET's efficiency and effectiveness. Notably, when training a 1.4B LLM on the Pile dataset, our method achieves up to 1.6$\times$ speedup with nearly 5\% improvement in downstream task accuracy compared to standard training, even when using a pretrained model with 10$\times$ fewer parameters than the target model.
General-Purpose Aerial Intelligent Agents Empowered by Large Language Models
Mar 11, 2025The emergence of large language models (LLMs) opens new frontiers for unmanned aerial vehicle (UAVs), yet existing systems remain confined to predefined tasks due to hardware-software co-design challenges. This paper presents the first aerial intelligent agent capable of open-world task execution through tight integration of LLM-based reasoning and robotic autonomy. Our hardware-software co-designed system addresses two fundamental limitations: (1) Onboard LLM operation via an edge-optimized computing platform, achieving 5-6 tokens/sec inference for 14B-parameter models at 220W peak power; (2) A bidirectional cognitive architecture that synergizes slow deliberative planning (LLM task planning) with fast reactive control (state estimation, mapping, obstacle avoidance, and motion planning). Validated through preliminary results using our prototype, the system demonstrates reliable task planning and scene understanding in communication-constrained environments, such as sugarcane monitoring, power grid inspection, mine tunnel exploration, and biological observation applications. This work establishes a novel framework for embodied aerial artificial intelligence, bridging the gap between task planning and robotic autonomy in open environments.
Full-DoF Egomotion Estimation for Event Cameras Using Geometric Solvers
Mar 05, 2025For event cameras, current sparse geometric solvers for egomotion estimation assume that the rotational displacements are known, such as those provided by an IMU. Thus, they can only recover the translational motion parameters. Recovering full-DoF motion parameters using a sparse geometric solver is a more challenging task, and has not yet been investigated. In this paper, we propose several solvers to estimate both rotational and translational velocities within a unified framework. Our method leverages event manifolds induced by line segments. The problem formulations are based on either an incidence relation for lines or a novel coplanarity relation for normal vectors. We demonstrate the possibility of recovering full-DoF egomotion parameters for both angular and linear velocities without requiring extra sensor measurements or motion priors. To achieve efficient optimization, we exploit the Adam framework with a first-order approximation of rotations for quick initialization. Experiments on both synthetic and real-world data demonstrate the effectiveness of our method. The code is available at https://github.com/jizhaox/relpose-event.
Adapter-Enhanced Semantic Prompting for Continual Learning
Dec 15, 2024



Continual learning (CL) enables models to adapt to evolving data streams. A major challenge of CL is catastrophic forgetting, where new knowledge will overwrite previously acquired knowledge. Traditional methods usually retain the past data for replay or add additional branches in the model to learn new knowledge, which has high memory requirements. In this paper, we propose a novel lightweight CL framework, Adapter-Enhanced Semantic Prompting (AESP), which integrates prompt tuning and adapter techniques. Specifically, we design semantic-guided prompts to enhance the generalization ability of visual features and utilize adapters to efficiently fuse the semantic information, aiming to learn more adaptive features for the continual learning task. Furthermore, to choose the right task prompt for feature adaptation, we have developed a novel matching mechanism for prompt selection. Extensive experiments on three CL datasets demonstrate that our approach achieves favorable performance across multiple metrics, showing its potential for advancing CL.
Online Temporal Fusion for Vectorized Map Construction in Mapless Autonomous Driving
Sep 01, 2024To reduce the reliance on high-definition (HD) maps, a growing trend in autonomous driving is leveraging on-board sensors to generate vectorized maps online. However, current methods are mostly constrained by processing only single-frame inputs, which hampers their robustness and effectiveness in complex scenarios. To overcome this problem, we propose an online map construction system that exploits the long-term temporal information to build a consistent vectorized map. First, the system efficiently fuses all historical road marking detections from an off-the-shelf network into a semantic voxel map, which is implemented using a hashing-based strategy to exploit the sparsity of road elements. Then reliable voxels are found by examining the fused information and incrementally clustered into an instance-level representation of road markings. Finally, the system incorporates domain knowledge to estimate the geometric and topological structures of roads, which can be directly consumed by the planning and control (PnC) module. Through experiments conducted in complicated urban environments, we have demonstrated that the output of our system is more consistent and accurate than the network output by a large margin and can be effectively used in a closed-loop autonomous driving system.
