 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Motif-aware Graph Test-time Adaptation for OOD Blockchain Anomaly Detection
May 28, 2026Ever-evolving transaction patterns have significantly hindered anomaly detection on emerging cryptocurrency blockchains due to the vast number of addresses and diverse anomalous behaviors. Recently, advanced Graph Anomaly Detection (GAD) approaches applied to blockchains have faced two critical challenges: \textit{adversarial pattern evolution by malicious actors} and \textit{the out-of-distribution (OOD) problem caused by varied transaction semantics on blockchains}. To address these challenges, we propose a novel framework termed \textbf{TE}mporal \textbf{M}otif-aware \textbf{G}raph \textbf{T}est-\textbf{T}ime \textbf{A}daptation (\textbf{TEMG-TTA}). First, we comprehensively capture the 3-node temporal motif distribution of each active address using an efficient computational mechanism, enabling downstream temporal motif-aware graph learning. Second, we design a simple yet effective test-time adaptation strategy to facilitate the sharing of common patterns between training and testing graphs. Extensive experiments on 5 real-world datasets demonstrate that our proposed \textbf{TEMG-TTA} outperforms \textit{state-of-the-art} GAD approaches by an average of 54.88\%. A further case study on interpretable motif patterns reveals that \textbf{TEMG-TTA} explicitly characterizes the complex transaction patterns of anomalous addresses, thereby verifying the effectiveness of our technical designs. Our code will be made publicly available https://github.com/LuoXishuang0712/TEMG-TTA/.
GraphScout: Empowering Large Language Models with Intrinsic Exploration Ability for Agentic Graph Reasoning
Mar 02, 2026Knowledge graphs provide structured and reliable information for many real-world applications, motivating increasing interest in combining large language models (LLMs) with graph-based retrieval to improve factual grounding. Recent Graph-based Retrieval-Augmented Generation (GraphRAG) methods therefore introduce iterative interaction between LLMs and knowledge graphs to enhance reasoning capability. However, existing approaches typically depend on manually designed guidance and interact with knowledge graphs through a limited set of predefined tools, which substantially constrains graph exploration. To address these limitations, we propose GraphScout, a training-centric agentic graph reasoning framework equipped with more flexible graph exploration tools. GraphScout enables models to autonomously interact with knowledge graphs to synthesize structured training data which are then used to post-train LLMs, thereby internalizing agentic graph reasoning ability without laborious manual annotation or task curation. Extensive experiments across five knowledge-graph domains show that a small model (e.g., Qwen3-4B) augmented with GraphScout outperforms baseline methods built on leading LLMs (e.g., Qwen-Max) by an average of 16.7\% while requiring significantly fewer inference tokens. Moreover, GraphScout exhibits robust cross-domain transfer performance. Our code will be made publicly available~\footnote{https://github.com/Ying-Yuchen/_GraphScout_}.
Physics-informed Diffusion Generation for Geomagnetic Map Interpolation
Jan 31, 2026Geomagnetic map interpolation aims to infer unobserved geomagnetic data at spatial points, yielding critical applications in navigation and resource exploration. However, existing methods for scattered data interpolation are not specifically designed for geomagnetic maps, which inevitably leads to suboptimal performance due to detection noise and the laws of physics. Therefore, we propose a Physics-informed Diffusion Generation framework~(PDG) to interpolate incomplete geomagnetic maps. First, we design a physics-informed mask strategy to guide the diffusion generation process based on a local receptive field, effectively eliminating noise interference. Second, we impose a physics-informed constraint on the diffusion generation results following the kriging principle of geomagnetic maps, ensuring strict adherence to the laws of physics. Extensive experiments and in-depth analyses on four real-world datasets demonstrate the superiority and effectiveness of each component of PDG.
Learning Multi-Modal Mobility Dynamics for Generalized Next Location Recommendation
Dec 27, 2025The precise prediction of human mobility has produced significant socioeconomic impacts, such as location recommendations and evacuation suggestions. However, existing methods suffer from limited generalization capability: unimodal approaches are constrained by data sparsity and inherent biases, while multi-modal methods struggle to effectively capture mobility dynamics caused by the semantic gap between static multi-modal representation and spatial-temporal dynamics. Therefore, we leverage multi-modal spatial-temporal knowledge to characterize mobility dynamics for the location recommendation task, dubbed as \textbf{M}ulti-\textbf{M}odal \textbf{Mob}ility (\textbf{M}$^3$\textbf{ob}). First, we construct a unified spatial-temporal relational graph (STRG) for multi-modal representation, by leveraging the functional semantics and spatial-temporal knowledge captured by the large language models (LLMs)-enhanced spatial-temporal knowledge graph (STKG). Second, we design a gating mechanism to fuse spatial-temporal graph representations of different modalities, and propose an STKG-guided cross-modal alignment to inject spatial-temporal dynamic knowledge into the static image modality. Extensive experiments on six public datasets show that our proposed method not only achieves consistent improvements in normal scenarios but also exhibits significant generalization ability in abnormal scenarios.
