 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPLOTS: A Unified Pretrained Language Model for Constrained Time-series Generation
Jun 09, 2026In time-series generation, existing approaches typically handcraft ortrain a separate model for each dataset, which hinders their scalability and fails to leverage shared temporal structures across domains. To address this fragmentation, we propose UPLOTS, a Unified, Prompt-guided Language model framework fOr constrained Time-Series Generation across diverse domains. Instead of building task-specific models, UPLOTS leverages a single pre-trained transformer backbone guided by learned constraint prompts, enabling on-demand generation with precise pattern control. One key innovation is our dynamic multi-dataset loss re-weighting and prompt-to-pattern mapping, which allows UPLOTS to internalize diverse temporal structures during training and conditionally generate them at inference. We evaluate UPLOTS on four real-world benchmarks and multiple constraint settings, including peak-period, calendar, load-level, and volatility patterns. Additional held-out constraint-combination and downstream forecasting experiments further demonstrate that UPLOTS generalizes beyond the original peak-pattern setting and improves data augmentation under scarce real-data regimes. Our code and baselines are available at anonymous github repo: https://anonymous.4open.science/r/UPLOTS-6C36.
From XXLTraffic to EvoXXLTraffic: Scaling Traffic Forecasting to Sensor-Evolving Networks
May 28, 2026Existing traffic forecasting benchmarks assume a fixed sensor set, but real road-sensor networks grow continuously as the road network changes year by year. We introduce the XXLTraffic dataset family, which spans up to 27 years of California PeMS and Transport for NSW data. The fixed-sensor subsets of XXLTraffic support extremely long forecasting with multi-year gaps and standard hourly / daily long-horizon forecasting. We extend it to EvoXXLTraffic, a sensor-evolving reorganization that exposes per-year active sensors, yearly traffic-flow matrices, and yearly graph snapshots across nine PeMS districts, with growth ratios ranging from +305% to over +10,000%. We define a yearly streaming forecasting protocol on EvoXXLTraffic in which each calendar year is a continual task, and benchmark a wide range of representative baselines drawn from static spatio-temporal GNNs, naïve online schemes, evolving-graph continual methods, and retrieval / test-time methods. We find that our ultra-large evolutionary dataset better reflects the real world, and many state-of-the-art (SOTA) results no longer work. Our dataset complements existing benchmarks by enabling more realistic forecasting under ultra-long evolutionary road networks.
TrajDLM: Topology-Aware Block Diffusion Language Model for Trajectory Generation
May 11, 2026Generating high-fidelity synthetic GPS trajectories is increasingly important for applications in transportation, urban planning, and what-if scenario simulation, especially as privacy concerns limit access to real-world mobility data. Existing trajectory generation models face a trade-off between efficiency and faithfulness to road network topology: continuous-space methods enable fast generation but ignore the road network, while topology-aware approaches rely on search-based autoregressive decoding that limits generation speed. We propose TrajDLM, a topology-aware trajectory generation framework based on block diffusion language models that bridges this gap. TrajDLM models trajectories as sequences of discrete road segments, combining a block diffusion backbone for efficient denoising, topology-aware embeddings from a road network encoder, and topology-constrained sampling to ensure coherent and realistic trajectories. Across three city-scale datasets, TrajDLM achieves strong performance on fine-grained local similarity metrics while being up to $2.8\times$ faster than prior work, and demonstrates strong zero-shot transfer across domains, including unseen transportation modes. These results highlight the effectiveness of block-wise discrete diffusion as a scalable approach to accurate and efficient trajectory generation. Our code is available at https://github.com/cruiseresearchgroup/TrajDLM/
Embedding spatial context in urban traffic forecasting with contrastive pre-training
Mar 19, 2025



Urban traffic forecasting is a commonly encountered problem, with wide-ranging applications in fields such as urban planning, civil engineering and transport. In this paper, we study the enhancement of traffic forecasting with pre-training, focusing on spatio-temporal graph methods. While various machine learning methods to solve traffic forecasting problems have been explored and extensively studied, there is a gap of a more contextual approach: studying how relevant non-traffic data can improve prediction performance on traffic forecasting problems. We call this data spatial context. We introduce a novel method of combining road and traffic information through the notion of a traffic quotient graph, a quotient graph formed from road geometry and traffic sensors. We also define a way to encode this relationship in the form of a geometric encoder, pre-trained using contrastive learning methods and enhanced with OpenStreetMap data. We introduce and discuss ways to integrate this geometric encoder with existing graph neural network (GNN)-based traffic forecasting models, using a contrastive pre-training paradigm. We demonstrate the potential for this hybrid model to improve generalisation and performance with zero additional traffic data. Code for this paper is available at https://github.com/mattchrlw/forecasting-on-new-roads.