Enhancing Vectorized Map Perception with Historical Rasterized Maps
Sep 01, 2024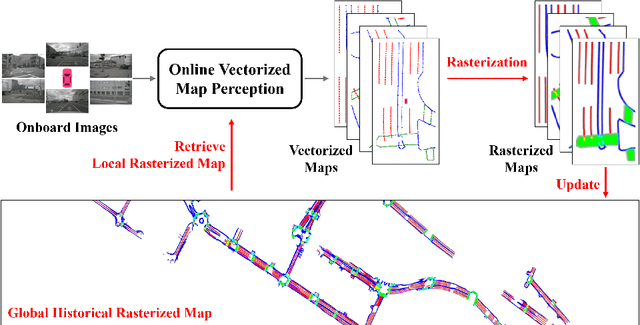
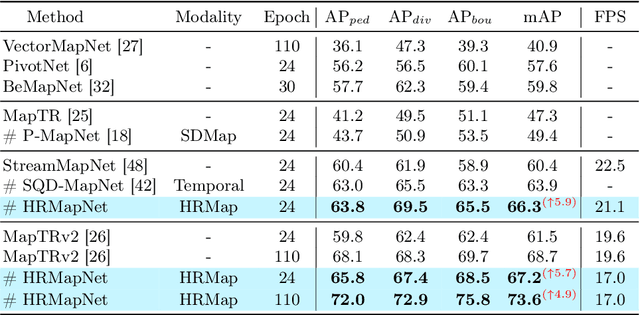
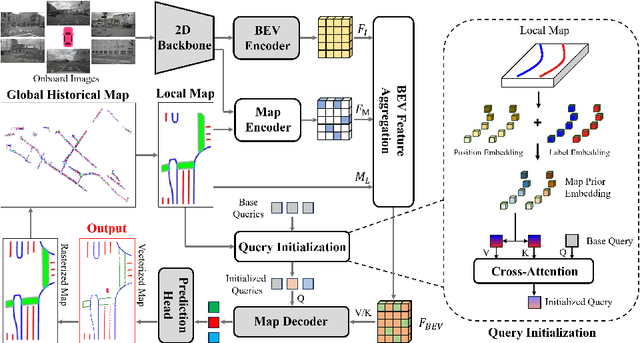
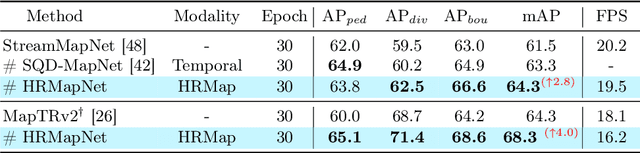
In autonomous driving, there is growing interest in end-to-end online vectorized map perception in bird's-eye-view (BEV) space, with an expectation that it could replace traditional high-cost offline high-definition (HD) maps. However, the accuracy and robustness of these methods can be easily compromised in challenging conditions, such as occlusion or adverse weather, when relying only on onboard sensors. In this paper, we propose HRMapNet, leveraging a low-cost Historical Rasterized Map to enhance online vectorized map perception. The historical rasterized map can be easily constructed from past predicted vectorized results and provides valuable complementary information. To fully exploit a historical map, we propose two novel modules to enhance BEV features and map element queries. For BEV features, we employ a feature aggregation module to encode features from both onboard images and the historical map. For map element queries, we design a query initialization module to endow queries with priors from the historical map. The two modules contribute to leveraging map information in online perception. Our HRMapNet can be integrated with most online vectorized map perception methods. We integrate it in two state-of-the-art methods, significantly improving their performance on both the nuScenes and Argoverse 2 datasets. The source code is released at https://github.com/HXMap/HRMapNet.
