 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-Aware Temporal Domain Generalization for Large Language Models
Feb 12, 2026Temporal distribution shifts are pervasive in real-world deployments of Large Language Models (LLMs), where data evolves continuously over time. While Temporal Domain Generalization (TDG) seeks to model such structured evolution, existing approaches characterize model adaptation in the full parameter space. This formulation becomes computationally infeasible for modern LLMs. This paper introduces a geometric reformulation of TDG under parameter-efficient fine-tuning. We establish that the low-dimensional temporal structure underlying model evolution can be preserved under parameter-efficient reparameterization, enabling temporal modeling without operating in the ambient parameter space. Building on this principle, we propose Manifold-aware Temporal LoRA (MaT-LoRA), which constrains temporal updates to a shared low-dimensional manifold within a low-rank adaptation subspace, and models its evolution through a structured temporal core. This reparameterization dramatically reduces temporal modeling complexity while retaining expressive power. Extensive experiments on synthetic and real-world datasets, including scientific documents, news publishers, and review ratings, demonstrate that MaT-LoRA achieves superior temporal generalization performance with practical scalability for LLMs.
Continuous Temporal Domain Generalization
May 25, 2024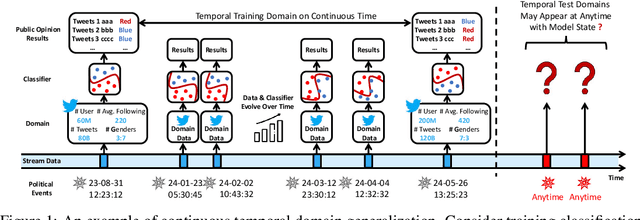
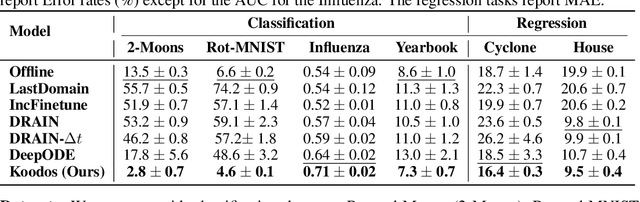

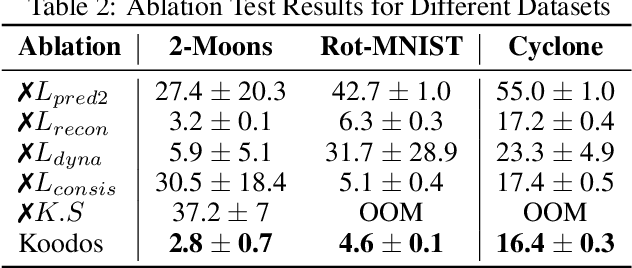
Temporal Domain Generalization (TDG) addresses the challenge of training predictive models under temporally varying data distributions. Traditional TDG approaches typically focus on domain data collected at fixed, discrete time intervals, which limits their capability to capture the inherent dynamics within continuous-evolving and irregularly-observed temporal domains. To overcome this, this work formalizes the concept of Continuous Temporal Domain Generalization (CTDG), where domain data are derived from continuous times and are collected at arbitrary times. CTDG tackles critical challenges including: 1) Characterizing the continuous dynamics of both data and models, 2) Learning complex high-dimensional nonlinear dynamics, and 3) Optimizing and controlling the generalization across continuous temporal domains. To address them, we propose a Koopman operator-driven continuous temporal domain generalization (Koodos) framework. We formulate the problem within a continuous dynamic system and leverage the Koopman theory to learn the underlying dynamics; the framework is further enhanced with a comprehensive optimization strategy equipped with analysis and control driven by prior knowledge of the dynamics patterns. Extensive experiments demonstrate the effectiveness and efficiency of our approach.
