 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphScout: Empowering Large Language Models with Intrinsic Exploration Ability for Agentic Graph Reasoning
Mar 02, 2026Knowledge graphs provide structured and reliable information for many real-world applications, motivating increasing interest in combining large language models (LLMs) with graph-based retrieval to improve factual grounding. Recent Graph-based Retrieval-Augmented Generation (GraphRAG) methods therefore introduce iterative interaction between LLMs and knowledge graphs to enhance reasoning capability. However, existing approaches typically depend on manually designed guidance and interact with knowledge graphs through a limited set of predefined tools, which substantially constrains graph exploration. To address these limitations, we propose GraphScout, a training-centric agentic graph reasoning framework equipped with more flexible graph exploration tools. GraphScout enables models to autonomously interact with knowledge graphs to synthesize structured training data which are then used to post-train LLMs, thereby internalizing agentic graph reasoning ability without laborious manual annotation or task curation. Extensive experiments across five knowledge-graph domains show that a small model (e.g., Qwen3-4B) augmented with GraphScout outperforms baseline methods built on leading LLMs (e.g., Qwen-Max) by an average of 16.7\% while requiring significantly fewer inference tokens. Moreover, GraphScout exhibits robust cross-domain transfer performance. Our code will be made publicly available~\footnote{https://github.com/Ying-Yuchen/_GraphScout_}.
Physics-informed Diffusion Generation for Geomagnetic Map Interpolation
Jan 31, 2026Geomagnetic map interpolation aims to infer unobserved geomagnetic data at spatial points, yielding critical applications in navigation and resource exploration. However, existing methods for scattered data interpolation are not specifically designed for geomagnetic maps, which inevitably leads to suboptimal performance due to detection noise and the laws of physics. Therefore, we propose a Physics-informed Diffusion Generation framework~(PDG) to interpolate incomplete geomagnetic maps. First, we design a physics-informed mask strategy to guide the diffusion generation process based on a local receptive field, effectively eliminating noise interference. Second, we impose a physics-informed constraint on the diffusion generation results following the kriging principle of geomagnetic maps, ensuring strict adherence to the laws of physics. Extensive experiments and in-depth analyses on four real-world datasets demonstrate the superiority and effectiveness of each component of PDG.
SeRL: Self-Play Reinforcement Learning for Large Language Models with Limited Data
May 25, 2025



Recent advances have demonstrated the effectiveness of Reinforcement Learning (RL) in improving the reasoning capabilities of Large Language Models (LLMs). However, existing works inevitably rely on high-quality instructions and verifiable rewards for effective training, both of which are often difficult to obtain in specialized domains. In this paper, we propose Self-play Reinforcement Learning(SeRL) to bootstrap LLM training with limited initial data. Specifically, SeRL comprises two complementary modules: self-instruction and self-rewarding. The former module generates additional instructions based on the available data at each training step, employing robust online filtering strategies to ensure instruction quality, diversity, and difficulty. The latter module introduces a simple yet effective majority-voting mechanism to estimate response rewards for additional instructions, eliminating the need for external annotations. Finally, SeRL performs conventional RL based on the generated data, facilitating iterative self-play learning. Extensive experiments on various reasoning benchmarks and across different LLM backbones demonstrate that the proposed SeRL yields results superior to its counterparts and achieves performance on par with those obtained by high-quality data with verifiable rewards. Our code is available at https://github.com/wantbook-book/SeRL.
From GNNs to Trees: Multi-Granular Interpretability for Graph Neural Networks
May 01, 2025



