 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMGenDrive: Bridging Multimodal Understanding and Generative World Modeling for End-to-End Driving
Apr 09, 2026Recent years have seen remarkable progress in autonomous driving, yet generalization to long-tail and open-world scenarios remains a major bottleneck for large-scale deployment. To address this challenge, some works use LLMs and VLMs for vision-language understanding and reasoning, enabling vehicles to interpret rare and safety-critical situations when generating actions. Others study generative world models to capture the spatio-temporal evolution of driving scenes, allowing agents to imagine possible futures before acting. Inspired by human intelligence, which unifies understanding and imagination, we explore a unified model for autonomous driving. We present LMGenDrive, the first framework that combines LLM-based multimodal understanding with generative world models for end-to-end closed-loop driving. Given multi-view camera inputs and natural-language instructions, LMGenDrive generates both future driving videos and control signals. This design provides complementary benefits: video prediction improves spatio-temporal scene modeling, while the LLM contributes strong semantic priors and instruction grounding from large-scale pretraining. We further propose a progressive three-stage training strategy, from vision pretraining to multi-step long-horizon driving, to improve stability and performance. LMGenDrive supports both low-latency online planning and autoregressive offline video generation. Experiments show that it significantly outperforms prior methods on challenging closed-loop benchmarks, with clear gains in instruction following, spatio-temporal understanding, and robustness to rare scenarios. These results suggest that unifying multimodal understanding and generation is a promising direction for more generalizable and robust embodied decision-making systems.
DriveDreamer-Policy: A Geometry-Grounded World-Action Model for Unified Generation and Planning
Apr 02, 2026Recently, world-action models (WAM) have emerged to bridge vision-language-action (VLA) models and world models, unifying their reasoning and instruction-following capabilities and spatio-temporal world modeling. However, existing WAM approaches often focus on modeling 2D appearance or latent representations, with limited geometric grounding-an essential element for embodied systems operating in the physical world. We present DriveDreamer-Policy, a unified driving world-action model that integrates depth generation, future video generation, and motion planning within a single modular architecture. The model employs a large language model to process language instructions, multi-view images, and actions, followed by three lightweight generators that produce depth, future video, and actions. By learning a geometry-aware world representation and using it to guide both future prediction and planning within a unified framework, the proposed model produces more coherent imagined futures and more informed driving actions, while maintaining modularity and controllable latency. Experiments on the Navsim v1 and v2 benchmarks demonstrate that DriveDreamer-Policy achieves strong performance on both closed-loop planning and world generation tasks. In particular, our model reaches 89.2 PDMS on Navsim v1 and 88.7 EPDMS on Navsim v2, outperforming existing world-model-based approaches while producing higher-quality future video and depth predictions. Ablation studies further show that explicit depth learning provides complementary benefits to video imagination and improves planning robustness.
SCATR: Mitigating New Instance Suppression in LiDAR-based Tracking-by-Attention via Second Chance Assignment and Track Query Dropout
Mar 02, 2026LiDAR-based tracking-by-attention (TBA) frameworks inherently suffer from high false negative errors, leading to a significant performance gap compared to traditional LiDAR-based tracking-by-detection (TBD) methods. This paper introduces SCATR, a novel LiDAR-based TBA model designed to address this fundamental challenge systematically. SCATR leverages recent progress in vision-based tracking and incorporates targeted training strategies specifically adapted for LiDAR. Our work's core innovations are two architecture-agnostic training strategies for TBA methods: Second Chance Assignment and Track Query Dropout. Second Chance Assignment is a novel ground truth assignment that concatenates unassigned track queries to the proposal queries before bipartite matching, giving these track queries a second chance to be assigned to a ground truth object and effectively mitigating the conflict between detection and tracking tasks inherent in tracking-by-attention. Track Query Dropout is a training method that diversifies supervised object query configurations to efficiently train the decoder to handle different track query sets, enhancing robustness to missing or newborn tracks. Experiments on the nuScenes tracking benchmark demonstrate that SCATR achieves state-of-the-art performance among LiDAR-based TBA methods, outperforming previous works by 7.6\% AMOTA and successfully bridging the long-standing performance gap between LiDAR-based TBA and TBD methods. Ablation studies further validate the effectiveness and generalization of Second Chance Assignment and Track Query Dropout. Code can be found at the following link: \href{https://github.com/TRAILab/SCATR}{https://github.com/TRAILab/SCATR}
CLIP Is Shortsighted: Paying Attention Beyond the First Sentence
Feb 25, 2026CLIP models learn transferable multi-modal features via image-text contrastive learning on internet-scale data. They are widely used in zero-shot classification, multi-modal retrieval, text-to-image diffusion, and as image encoders in large vision-language models. However, CLIP's pretraining is dominated by images paired with short captions, biasing the model toward encoding simple descriptions of salient objects and leading to coarse alignment on complex scenes and dense descriptions. While recent work mitigates this by fine-tuning on small-scale long-caption datasets, we identify an important common bias: both human- and LLM-generated long captions typically begin with a one-sentence summary followed by a detailed description. We show that this acts as a shortcut during training, concentrating attention on the opening sentence and early tokens and weakening alignment over the rest of the caption. To resolve this, we introduce DeBias-CLIP, which removes the summary sentence during training and applies sentence sub-sampling and text token padding to distribute supervision across all token positions. DeBias-CLIP achieves state-of-the-art long-text retrieval, improves short-text retrieval, and is less sensitive to sentence order permutations. It is a drop-in replacement for Long-CLIP with no additional trainable parameters.