MemDA: Forecasting Urban Time Series with Memory-based Drift Adaptation
Sep 25, 2023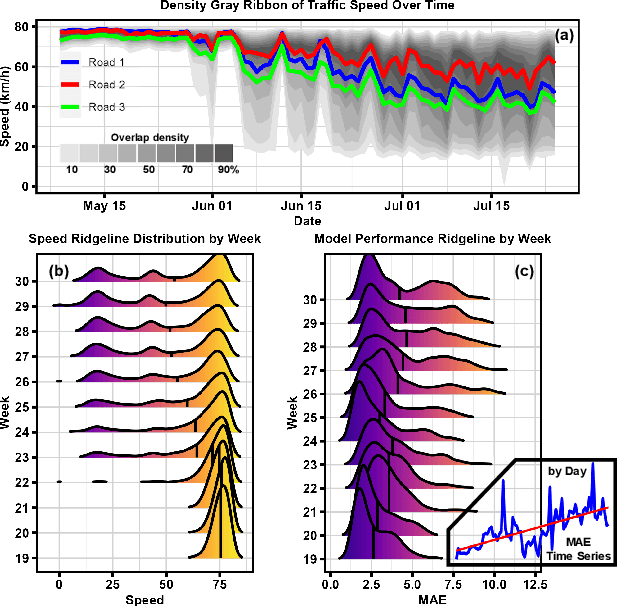



Urban time series data forecasting featuring significant contributions to sustainable development is widely studied as an essential task of the smart city. However, with the dramatic and rapid changes in the world environment, the assumption that data obey Independent Identically Distribution is undermined by the subsequent changes in data distribution, known as concept drift, leading to weak replicability and transferability of the model over unseen data. To address the issue, previous approaches typically retrain the model, forcing it to fit the most recent observed data. However, retraining is problematic in that it leads to model lag, consumption of resources, and model re-invalidation, causing the drift problem to be not well solved in realistic scenarios. In this study, we propose a new urban time series prediction model for the concept drift problem, which encodes the drift by considering the periodicity in the data and makes on-the-fly adjustments to the model based on the drift using a meta-dynamic network. Experiments on real-world datasets show that our design significantly outperforms state-of-the-art methods and can be well generalized to existing prediction backbones by reducing their sensitivity to distribution changes.
Real-World Video for Zoom Enhancement based on Spatio-Temporal Coupling
Jun 24, 2023



In recent years, single-frame image super-resolution (SR) has become more realistic by considering the zooming effect and using real-world short- and long-focus image pairs. In this paper, we further investigate the feasibility of applying realistic multi-frame clips to enhance zoom quality via spatio-temporal information coupling. Specifically, we first built a real-world video benchmark, VideoRAW, by a synchronized co-axis optical system. The dataset contains paired short-focus raw and long-focus sRGB videos of different dynamic scenes. Based on VideoRAW, we then presented a Spatio-Temporal Coupling Loss, termed as STCL. The proposed STCL is intended for better utilization of information from paired and adjacent frames to align and fuse features both temporally and spatially at the feature level. The outperformed experimental results obtained in different zoom scenarios demonstrate the superiority of integrating real-world video dataset and STCL into existing SR models for zoom quality enhancement, and reveal that the proposed method can serve as an advanced and viable tool for video zoom.
ST-ExpertNet: A Deep Expert Framework for Traffic Prediction
May 05, 2022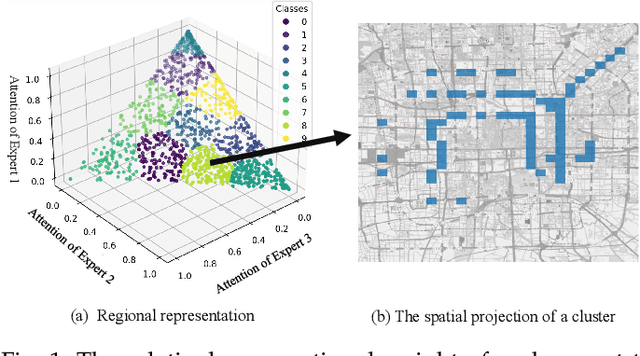

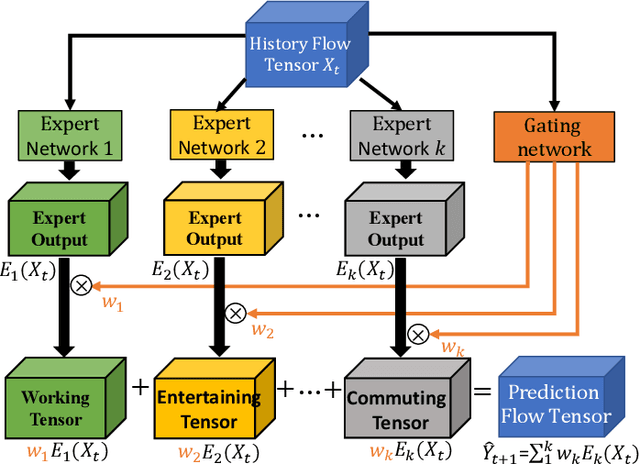
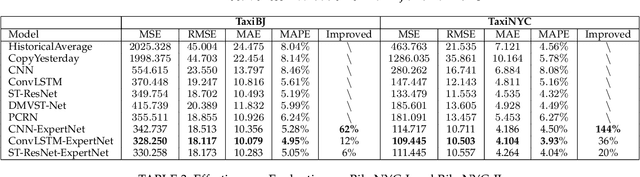