Six-Point Method for Multi-Camera Systems with Reduced Solution Space
Feb 28, 2024



Relative pose estimation using point correspondences (PC) is a widely used technique. A minimal configuration of six PCs is required for generalized cameras. In this paper, we present several minimal solvers that use six PCs to compute the 6DOF relative pose of a multi-camera system, including a minimal solver for the generalized camera and two minimal solvers for the practical configuration of two-camera rigs. The equation construction is based on the decoupling of rotation and translation. Rotation is represented by Cayley or quaternion parametrization, and translation can be eliminated by using the hidden variable technique. Ray bundle constraints are found and proven when a subset of PCs relate the same cameras across two views. This is the key to reducing the number of solutions and generating numerically stable solvers. Moreover, all configurations of six-point problems for multi-camera systems are enumerated. Extensive experiments demonstrate that our solvers are more accurate than the state-of-the-art six-point methods, while achieving better performance in efficiency.
Leveraging Enhanced Queries of Point Sets for Vectorized Map Construction
Feb 27, 2024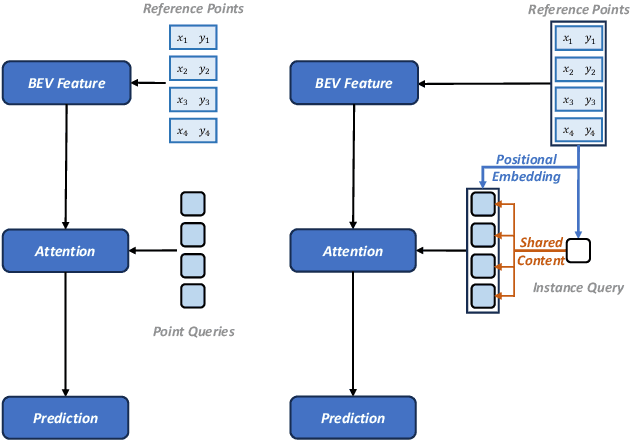
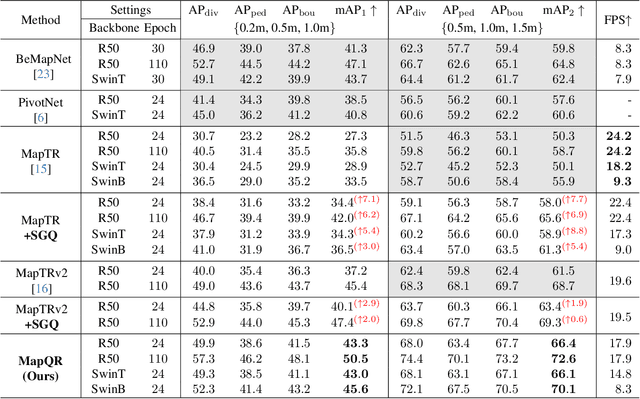

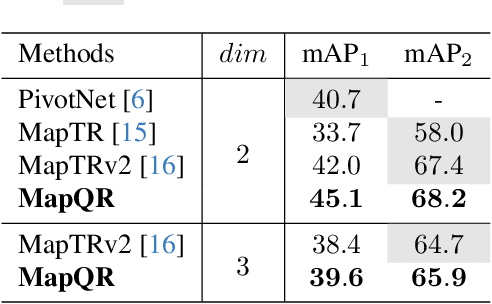
In autonomous driving, the high-definition (HD) map plays a crucial role in localization and planning. Recently, several methods have facilitated end-to-end online map construction in DETR-like frameworks. However, little attention has been paid to the potential capabilities of exploring the query mechanism. This paper introduces MapQR, an end-to-end method with an emphasis on enhancing query capabilities for constructing online vectorized maps. Although the map construction is essentially a point set prediction task, MapQR utilizes instance queries rather than point queries. These instance queries are scattered for the prediction of point sets and subsequently gathered for the final matching. This query design, called the scatter-and-gather query, shares content information in the same map element and avoids possible inconsistency of content information in point queries. We further exploit prior information to enhance an instance query by adding positional information embedded from their reference points. Together with a simple and effective improvement of a BEV encoder, the proposed MapQR achieves the best mean average precision (mAP) and maintains good efficiency on both nuScenes and Argoverse 2. In addition, integrating our query design into other models can boost their performance significantly. The code will be available at https://github.com/HXMap/MapQR.