Tree of Preferences for Diversified Recommendation
Dec 24, 2025Diversified recommendation has attracted increasing attention from both researchers and practitioners, which can effectively address the homogeneity of recommended items. Existing approaches predominantly aim to infer the diversity of user preferences from observed user feedback. Nonetheless, due to inherent data biases, the observed data may not fully reflect user interests, where underexplored preferences can be overwhelmed or remain unmanifested. Failing to capture these preferences can lead to suboptimal diversity in recommendations. To fill this gap, this work aims to study diversified recommendation from a data-bias perspective. Inspired by the outstanding performance of large language models (LLMs) in zero-shot inference leveraging world knowledge, we propose a novel approach that utilizes LLMs' expertise to uncover underexplored user preferences from observed behavior, ultimately providing diverse and relevant recommendations. To achieve this, we first introduce Tree of Preferences (ToP), an innovative structure constructed to model user preferences from coarse to fine. ToP enables LLMs to systematically reason over the user's rationale behind their behavior, thereby uncovering their underexplored preferences. To guide diversified recommendations using uncovered preferences, we adopt a data-centric approach, identifying candidate items that match user preferences and generating synthetic interactions that reflect underexplored preferences. These interactions are integrated to train a general recommender for diversification. Moreover, we scale up overall efficiency by dynamically selecting influential users during optimization. Extensive evaluations of both diversity and relevance show that our approach outperforms existing methods in most cases and achieves near-optimal performance in others, with reasonable inference latency.
Dual-branch Spatial-Temporal Self-supervised Representation for Enhanced Road Network Learning
Nov 10, 2025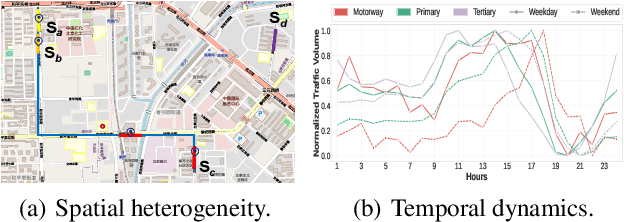



Road network representation learning (RNRL) has attracted increasing attention from both researchers and practitioners as various spatiotemporal tasks are emerging. Recent advanced methods leverage Graph Neural Networks (GNNs) and contrastive learning to characterize the spatial structure of road segments in a self-supervised paradigm. However, spatial heterogeneity and temporal dynamics of road networks raise severe challenges to the neighborhood smoothing mechanism of self-supervised GNNs. To address these issues, we propose a $\textbf{D}$ual-branch $\textbf{S}$patial-$\textbf{T}$emporal self-supervised representation framework for enhanced road representations, termed as DST. On one hand, DST designs a mix-hop transition matrix for graph convolution to incorporate dynamic relations of roads from trajectories. Besides, DST contrasts road representations of the vanilla road network against that of the hypergraph in a spatial self-supervised way. The hypergraph is newly built based on three types of hyperedges to capture long-range relations. On the other hand, DST performs next token prediction as the temporal self-supervised task on the sequences of traffic dynamics based on a causal Transformer, which is further regularized by differentiating traffic modes of weekdays from those of weekends. Extensive experiments against state-of-the-art methods verify the superiority of our proposed framework. Moreover, the comprehensive spatiotemporal modeling facilitates DST to excel in zero-shot learning scenarios.
