 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Estimation of Building-Integrated Facade and Rooftop Photovoltaic Potential by Integrating 3D Building Footprint and Spatio-Temporal Datasets
Dec 02, 2024This research tackles the challenges of estimating Building-Integrated Photovoltaics (BIPV) potential across various temporal and spatial scales, accounting for different geographical climates and urban morphology. We introduce a holistic methodology for evaluating BIPV potential, integrating 3D building footprint models with diverse meteorological data sources to account for dynamic shadow effects. The approach enables the assessment of PV potential on facades and rooftops at different levels-individual buildings, urban blocks, and cities globally. Through an analysis of 120 typical cities, we highlight the importance of 3D building forms, cityscape morphology, and geographic positioning in measuring BIPV potential at various levels. In particular, our simulation study reveals that among cities with optimal facade PV performance, the average ratio of facade PV potential to rooftop PV potential is approximately 68.2%. Additionally, approximately 17.5% of the analyzed samples demonstrate even higher facade PV potentials compared to rooftop installations. This finding underscores the strategic value of incorporating facade PV applications into urban sustainable energy systems.
Enhancing Building Semantic Segmentation Accuracy with Super Resolution and Deep Learning: Investigating the Impact of Spatial Resolution on Various Datasets
Jul 09, 2023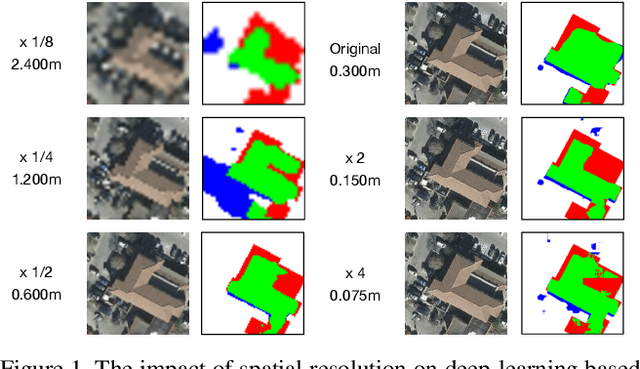
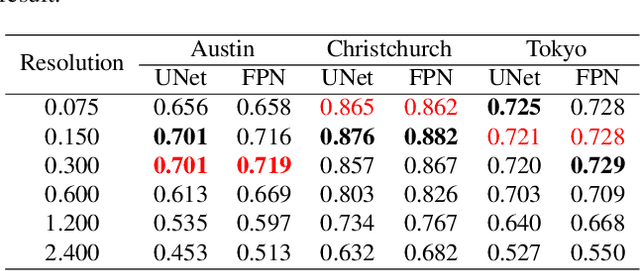

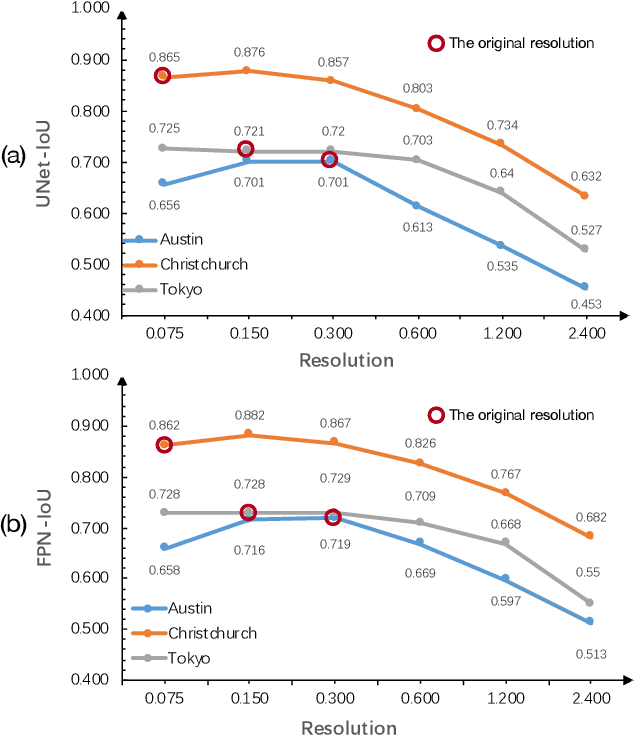
The development of remote sensing and deep learning techniques has enabled building semantic segmentation with high accuracy and efficiency. Despite their success in different tasks, the discussions on the impact of spatial resolution on deep learning based building semantic segmentation are quite inadequate, which makes choosing a higher cost-effective data source a big challenge. To address the issue mentioned above, in this study, we create remote sensing images among three study areas into multiple spatial resolutions by super-resolution and down-sampling. After that, two representative deep learning architectures: UNet and FPN, are selected for model training and testing. The experimental results obtained from three cities with two deep learning models indicate that the spatial resolution greatly influences building segmentation results, and with a better cost-effectiveness around 0.3m, which we believe will be an important insight for data selection and preparation.