Interpretable Graph Neural Networks (GNNs) aim to reveal the underlying reasoning behind model predictions, attributing their decisions to specific subgraphs that are informative. However, existing subgraph-based interpretable methods suffer from an overemphasis on local structure, potentially overlooking long-range dependencies within the entire graphs. Although recent efforts that rely on graph coarsening have proven beneficial for global interpretability, they inevitably reduce the graphs to a fixed granularity. Such an inflexible way can only capture graph connectivity at a specific level, whereas real-world graph tasks often exhibit relationships at varying granularities (e.g., relevant interactions in proteins span from functional groups, to amino acids, and up to protein domains). In this paper, we introduce a novel Tree-like Interpretable Framework (TIF) for graph classification, where plain GNNs are transformed into hierarchical trees, with each level featuring coarsened graphs of different granularity as tree nodes. Specifically, TIF iteratively adopts a graph coarsening module to compress original graphs (i.e., root nodes of trees) into increasingly coarser ones (i.e., child nodes of trees), while preserving diversity among tree nodes within different branches through a dedicated graph perturbation module. Finally, we propose an adaptive routing module to identify the most informative root-to-leaf paths, providing not only the final prediction but also the multi-granular interpretability for the decision-making process. Extensive experiments on the graph classification benchmarks with both synthetic and real-world datasets demonstrate the superiority of TIF in interpretability, while also delivering a competitive prediction performance akin to the state-of-the-art counterparts.
Learning a Mini-batch Graph Transformer via Two-stage Interaction Augmentation
Jul 13, 2024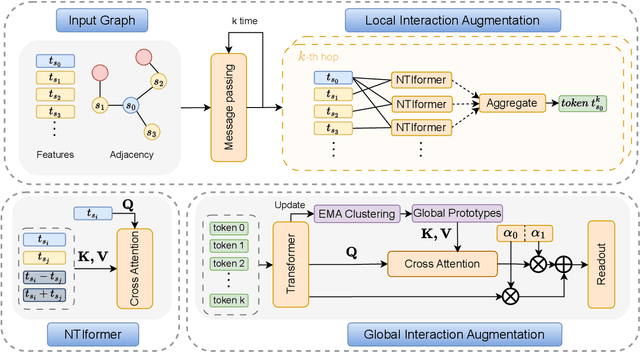
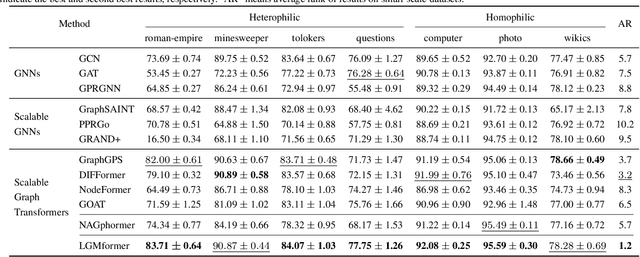
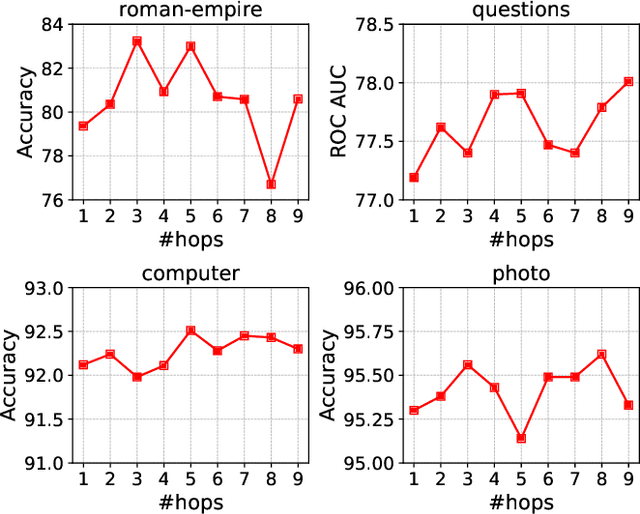
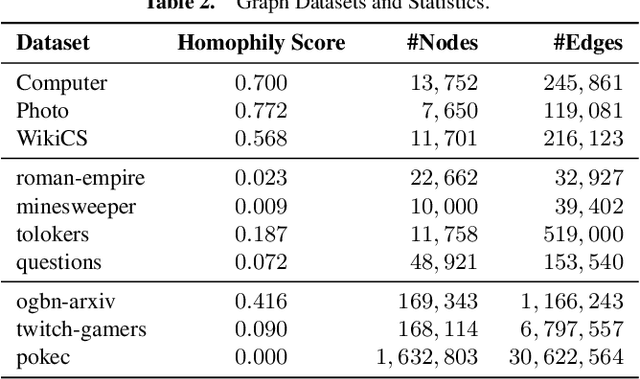
Mini-batch Graph Transformer (MGT), as an emerging graph learning model, has demonstrated significant advantages in semi-supervised node prediction tasks with improved computational efficiency and enhanced model robustness. However, existing methods for processing local information either rely on sampling or simple aggregation, which respectively result in the loss and squashing of critical neighbor information.Moreover, the limited number of nodes in each mini-batch restricts the model's capacity to capture the global characteristic of the graph. In this paper, we propose LGMformer, a novel MGT model that employs a two-stage augmented interaction strategy, transitioning from local to global perspectives, to address the aforementioned bottlenecks.The local interaction augmentation (LIA) presents a neighbor-target interaction Transformer (NTIformer) to acquire an insightful understanding of the co-interaction patterns between neighbors and the target node, resulting in a locally effective token list that serves as input for the MGT. In contrast, global interaction augmentation (GIA) adopts a cross-attention mechanism to incorporate entire graph prototypes into the target node epresentation, thereby compensating for the global graph information to ensure a more comprehensive perception. To this end, LGMformer achieves the enhancement of node representations under the MGT paradigm.Experimental results related to node classification on the ten benchmark datasets demonstrate the effectiveness of the proposed method. Our code is available at https://github.com/l-wd/LGMformer.
Unveiling Global Interactive Patterns across Graphs: Towards Interpretable Graph Neural Networks
Jul 02, 2024