Recently, forecasting the crowd flows has become an important research topic, and plentiful technologies have achieved good performances. As we all know, the flow at a citywide level is in a mixed state with several basic patterns (e.g., commuting, working, and commercial) caused by the city area functional distributions (e.g., developed commercial areas, educational areas and parks). However, existing technologies have been criticized for their lack of considering the differences in the flow patterns among regions since they want to build only one comprehensive model to learn the mixed flow tensors. Recognizing this limitation, we present a new perspective on flow prediction and propose an explainable framework named ST-ExpertNet, which can adopt every spatial-temporal model and train a set of functional experts devoted to specific flow patterns. Technically, we train a bunch of experts based on the Mixture of Experts (MoE), which guides each expert to specialize in different kinds of flow patterns in sample spaces by using the gating network. We define several criteria, including comprehensiveness, sparsity, and preciseness, to construct the experts for better interpretability and performances. We conduct experiments on a wide range of real-world taxi and bike datasets in Beijing and NYC. The visualizations of the expert's intermediate results demonstrate that our ST-ExpertNet successfully disentangles the city's mixed flow tensors along with the city layout, e.g., the urban ring road structure. Different network architectures, such as ST-ResNet, ConvLSTM, and CNN, have been adopted into our ST-ExpertNet framework for experiments and the results demonstrates the superiority of our framework in both interpretability and performances.
DL-Traff: Survey and Benchmark of Deep Learning Models for Urban Traffic Prediction
Aug 20, 2021
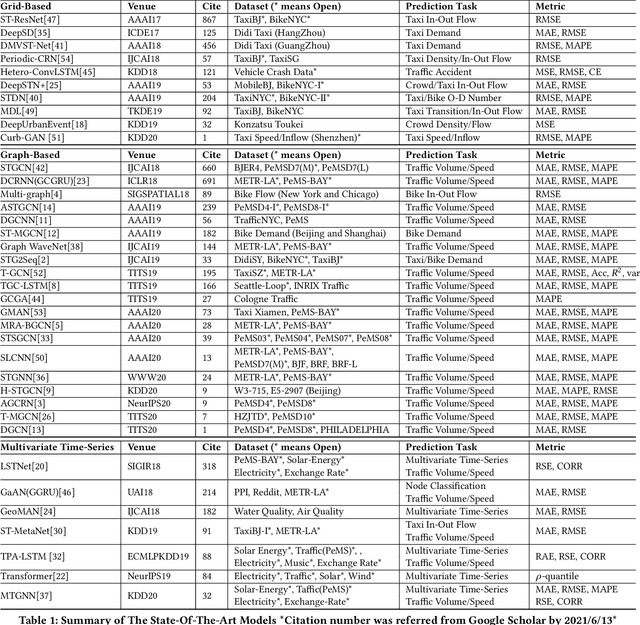
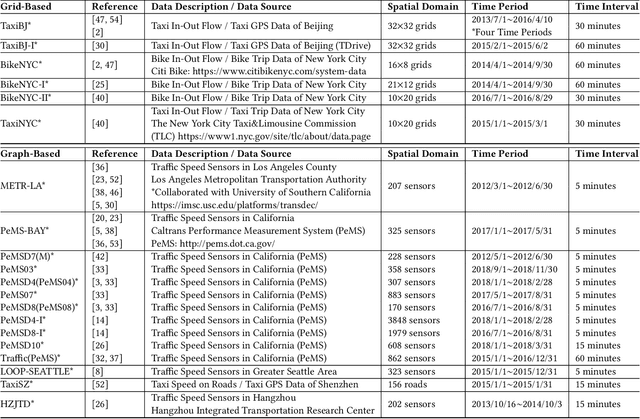
Nowadays, with the rapid development of IoT (Internet of Things) and CPS (Cyber-Physical Systems) technologies, big spatiotemporal data are being generated from mobile phones, car navigation systems, and traffic sensors. By leveraging state-of-the-art deep learning technologies on such data, urban traffic prediction has drawn a lot of attention in AI and Intelligent Transportation System community. The problem can be uniformly modeled with a 3D tensor (T, N, C), where T denotes the total time steps, N denotes the size of the spatial domain (i.e., mesh-grids or graph-nodes), and C denotes the channels of information. According to the specific modeling strategy, the state-of-the-art deep learning models can be divided into three categories: grid-based, graph-based, and multivariate time-series models. In this study, we first synthetically review the deep traffic models as well as the widely used datasets, then build a standard benchmark to comprehensively evaluate their performances with the same settings and metrics. Our study named DL-Traff is implemented with two most popular deep learning frameworks, i.e., TensorFlow and PyTorch, which is already publicly available as two GitHub repositories https://github.com/deepkashiwa20/DL-Traff-Grid and https://github.com/deepkashiwa20/DL-Traff-Graph. With DL-Traff, we hope to deliver a useful resource to researchers who are interested in spatiotemporal data analysis.