Real-World Video for Zoom Enhancement based on Spatio-Temporal Coupling
Jun 24, 2023



In recent years, single-frame image super-resolution (SR) has become more realistic by considering the zooming effect and using real-world short- and long-focus image pairs. In this paper, we further investigate the feasibility of applying realistic multi-frame clips to enhance zoom quality via spatio-temporal information coupling. Specifically, we first built a real-world video benchmark, VideoRAW, by a synchronized co-axis optical system. The dataset contains paired short-focus raw and long-focus sRGB videos of different dynamic scenes. Based on VideoRAW, we then presented a Spatio-Temporal Coupling Loss, termed as STCL. The proposed STCL is intended for better utilization of information from paired and adjacent frames to align and fuse features both temporally and spatially at the feature level. The outperformed experimental results obtained in different zoom scenarios demonstrate the superiority of integrating real-world video dataset and STCL into existing SR models for zoom quality enhancement, and reveal that the proposed method can serve as an advanced and viable tool for video zoom.
Semantic Segmentation for Urban Planning Maps based on U-Net
Oct 01, 2018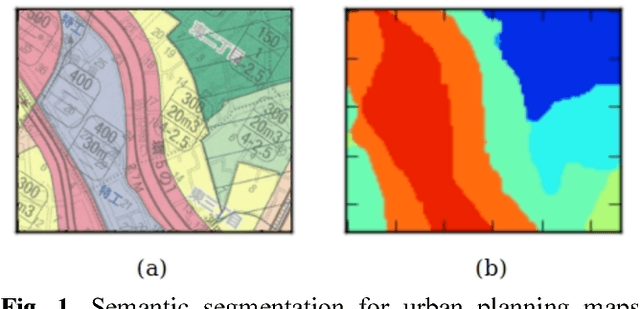
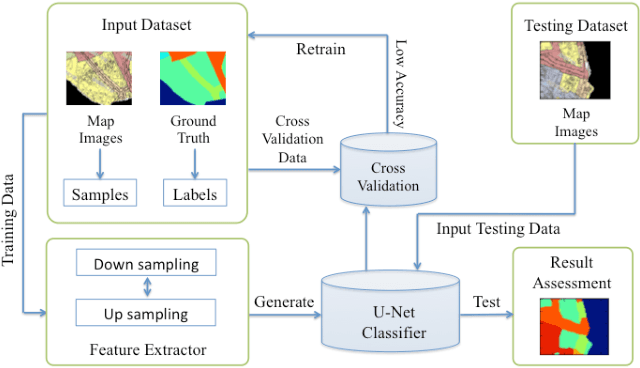
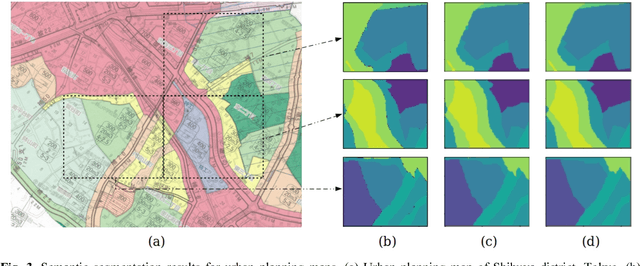
The automatic digitizing of paper maps is a significant and challenging task for both academia and industry. As an important procedure of map digitizing, the semantic segmentation section mainly relies on manual visual interpretation with low efficiency. In this study, we select urban planning maps as a representative sample and investigate the feasibility of utilizing U-shape fully convolutional based architecture to perform end-to-end map semantic segmentation. The experimental results obtained from the test area in Shibuya district, Tokyo, demonstrate that our proposed method could achieve a very high Jaccard similarity coefficient of 93.63% and an overall accuracy of 99.36%. For implementation on GPGPU and cuDNN, the required processing time for the whole Shibuya district can be less than three minutes. The results indicate the proposed method can serve as a viable tool for urban planning map semantic segmentation task with high accuracy and efficiency.
