 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient and Evidence-grounded Mobility Prediction with LLM-Driven Agent
Jun 03, 2026Individual-level mobility prediction is central to urban simulation, transportation planning, and policy analysis. Supervised sequence models achieve strong accuracy but require task-specific training and offer limited decision-level transparency. Recent LLM-based methods improve interpretability, yet mostly rely on static prompts and single-pass inference, limiting their ability to seek additional evidence when mobility signals are weak or conflicting. We propose \method{}, a training-free LLM-driven agent framework that formulates next-location prediction as adaptive evidence-controlled decision making. \method{} resolves routine cases through a fast path based on historical regularity, while ambiguous cases trigger iterative tool use over recent trajectories, historical behavior, stay-move likelihood, and geographical evidence. Across three mobility datasets, AgentMob achieves the strongest overall performance among training-free LLM-based methods, with GPT-5.4 reaching 71.42\% Acc@1 on BW, 33.14\% on YJMob100K, and 33.50\% on Shanghai ISP. On BW non-fast-path cases, the LLM controller improves Acc@1 from 30.65\% to 48.62\% over a same-tool statistical baseline, showing that its main benefit lies in resolving ambiguous predictions through adaptive evidence gathering. Our code is available at https://github.com/Unknown-zoo/AgentMob.
Adaptor: Advancing Assistive Teleoperation with Few-Shot Learning and Cross-Operator Generalization
Apr 10, 2026Assistive teleoperation enhances efficiency via shared control, yet inter-operator variability, stemming from diverse habits and expertise, induces highly heterogeneous trajectory distributions that undermine intent recognition stability. We present Adaptor, a few-shot framework for robust cross-operator intent recognition. The Adaptor bridges the domain gap through two stages: (i) preprocessing, which models intent uncertainty by synthesizing trajectory perturbations via noise injection and performs geometry-aware keyframe extraction; and (ii) policy learning, which encodes the processed trajectories with an Intention Expert and fuses them with the pre-trained vision-language model context to condition an Action Expert for action generation. Experiments on real-world and simulated benchmarks demonstrate that Adaptor achieves state-of-the-art performance, improving success rates and efficiency over baselines. Moreover, the method exhibits low variance across operators with varying expertise, demonstrating robust cross-operator generalization.
Manifold-Aware Temporal Domain Generalization for Large Language Models
Feb 12, 2026Temporal distribution shifts are pervasive in real-world deployments of Large Language Models (LLMs), where data evolves continuously over time. While Temporal Domain Generalization (TDG) seeks to model such structured evolution, existing approaches characterize model adaptation in the full parameter space. This formulation becomes computationally infeasible for modern LLMs. This paper introduces a geometric reformulation of TDG under parameter-efficient fine-tuning. We establish that the low-dimensional temporal structure underlying model evolution can be preserved under parameter-efficient reparameterization, enabling temporal modeling without operating in the ambient parameter space. Building on this principle, we propose Manifold-aware Temporal LoRA (MaT-LoRA), which constrains temporal updates to a shared low-dimensional manifold within a low-rank adaptation subspace, and models its evolution through a structured temporal core. This reparameterization dramatically reduces temporal modeling complexity while retaining expressive power. Extensive experiments on synthetic and real-world datasets, including scientific documents, news publishers, and review ratings, demonstrate that MaT-LoRA achieves superior temporal generalization performance with practical scalability for LLMs.
MetaGen: Self-Evolving Roles and Topologies for Multi-Agent LLM Reasoning
Jan 27, 2026Large language models are increasingly deployed as multi-agent systems, where specialized roles communicate and collaborate through structured interactions to solve complex tasks that often exceed the capacity of a single agent. However, most existing systems still rely on a fixed role library and an execution-frozen interaction topology, a rigid design choice that frequently leads to task mismatch, prevents timely adaptation when new evidence emerges during reasoning, and further inflates inference cost. We introduce MetaGen, a training-free framework that adapts both the role space and the collaboration topology at inference time, without updating base model weights. MetaGen generates and rewrites query-conditioned role specifications to maintain a controllable dynamic role pool, then instantiates a constrained execution graph around a minimal backbone. During execution, it iteratively updates role prompts and adjusts structural decisions using lightweight feedback signals. Experiments on code generation and multi-step reasoning benchmarks show that MetaGen improves the accuracy and cost tradeoff over strong multi-agent baselines.