XXLTraffic: Expanding and Extremely Long Traffic Dataset for Ultra-Dynamic Forecasting Challenges
Jun 18, 2024Traffic forecasting is crucial for smart cities and intelligent transportation initiatives, where deep learning has made significant progress in modeling complex spatio-temporal patterns in recent years. However, current public datasets have limitations in reflecting the ultra-dynamic nature of real-world scenarios, characterized by continuously evolving infrastructures, varying temporal distributions, and temporal gaps due to sensor downtimes or changes in traffic patterns. These limitations inevitably restrict the practical applicability of existing traffic forecasting datasets. To bridge this gap, we present XXLTraffic, the largest available public traffic dataset with the longest timespan and increasing number of sensor nodes over the multiple years observed in the data, curated to support research in ultra-dynamic forecasting. Our benchmark includes both typical time-series forecasting settings with hourly and daily aggregated data and novel configurations that introduce gaps and down-sample the training size to better simulate practical constraints. We anticipate the new XXLTraffic will provide a fresh perspective for the time-series and traffic forecasting communities. It would also offer a robust platform for developing and evaluating models designed to tackle ultra-dynamic and extremely long forecasting problems. Our dataset supplements existing spatio-temporal data resources and leads to new research directions in this domain.
BTS: Building Timeseries Dataset: Empowering Large-Scale Building Analytics
Jun 18, 2024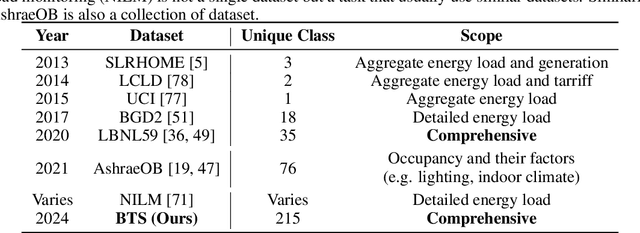
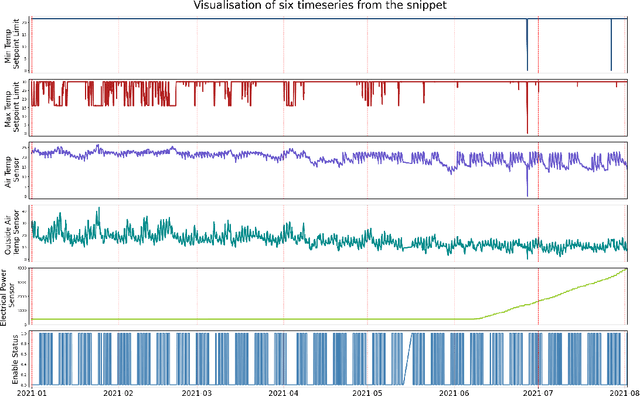
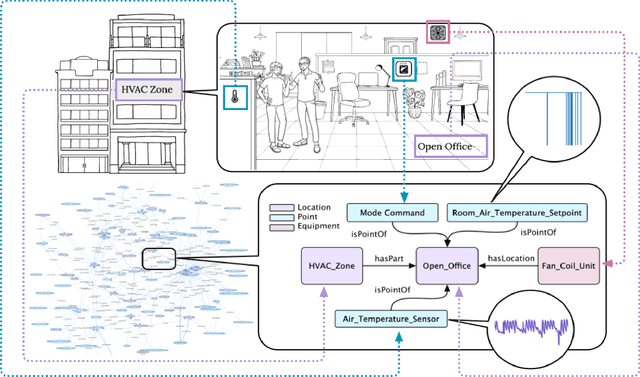
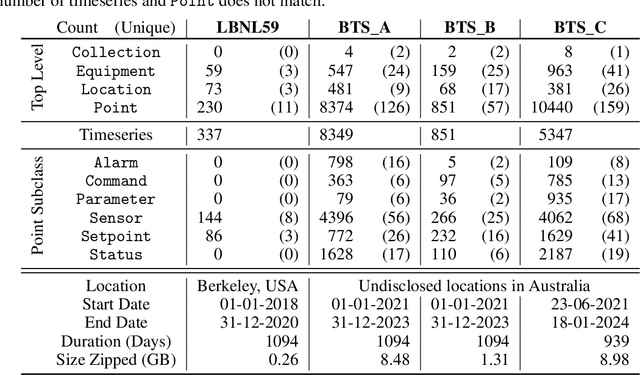
Buildings play a crucial role in human well-being, influencing occupant comfort, health, and safety. Additionally, they contribute significantly to global energy consumption, accounting for one-third of total energy usage, and carbon emissions. Optimizing building performance presents a vital opportunity to combat climate change and promote human flourishing. However, research in building analytics has been hampered by the lack of accessible, available, and comprehensive real-world datasets on multiple building operations. In this paper, we introduce the Building TimeSeries (BTS) dataset. Our dataset covers three buildings over a three-year period, comprising more than ten thousand timeseries data points with hundreds of unique ontologies. Moreover, the metadata is standardized using the Brick schema. To demonstrate the utility of this dataset, we performed benchmarks on two tasks: timeseries ontology classification and zero-shot forecasting. These tasks represent an essential initial step in addressing challenges related to interoperability in building analytics. Access to the dataset and the code used for benchmarking are available here: https://github.com/cruiseresearchgroup/DIEF_BTS .