ToaSt: Token Channel Selection and Structured Pruning for Efficient ViT
Feb 17, 2026Vision Transformers (ViTs) have achieved remarkable success across various vision tasks, yet their deployment is often hindered by prohibitive computational costs. While structured weight pruning and token compression have emerged as promising solutions, they suffer from prolonged retraining times and global propagation that creates optimization challenges, respectively. We propose ToaSt, a decoupled framework applying specialized strategies to distinct ViT components. We apply coupled head-wise structured pruning to Multi-Head Self-Attention modules, leveraging attention operation characteristics to enhance robustness. For Feed-Forward Networks (over 60\% of FLOPs), we introduce Token Channel Selection (TCS) that enhances compression ratios while avoiding global propagation issues. Our analysis reveals TCS effectively filters redundant noise during selection. Extensive evaluations across nine diverse models, including DeiT, ViT-MAE, and Swin Transformer, demonstrate that ToaSt achieves superior trade-offs between accuracy and efficiency, consistently outperforming existing baselines. On ViT-MAE-Huge, ToaSt achieves 88.52\% accuracy (+1.64 \%) with 39.4\% FLOPs reduction. ToaSt transfers effectively to downstream tasks, cccccachieving 52.2 versus 51.9 mAP on COCO object detection. Code and models will be released upon acceptance.
STaR: Scalable Task-Conditioned Retrieval for Long-Horizon Multimodal Robot Memory
Feb 12, 2026Mobile robots are often deployed over long durations in diverse open, dynamic scenes, including indoor setting such as warehouses and manufacturing facilities, and outdoor settings such as agricultural and roadway operations. A core challenge is to build a scalable long-horizon memory that supports an agentic workflow for planning, retrieval, and reasoning over open-ended instructions at variable granularity, while producing precise, actionable answers for navigation. We present STaR, an agentic reasoning framework that (i) constructs a task-agnostic, multimodal long-term memory that generalizes to unseen queries while preserving fine-grained environmental semantics (object attributes, spatial relations, and dynamic events), and (ii) introduces a Scalable Task Conditioned Retrieval algorithm based on the Information Bottleneck principle to extract from long-term memory a compact, non-redundant, information-rich set of candidate memories for contextual reasoning. We evaluate STaR on NaVQA (mixed indoor/outdoor campus scenes) and WH-VQA, a customized warehouse benchmark with many visually similar objects built with Isaac Sim, emphasizing contextual reasoning. Across the two datasets, STaR consistently outperforms strong baselines, achieving higher success rates and markedly lower spatial error. We further deploy STaR on a real Husky wheeled robot in both indoor and outdoor environments, demonstrating robust long horizon reasoning, scalability, and practical utility. Project Website: https://trailab.github.io/STaR-website/
DrivingGen: A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
Jan 04, 2026Video generation models, as one form of world models, have emerged as one of the most exciting frontiers in AI, promising agents the ability to imagine the future by modeling the temporal evolution of complex scenes. In autonomous driving, this vision gives rise to driving world models: generative simulators that imagine ego and agent futures, enabling scalable simulation, safe testing of corner cases, and rich synthetic data generation. Yet, despite fast-growing research activity, the field lacks a rigorous benchmark to measure progress and guide priorities. Existing evaluations remain limited: generic video metrics overlook safety-critical imaging factors; trajectory plausibility is rarely quantified; temporal and agent-level consistency is neglected; and controllability with respect to ego conditioning is ignored. Moreover, current datasets fail to cover the diversity of conditions required for real-world deployment. To address these gaps, we present DrivingGen, the first comprehensive benchmark for generative driving world models. DrivingGen combines a diverse evaluation dataset curated from both driving datasets and internet-scale video sources, spanning varied weather, time of day, geographic regions, and complex maneuvers, with a suite of new metrics that jointly assess visual realism, trajectory plausibility, temporal coherence, and controllability. Benchmarking 14 state-of-the-art models reveals clear trade-offs: general models look better but break physics, while driving-specific ones capture motion realistically but lag in visual quality. DrivingGen offers a unified evaluation framework to foster reliable, controllable, and deployable driving world models, enabling scalable simulation, planning, and data-driven decision-making.