HarmoQ: Harmonized Post-Training Quantization for High-Fidelity Image
Nov 11, 2025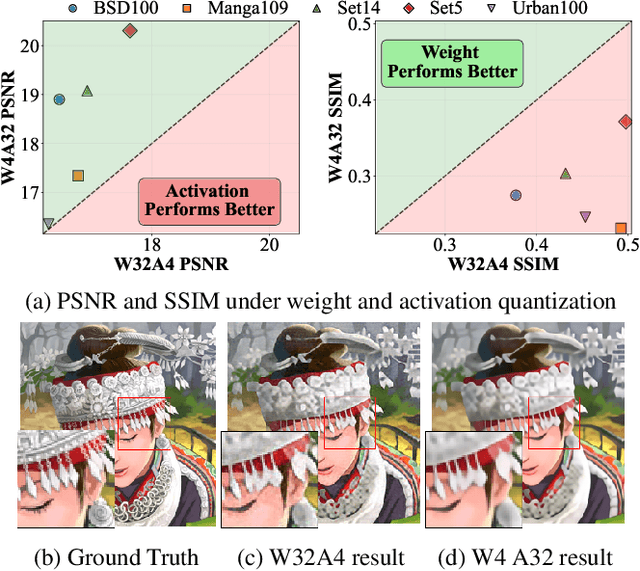
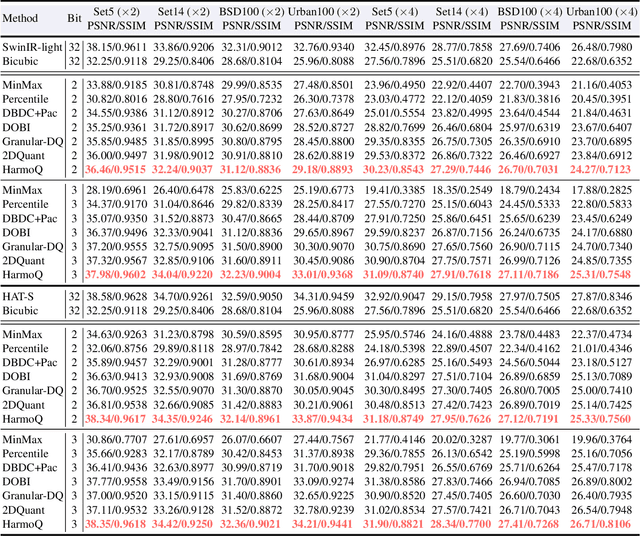
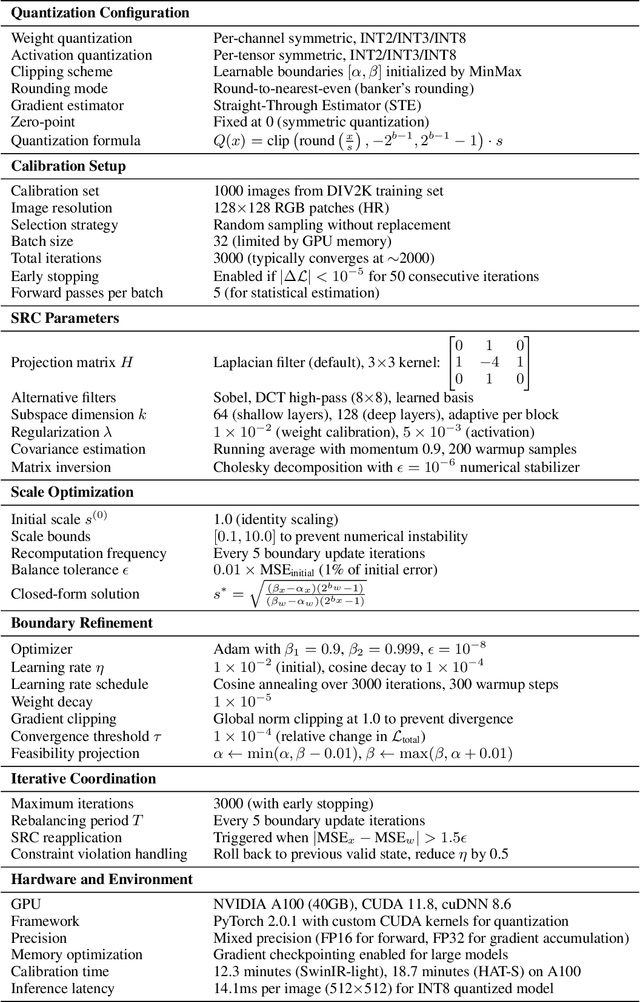
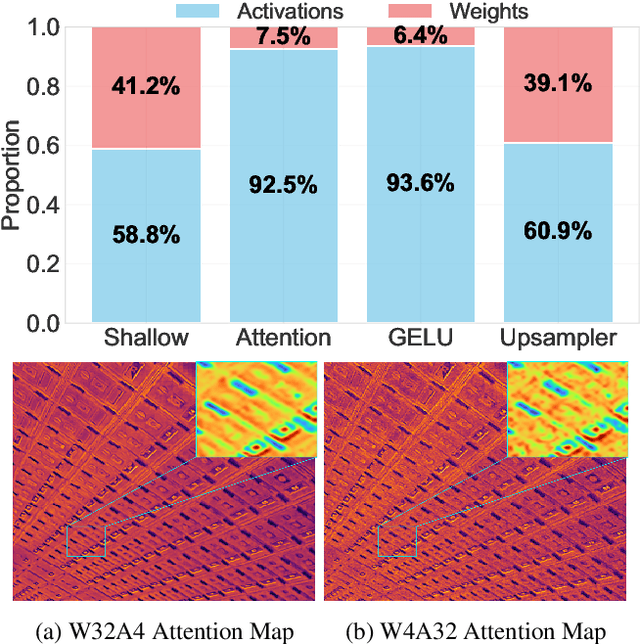
Post-training quantization offers an efficient pathway to deploy super-resolution models, yet existing methods treat weight and activation quantization independently, missing their critical interplay. Through controlled experiments on SwinIR, we uncover a striking asymmetry: weight quantization primarily degrades structural similarity, while activation quantization disproportionately affects pixel-level accuracy. This stems from their distinct roles--weights encode learned restoration priors for textures and edges, whereas activations carry input-specific intensity information. Building on this insight, we propose HarmoQ, a unified framework that harmonizes quantization across components through three synergistic steps: structural residual calibration proactively adjusts weights to compensate for activation-induced detail loss, harmonized scale optimization analytically balances quantization difficulty via closed-form solutions, and adaptive boundary refinement iteratively maintains this balance during optimization. Experiments show HarmoQ achieves substantial gains under aggressive compression, outperforming prior art by 0.46 dB on Set5 at 2-bit while delivering 3.2x speedup and 4x memory reduction on A100 GPUs. This work provides the first systematic analysis of weight-activation coupling in super-resolution quantization and establishes a principled solution for efficient high-quality image restoration.
Resilience Inference for Supply Chains with Hypergraph Neural Network
Nov 09, 2025Supply chains are integral to global economic stability, yet disruptions can swiftly propagate through interconnected networks, resulting in substantial economic impacts. Accurate and timely inference of supply chain resilience the capability to maintain core functions during disruptions is crucial for proactive risk mitigation and robust network design. However, existing approaches lack effective mechanisms to infer supply chain resilience without explicit system dynamics and struggle to represent the higher-order, multi-entity dependencies inherent in supply chain networks. These limitations motivate the definition of a novel problem and the development of targeted modeling solutions. To address these challenges, we formalize a novel problem: Supply Chain Resilience Inference (SCRI), defined as predicting supply chain resilience using hypergraph topology and observed inventory trajectories without explicit dynamic equations. To solve this problem, we propose the Supply Chain Resilience Inference Hypergraph Network (SC-RIHN), a novel hypergraph-based model leveraging set-based encoding and hypergraph message passing to capture multi-party firm-product interactions. Comprehensive experiments demonstrate that SC-RIHN significantly outperforms traditional MLP, representative graph neural network variants, and ResInf baselines across synthetic benchmarks, underscoring its potential for practical, early-warning risk assessment in complex supply chain systems.