VLUC: An Empirical Benchmark for Video-Like Urban Computing on Citywide Crowd and Traffic Prediction
Nov 16, 2019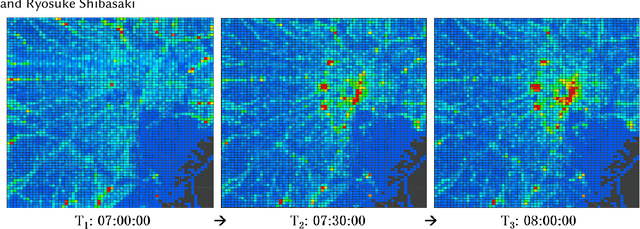
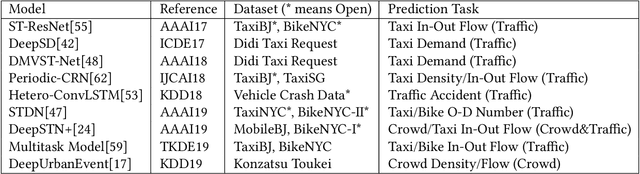
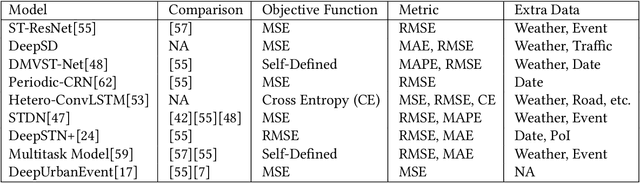
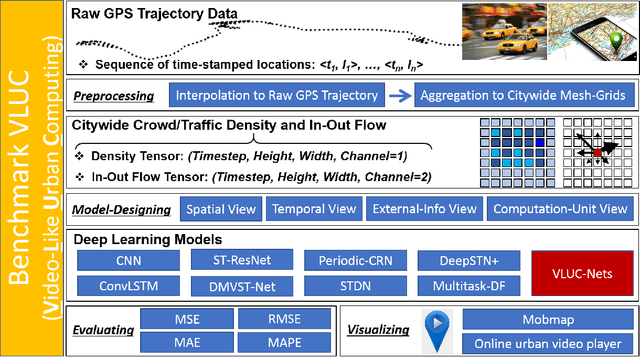
Nowadays, massive urban human mobility data are being generated from mobile phones, car navigation systems, and traffic sensors. Predicting the density and flow of the crowd or traffic at a citywide level becomes possible by using the big data and cutting-edge AI technologies. It has been a very significant research topic with high social impact, which can be widely applied to emergency management, traffic regulation, and urban planning. In particular, by meshing a large urban area to a number of fine-grained mesh-grids, citywide crowd and traffic information in a continuous time period can be represented like a video, where each timestamp can be seen as one video frame. Based on this idea, a series of methods have been proposed to address video-like prediction for citywide crowd and traffic. In this study, we publish a new aggregated human mobility dataset generated from a real-world smartphone application and build a standard benchmark for such kind of video-like urban computing with this new dataset and the existing open datasets. We first comprehensively review the state-of-the-art works of literature and formulate the density and in-out flow prediction problem, then conduct a thorough performance assessment for those methods. With this benchmark, we hope researchers can easily follow up and quickly launch a new solution on this topic.