Geoseg: A Computer Vision Package for Automatic Building Segmentation and Outline Extraction
Sep 10, 2018
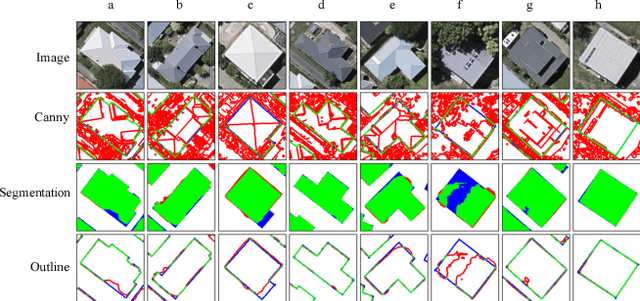
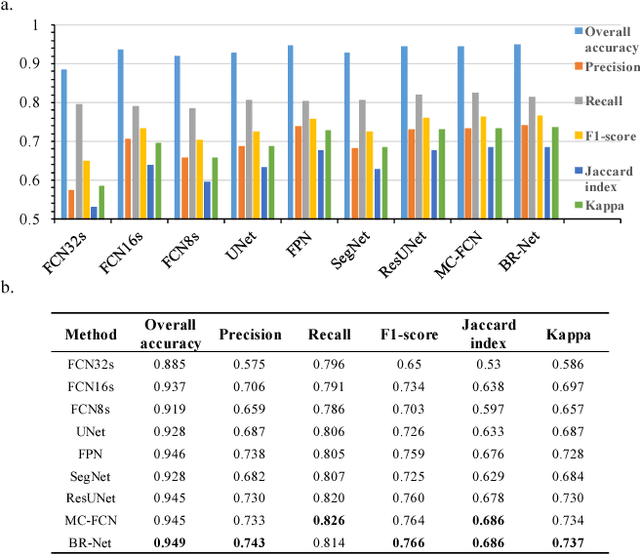
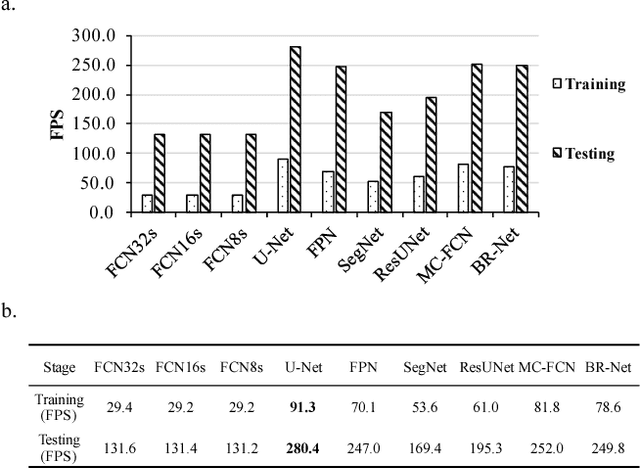
Recently, deep learning algorithms, especially fully convolutional network based methods, are becoming very popular in the field of remote sensing. However, these methods are implemented and evaluated through various datasets and deep learning frameworks. There has not been a package that covers these methods in a unifying manner. In this study, we introduce a computer vision package termed Geoseg that focus on building segmentation and outline extraction. Geoseg implements over nine state-of-the-art models as well as utility scripts needed to conduct model training, logging, evaluating and visualization. The implementation of Geoseg emphasizes unification, simplicity, and flexibility. The performance and computational efficiency of all implemented methods are evaluated by comparison experiment through a unified, high-quality aerial image dataset.