TraceTrans: Translation and Spatial Tracing for Surgical Prediction
Oct 25, 2025Image-to-image translation models have achieved notable success in converting images across visual domains and are increasingly used for medical tasks such as predicting post-operative outcomes and modeling disease progression. However, most existing methods primarily aim to match the target distribution and often neglect spatial correspondences between the source and translated images. This limitation can lead to structural inconsistencies and hallucinations, undermining the reliability and interpretability of the predictions. These challenges are accentuated in clinical applications by the stringent requirement for anatomical accuracy. In this work, we present TraceTrans, a novel deformable image translation model designed for post-operative prediction that generates images aligned with the target distribution while explicitly revealing spatial correspondences with the pre-operative input. The framework employs an encoder for feature extraction and dual decoders for predicting spatial deformations and synthesizing the translated image. The predicted deformation field imposes spatial constraints on the generated output, ensuring anatomical consistency with the source. Extensive experiments on medical cosmetology and brain MRI datasets demonstrate that TraceTrans delivers accurate and interpretable post-operative predictions, highlighting its potential for reliable clinical deployment.
Not All Degradations Are Equal: A Targeted Feature Denoising Framework for Generalizable Image Super-Resolution
Sep 18, 2025Generalizable Image Super-Resolution aims to enhance model generalization capabilities under unknown degradations. To achieve this goal, the models are expected to focus only on image content-related features instead of overfitting degradations. Recently, numerous approaches such as Dropout and Feature Alignment have been proposed to suppress models' natural tendency to overfit degradations and yield promising results. Nevertheless, these works have assumed that models overfit to all degradation types (e.g., blur, noise, JPEG), while through careful investigations in this paper, we discover that models predominantly overfit to noise, largely attributable to its distinct degradation pattern compared to other degradation types. In this paper, we propose a targeted feature denoising framework, comprising noise detection and denoising modules. Our approach presents a general solution that can be seamlessly integrated with existing super-resolution models without requiring architectural modifications. Our framework demonstrates superior performance compared to previous regularization-based methods across five traditional benchmarks and datasets, encompassing both synthetic and real-world scenarios.
Connecting the Dots: A Chain-of-Collaboration Prompting Framework for LLM Agents
May 16, 2025Large Language Models (LLMs) have demonstrated impressive performance in executing complex reasoning tasks. Chain-of-thought effectively enhances reasoning capabilities by unlocking the potential of large models, while multi-agent systems provide more comprehensive solutions by integrating collective intelligence of multiple agents. However, both approaches face significant limitations. Single-agent with chain-of-thought, due to the inherent complexity of designing cross-domain prompts, faces collaboration challenges. Meanwhile, multi-agent systems consume substantial tokens and inevitably dilute the primary problem, which is particularly problematic in business workflow tasks. To address these challenges, we propose Cochain, a collaboration prompting framework that effectively solves business workflow collaboration problem by combining knowledge and prompts at a reduced cost. Specifically, we construct an integrated knowledge graph that incorporates knowledge from multiple stages. Furthermore, by maintaining and retrieving a prompts tree, we can obtain prompt information relevant to other stages of the business workflow. We perform extensive evaluations of Cochain across multiple datasets, demonstrating that Cochain outperforms all baselines in both prompt engineering and multi-agent LLMs. Additionally, expert evaluation results indicate that the use of a small model in combination with Cochain outperforms GPT-4.
Unveiling the Inflexibility of Adaptive Embedding in Traffic Forecasting
Nov 18, 2024



Spatiotemporal Graph Neural Networks (ST-GNNs) and Transformers have shown significant promise in traffic forecasting by effectively modeling temporal and spatial correlations. However, rapid urbanization in recent years has led to dynamic shifts in traffic patterns and travel demand, posing major challenges for accurate long-term traffic prediction. The generalization capability of ST-GNNs in extended temporal scenarios and cross-city applications remains largely unexplored. In this study, we evaluate state-of-the-art models on an extended traffic benchmark and observe substantial performance degradation in existing ST-GNNs over time, which we attribute to their limited inductive capabilities. Our analysis reveals that this degradation stems from an inability to adapt to evolving spatial relationships within urban environments. To address this limitation, we reconsider the design of adaptive embeddings and propose a Principal Component Analysis (PCA) embedding approach that enables models to adapt to new scenarios without retraining. We incorporate PCA embeddings into existing ST-GNN and Transformer architectures, achieving marked improvements in performance. Notably, PCA embeddings allow for flexibility in graph structures between training and testing, enabling models trained on one city to perform zero-shot predictions on other cities. This adaptability demonstrates the potential of PCA embeddings in enhancing the robustness and generalization of spatiotemporal models.