Graph Neural Networks (GNNs) have emerged as a prominent framework for graph mining, leading to significant advances across various domains. Stemmed from the node-wise representations of GNNs, existing explanation studies have embraced the subgraph-specific viewpoint that attributes the decision results to the salient features and local structures of nodes. However, graph-level tasks necessitate long-range dependencies and global interactions for advanced GNNs, deviating significantly from subgraph-specific explanations. To bridge this gap, this paper proposes a novel intrinsically interpretable scheme for graph classification, termed as Global Interactive Pattern (GIP) learning, which introduces learnable global interactive patterns to explicitly interpret decisions. GIP first tackles the complexity of interpretation by clustering numerous nodes using a constrained graph clustering module. Then, it matches the coarsened global interactive instance with a batch of self-interpretable graph prototypes, thereby facilitating a transparent graph-level reasoning process. Extensive experiments conducted on both synthetic and real-world benchmarks demonstrate that the proposed GIP yields significantly superior interpretability and competitive performance to~the state-of-the-art counterparts. Our code will be made publicly available.
Transmission Interface Power Flow Adjustment: A Deep Reinforcement Learning Approach based on Multi-task Attribution Map
May 24, 2024



Transmission interface power flow adjustment is a critical measure to ensure the security and economy operation of power systems. However, conventional model-based adjustment schemes are limited by the increasing variations and uncertainties occur in power systems, where the adjustment problems of different transmission interfaces are often treated as several independent tasks, ignoring their coupling relationship and even leading to conflict decisions. In this paper, we introduce a novel data-driven deep reinforcement learning (DRL) approach, to handle multiple power flow adjustment tasks jointly instead of learning each task from scratch. At the heart of the proposed method is a multi-task attribution map (MAM), which enables the DRL agent to explicitly attribute each transmission interface task to different power system nodes with task-adaptive attention weights. Based on this MAM, the agent can further provide effective strategies to solve the multi-task adjustment problem with a near-optimal operation cost. Simulation results on the IEEE 118-bus system, a realistic 300-bus system in China, and a very large European system with 9241 buses demonstrate that the proposed method significantly improves the performance compared with several baseline methods, and exhibits high interpretability with the learnable MAM.
Advantage-Aware Policy Optimization for Offline Reinforcement Learning
Mar 12, 2024Offline Reinforcement Learning (RL) endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the Out-Of-Distribution (OOD) problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent Advantage-Weighted (AW) methods prioritize samples with high advantage values for agent training while inevitably leading to overfitting on these samples. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a Conditional Variational Auto-Encoder (CVAE) to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to state-of-the-art counterparts. Our code will be made publicly available.
Powerformer: A Section-adaptive Transformer for Power Flow Adjustment
Jan 10, 2024



In this paper, we present a novel transformer architecture tailored for learning robust power system state representations, which strives to optimize power dispatch for the power flow adjustment across different transmission sections. Specifically, our proposed approach, named Powerformer, develops a dedicated section-adaptive attention mechanism, separating itself from the self-attention used in conventional transformers. This mechanism effectively integrates power system states with transmission section information, which facilitates the development of robust state representations. Furthermore, by considering the graph topology of power system and the electrical attributes of bus nodes, we introduce two customized strategies to further enhance the expressiveness: graph neural network propagation and multi-factor attention mechanism. Extensive evaluations are conducted on three power system scenarios, including the IEEE 118-bus system, a realistic 300-bus system in China, and a large-scale European system with 9241 buses, where Powerformer demonstrates its superior performance over several baseline methods.
Agent-Aware Training for Agent-Agnostic Action Advising in Deep Reinforcement Learning
Nov 28, 2023



Action advising endeavors to leverage supplementary guidance from expert teachers to alleviate the issue of sampling inefficiency in Deep Reinforcement Learning (DRL). Previous agent-specific action advising methods are hindered by imperfections in the agent itself, while agent-agnostic approaches exhibit limited adaptability to the learning agent. In this study, we propose a novel framework called Agent-Aware trAining yet Agent-Agnostic Action Advising (A7) to strike a balance between the two. The underlying concept of A7 revolves around utilizing the similarity of state features as an indicator for soliciting advice. However, unlike prior methodologies, the measurement of state feature similarity is performed by neither the error-prone learning agent nor the agent-agnostic advisor. Instead, we employ a proxy model to extract state features that are both discriminative (adaptive to the agent) and generally applicable (robust to agent noise). Furthermore, we utilize behavior cloning to train a model for reusing advice and introduce an intrinsic reward for the advised samples to incentivize the utilization of expert guidance. Experiments are conducted on the GridWorld, LunarLander, and six prominent scenarios from Atari games. The results demonstrate that A7 significantly accelerates the learning process and surpasses existing methods (both agent-specific and agent-agnostic) by a substantial margin. Our code will be made publicly available.