Enhancing Spatio-temporal Quantile Forecasting with Curriculum Learning: Lessons Learned
Jun 18, 2024



Training models on spatio-temporal (ST) data poses an open problem due to the complicated and diverse nature of the data itself, and it is challenging to ensure the model's performance directly trained on the original ST data. While limiting the variety of training data can make training easier, it can also lead to a lack of knowledge and information for the model, resulting in a decrease in performance. To address this challenge, we presented an innovative paradigm that incorporates three separate forms of curriculum learning specifically targeting from spatial, temporal, and quantile perspectives. Furthermore, our framework incorporates a stacking fusion module to combine diverse information from three types of curriculum learning, resulting in a strong and thorough learning process. We demonstrated the effectiveness of this framework with extensive empirical evaluations, highlighting its better performance in addressing complex ST challenges. We provided thorough ablation studies to investigate the effectiveness of our curriculum and to explain how it contributes to the improvement of learning efficiency on ST data.
A Gap in Time: The Challenge of Processing Heterogeneous IoT Point Data in Buildings
May 23, 2024The growing need for sustainable energy solutions has driven the integration of digitalized buildings into the power grid, utilizing Internet-of-Things technology to optimize building performance and energy efficiency. However, incorporating IoT point data within deep-learning frameworks for energy management presents a complex challenge, predominantly due to the inherent data heterogeneity. This paper comprehensively analyzes the multifaceted heterogeneity present in real-world building IoT data streams. We meticulously dissect the heterogeneity across multiple dimensions, encompassing ontology, etiology, temporal irregularity, spatial diversity, and their combined effects on the IoT point data distribution. In addition, experiments using state-of-the-art forecasting models are conducted to evaluate their impacts on the performance of deep-learning models for forecasting tasks. By charting the diversity along these dimensions, we illustrate the challenges and delineate pathways for future research to leverage this heterogeneity as a resource rather than a roadblock. This exploration sets the stage for advancing the predictive abilities of deep-learning algorithms and catalyzing the evolution of intelligent energy-efficient buildings.