Complete Gaussian Splats from a Single Image with Denoising Diffusion Models
Aug 29, 2025Gaussian splatting typically requires dense observations of the scene and can fail to reconstruct occluded and unobserved areas. We propose a latent diffusion model to reconstruct a complete 3D scene with Gaussian splats, including the occluded parts, from only a single image during inference. Completing the unobserved surfaces of a scene is challenging due to the ambiguity of the plausible surfaces. Conventional methods use a regression-based formulation to predict a single "mode" for occluded and out-of-frustum surfaces, leading to blurriness, implausibility, and failure to capture multiple possible explanations. Thus, they often address this problem partially, focusing either on objects isolated from the background, reconstructing only visible surfaces, or failing to extrapolate far from the input views. In contrast, we propose a generative formulation to learn a distribution of 3D representations of Gaussian splats conditioned on a single input image. To address the lack of ground-truth training data, we propose a Variational AutoReconstructor to learn a latent space only from 2D images in a self-supervised manner, over which a diffusion model is trained. Our method generates faithful reconstructions and diverse samples with the ability to complete the occluded surfaces for high-quality 360-degree renderings.
ForeSight: Multi-View Streaming Joint Object Detection and Trajectory Forecasting
Aug 09, 2025
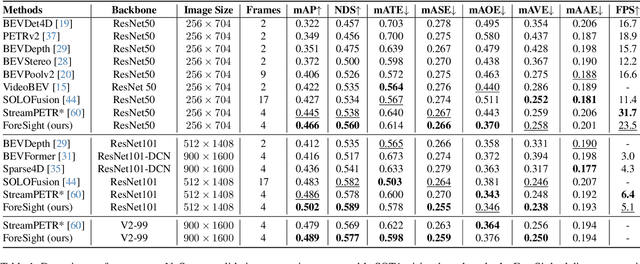

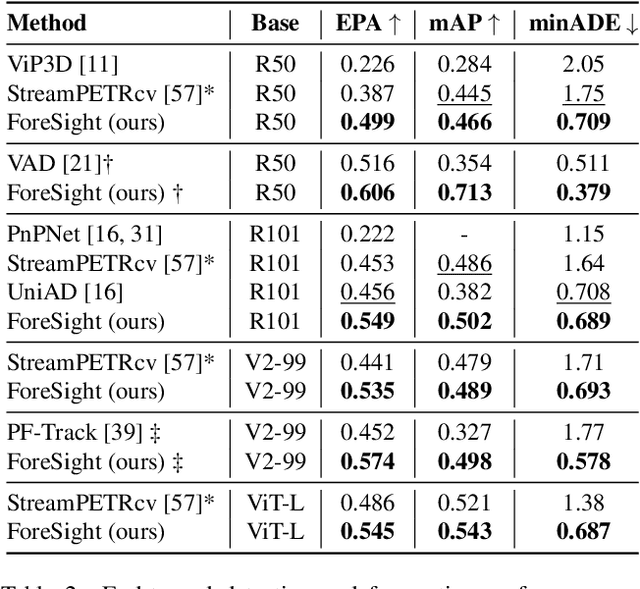
We introduce ForeSight, a novel joint detection and forecasting framework for vision-based 3D perception in autonomous vehicles. Traditional approaches treat detection and forecasting as separate sequential tasks, limiting their ability to leverage temporal cues. ForeSight addresses this limitation with a multi-task streaming and bidirectional learning approach, allowing detection and forecasting to share query memory and propagate information seamlessly. The forecast-aware detection transformer enhances spatial reasoning by integrating trajectory predictions from a multiple hypothesis forecast memory queue, while the streaming forecast transformer improves temporal consistency using past forecasts and refined detections. Unlike tracking-based methods, ForeSight eliminates the need for explicit object association, reducing error propagation with a tracking-free model that efficiently scales across multi-frame sequences. Experiments on the nuScenes dataset show that ForeSight achieves state-of-the-art performance, achieving an EPA of 54.9%, surpassing previous methods by 9.3%, while also attaining the best mAP and minADE among multi-view detection and forecasting models.
OpenNav: Open-World Navigation with Multimodal Large Language Models
Jul 24, 2025



Pre-trained large language models (LLMs) have demonstrated strong common-sense reasoning abilities, making them promising for robotic navigation and planning tasks. However, despite recent progress, bridging the gap between language descriptions and actual robot actions in the open-world, beyond merely invoking limited predefined motion primitives, remains an open challenge. In this work, we aim to enable robots to interpret and decompose complex language instructions, ultimately synthesizing a sequence of trajectory points to complete diverse navigation tasks given open-set instructions and open-set objects. We observe that multi-modal large language models (MLLMs) exhibit strong cross-modal understanding when processing free-form language instructions, demonstrating robust scene comprehension. More importantly, leveraging their code-generation capability, MLLMs can interact with vision-language perception models to generate compositional 2D bird-eye-view value maps, effectively integrating semantic knowledge from MLLMs with spatial information from maps to reinforce the robot's spatial understanding. To further validate our approach, we effectively leverage large-scale autonomous vehicle datasets (AVDs) to validate our proposed zero-shot vision-language navigation framework in outdoor navigation tasks, demonstrating its capability to execute a diverse range of free-form natural language navigation instructions while maintaining robustness against object detection errors and linguistic ambiguities. Furthermore, we validate our system on a Husky robot in both indoor and outdoor scenes, demonstrating its real-world robustness and applicability. Supplementary videos are available at https://trailab.github.io/OpenNav-website/