Aerial Imagery for Roof Segmentation: A Large-Scale Dataset towards Automatic Mapping of Buildings
Jul 27, 2018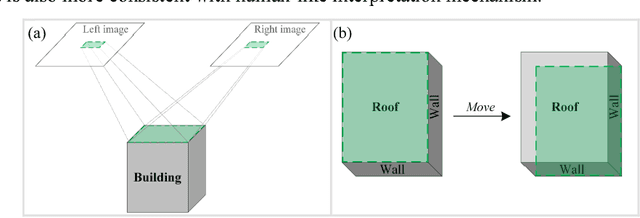
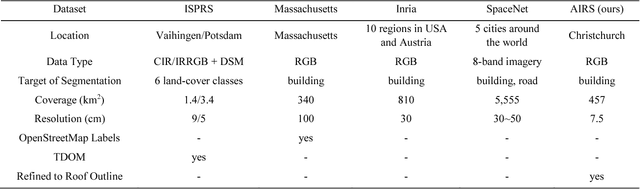
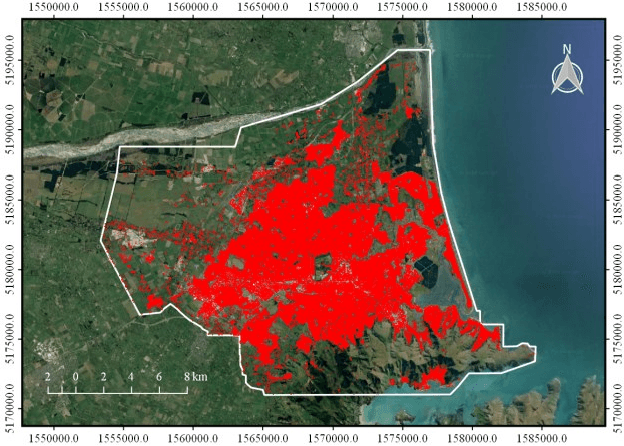
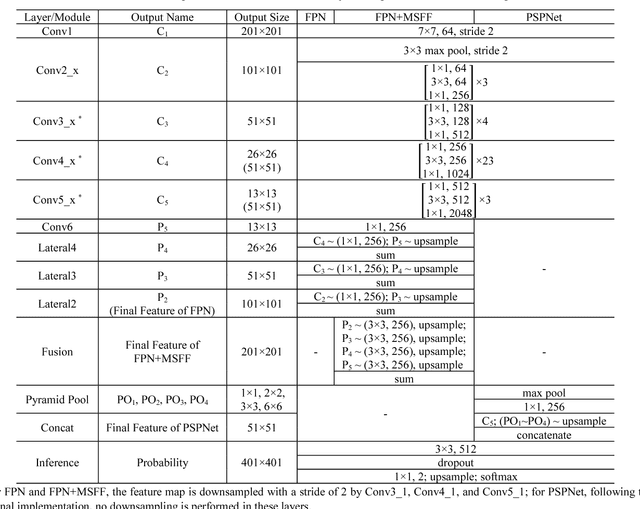
As an important branch of deep learning, convolutional neural network has largely improved the performance of building detection. For further accelerating the development of building detection toward automatic mapping, a benchmark dataset bears significance in fair comparisons. However, several problems still remain in the current public datasets that address this task. First, although building detection is generally considered equivalent to extracting roof outlines, most datasets directly provide building footprints as ground truths for testing and evaluation; the challenges of these benchmarks are more complicated than roof segmentation, as relief displacement leads to varying degrees of misalignment between roof outlines and footprints. On the other hand, an image dataset should feature a large quantity and high spatial resolution to effectively train a high-performance deep learning model for accurate mapping of buildings. Unfortunately, the remote sensing community still lacks proper benchmark datasets that can simultaneously satisfy these requirements. In this paper, we present a new large-scale benchmark dataset termed Aerial Imagery for Roof Segmentation (AIRS). This dataset provides a wide coverage of aerial imagery with 7.5 cm resolution and contains over 220,000 buildings. The task posed for AIRS is defined as roof segmentation. We implement several state-of-the-art deep learning methods of semantic segmentation for performance evaluation and analysis of the proposed dataset. The results can serve as the baseline for future work.