Navigating Out-of-Distribution Electricity Load Forecasting during COVID-19: A Continual Learning Approach Leveraging Human Mobility
Sep 12, 2023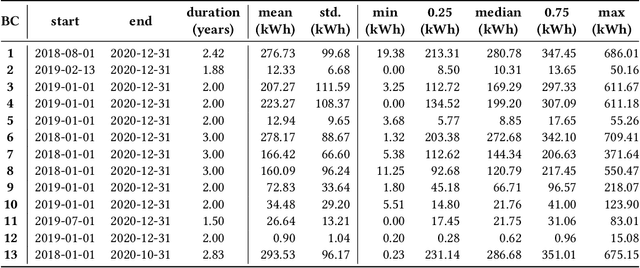
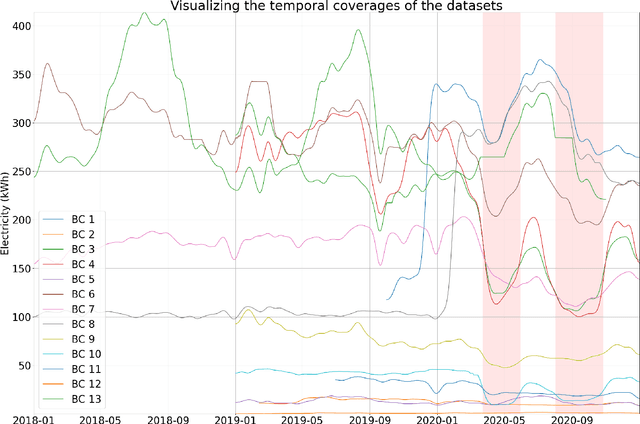
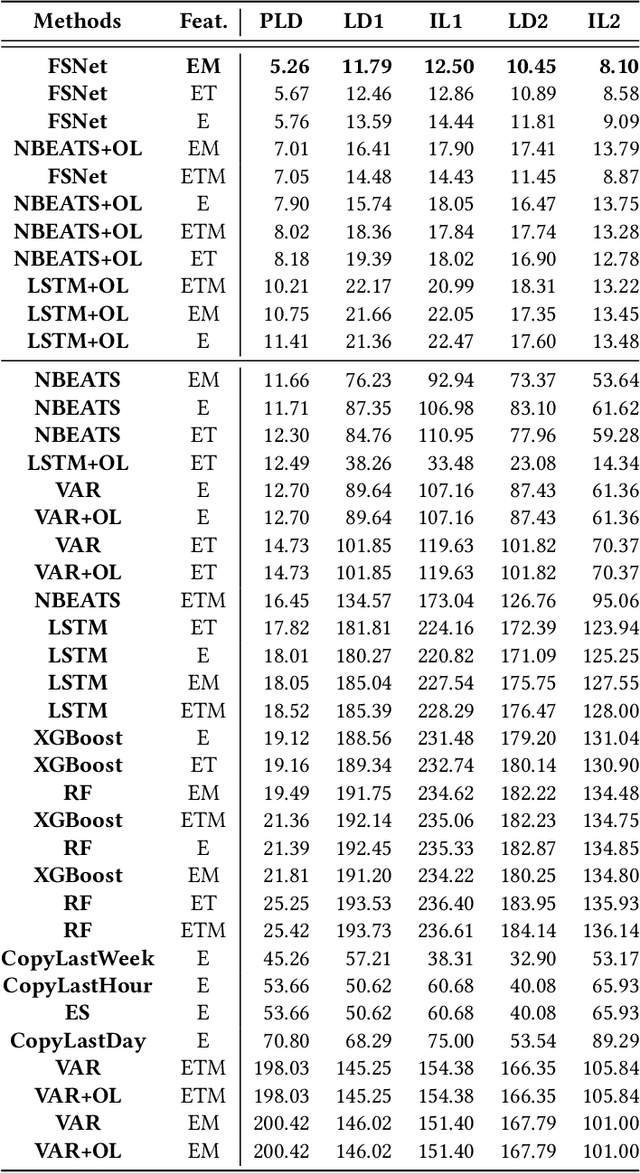
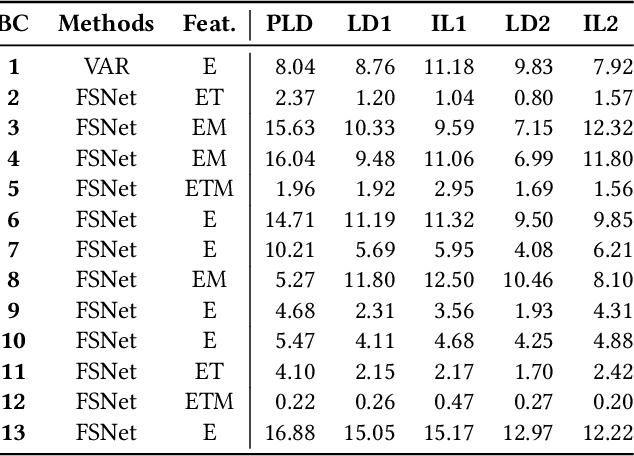
In traditional deep learning algorithms, one of the key assumptions is that the data distribution remains constant during both training and deployment. However, this assumption becomes problematic when faced with Out-of-Distribution periods, such as the COVID-19 lockdowns, where the data distribution significantly deviates from what the model has seen during training. This paper employs a two-fold strategy: utilizing continual learning techniques to update models with new data and harnessing human mobility data collected from privacy-preserving pedestrian counters located outside buildings. In contrast to online learning, which suffers from 'catastrophic forgetting' as newly acquired knowledge often erases prior information, continual learning offers a holistic approach by preserving past insights while integrating new data. This research applies FSNet, a powerful continual learning algorithm, to real-world data from 13 building complexes in Melbourne, Australia, a city which had the second longest total lockdown duration globally during the pandemic. Results underscore the crucial role of continual learning in accurate energy forecasting, particularly during Out-of-Distribution periods. Secondary data such as mobility and temperature provided ancillary support to the primary forecasting model. More importantly, while traditional methods struggled to adapt during lockdowns, models featuring at least online learning demonstrated resilience, with lockdown periods posing fewer challenges once armed with adaptive learning techniques. This study contributes valuable methodologies and insights to the ongoing effort to improve energy load forecasting during future Out-of-Distribution periods.
Continually learning out-of-distribution spatiotemporal data for robust energy forecasting
Jun 10, 2023Forecasting building energy usage is essential for promoting sustainability and reducing waste, as it enables building managers to optimize energy consumption and reduce costs. This importance is magnified during anomalous periods, such as the COVID-19 pandemic, which have disrupted occupancy patterns and made accurate forecasting more challenging. Forecasting energy usage during anomalous periods is difficult due to changes in occupancy patterns and energy usage behavior. One of the primary reasons for this is the shift in distribution of occupancy patterns, with many people working or learning from home. This has created a need for new forecasting methods that can adapt to changing occupancy patterns. Online learning has emerged as a promising solution to this challenge, as it enables building managers to adapt to changes in occupancy patterns and adjust energy usage accordingly. With online learning, models can be updated incrementally with each new data point, allowing them to learn and adapt in real-time. Another solution is to use human mobility data as a proxy for occupancy, leveraging the prevalence of mobile devices to track movement patterns and infer occupancy levels. Human mobility data can be useful in this context as it provides a way to monitor occupancy patterns without relying on traditional sensors or manual data collection methods. We have conducted extensive experiments using data from six buildings to test the efficacy of these approaches. However, deploying these methods in the real world presents several challenges.