Adaptive Location Hierarchy Learning for Long-Tailed Mobility Prediction
May 26, 2025Human mobility prediction is crucial for applications ranging from location-based recommendations to urban planning, which aims to forecast users' next location visits based on historical trajectories. Despite the severe long-tailed distribution of locations, the problem of long-tailed mobility prediction remains largely underexplored. Existing long-tailed learning methods primarily focus on rebalancing the skewed distribution at the data, model, or class level, neglecting to exploit the spatiotemporal semantics of locations. To address this gap, we propose the first plug-and-play framework for long-tailed mobility prediction in an exploitation and exploration manner, named \textbf{A}daptive \textbf{LO}cation \textbf{H}ier\textbf{A}rchy learning (ALOHA). First, we construct city-tailored location hierarchy based on Large Language Models (LLMs) by exploiting Maslow's theory of human motivation to design Chain-of-Thought (CoT) prompts that captures spatiotemporal semantics. Second, we optimize the location hierarchy predictions by Gumbel disturbance and node-wise adaptive weights within the hierarchical tree structure. Experiments on state-of-the-art models across six datasets demonstrate the framework's consistent effectiveness and generalizability, which strikes a well balance between head and tail locations. Weight analysis and ablation studies reveal the optimization differences of each component for head and tail locations. Furthermore, in-depth analyses of hierarchical distance and case study demonstrate the effective semantic guidance from the location hierarchy. Our code will be made publicly available.
SeRL: Self-Play Reinforcement Learning for Large Language Models with Limited Data
May 25, 2025



Recent advances have demonstrated the effectiveness of Reinforcement Learning (RL) in improving the reasoning capabilities of Large Language Models (LLMs). However, existing works inevitably rely on high-quality instructions and verifiable rewards for effective training, both of which are often difficult to obtain in specialized domains. In this paper, we propose Self-play Reinforcement Learning(SeRL) to bootstrap LLM training with limited initial data. Specifically, SeRL comprises two complementary modules: self-instruction and self-rewarding. The former module generates additional instructions based on the available data at each training step, employing robust online filtering strategies to ensure instruction quality, diversity, and difficulty. The latter module introduces a simple yet effective majority-voting mechanism to estimate response rewards for additional instructions, eliminating the need for external annotations. Finally, SeRL performs conventional RL based on the generated data, facilitating iterative self-play learning. Extensive experiments on various reasoning benchmarks and across different LLM backbones demonstrate that the proposed SeRL yields results superior to its counterparts and achieves performance on par with those obtained by high-quality data with verifiable rewards. Our code is available at https://github.com/wantbook-book/SeRL.
From GNNs to Trees: Multi-Granular Interpretability for Graph Neural Networks
May 01, 2025



Interpretable Graph Neural Networks (GNNs) aim to reveal the underlying reasoning behind model predictions, attributing their decisions to specific subgraphs that are informative. However, existing subgraph-based interpretable methods suffer from an overemphasis on local structure, potentially overlooking long-range dependencies within the entire graphs. Although recent efforts that rely on graph coarsening have proven beneficial for global interpretability, they inevitably reduce the graphs to a fixed granularity. Such an inflexible way can only capture graph connectivity at a specific level, whereas real-world graph tasks often exhibit relationships at varying granularities (e.g., relevant interactions in proteins span from functional groups, to amino acids, and up to protein domains). In this paper, we introduce a novel Tree-like Interpretable Framework (TIF) for graph classification, where plain GNNs are transformed into hierarchical trees, with each level featuring coarsened graphs of different granularity as tree nodes. Specifically, TIF iteratively adopts a graph coarsening module to compress original graphs (i.e., root nodes of trees) into increasingly coarser ones (i.e., child nodes of trees), while preserving diversity among tree nodes within different branches through a dedicated graph perturbation module. Finally, we propose an adaptive routing module to identify the most informative root-to-leaf paths, providing not only the final prediction but also the multi-granular interpretability for the decision-making process. Extensive experiments on the graph classification benchmarks with both synthetic and real-world datasets demonstrate the superiority of TIF in interpretability, while also delivering a competitive prediction performance akin to the state-of-the-art counterparts.
Parallelized Planning-Acting for Efficient LLM-based Multi-Agent Systems
Mar 05, 2025Recent advancements in Large Language Model(LLM)-based Multi-Agent Systems(MAS) have demonstrated remarkable potential for tackling complex decision-making tasks. However, existing frameworks inevitably rely on serialized execution paradigms, where agents must complete sequential LLM planning before taking action. This fundamental constraint severely limits real-time responsiveness and adaptation, which is crucial in dynamic environments with ever-changing scenarios. In this paper, we propose a novel parallelized planning-acting framework for LLM-based MAS, featuring a dual-thread architecture with interruptible execution to enable concurrent planning and acting. Specifically, our framework comprises two core threads:(1) a planning thread driven by a centralized memory system, maintaining synchronization of environmental states and agent communication to support dynamic decision-making; and (2) an acting thread equipped with a comprehensive skill library, enabling automated task execution through recursive decomposition. Extensive experiments on challenging Minecraft demonstrate the effectiveness of the proposed framework.