 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANINE: Coaching Visually Impaired Users for Interactive Navigation with a Robot Guide Dog
May 19, 2026Robot guide dogs offer navigation assistance that greatly expands the independent mobility of the visually impaired, but their effective use requires subtle human-robot coordination that is difficult for users to learn from generic verbal instructions. To tackle this challenge, we present CANINE, an automated coaching system that trains users for interactive navigation with a robot guide dog, through personalized, adaptive verbal feedback. CANINE decomposes a complex coordination task into sub-skills and operates at two levels. At the high level, it decides what to train by tracking the learner's proficiency across sub-skills using knowledge tracing and prioritizing training on the weakest areas. At the low level, CANINE decides how to train each sub-skill by observing each human practice episode, using foundation models to infer the underlying causes of errors, and generating targeted verbal corrections adaptively. A controlled study with blindfolded participants, treated as a proxy population for quantitative evaluation, demonstrates that CANINE significantly improves both learning efficiency and final navigation performance compared to generic verbal instructions. We further validate CANINE through a retention study and an exploratory case study. The retention study shows lasting skill improvement after two weeks. The case study confirms CANINE's effectiveness in training a visually impaired user, while revealing additional design considerations for real-world deployment. Both are well aligned with the findings of the controlled study. Project page: https://cunjunyu.github.io/project/canine/
Robi Butler: Remote Multimodal Interactions with Household Robot Assistant
Sep 30, 2024In this paper, we introduce Robi Butler, a novel household robotic system that enables multimodal interactions with remote users. Building on the advanced communication interfaces, Robi Butler allows users to monitor the robot's status, send text or voice instructions, and select target objects by hand pointing. At the core of our system is a high-level behavior module, powered by Large Language Models (LLMs), that interprets multimodal instructions to generate action plans. These plans are composed of a set of open vocabulary primitives supported by Vision Language Models (VLMs) that handle both text and pointing queries. The integration of the above components allows Robi Butler to ground remote multimodal instructions in the real-world home environment in a zero-shot manner. We demonstrate the effectiveness and efficiency of this system using a variety of daily household tasks that involve remote users giving multimodal instructions. Additionally, we conducted a user study to analyze how multimodal interactions affect efficiency and user experience during remote human-robot interaction and discuss the potential improvements.
GSON: A Group-based Social Navigation Framework with Large Multimodal Model
Sep 26, 2024As the number of service robots and autonomous vehicles in human-centered environments grows, their requirements go beyond simply navigating to a destination. They must also take into account dynamic social contexts and ensure respect and comfort for others in shared spaces, which poses significant challenges for perception and planning. In this paper, we present a group-based social navigation framework GSON to enable mobile robots to perceive and exploit the social group of their surroundings by leveling the visual reasoning capability of the Large Multimodal Model (LMM). For perception, we apply visual prompting techniques to zero-shot extract the social relationship among pedestrians and combine the result with a robust pedestrian detection and tracking pipeline to alleviate the problem of low inference speed of the LMM. Given the perception result, the planning system is designed to avoid disrupting the current social structure. We adopt a social structure-based mid-level planner as a bridge between global path planning and local motion planning to preserve the global context and reactive response. The proposed method is validated on real-world mobile robot navigation tasks involving complex social structure understanding and reasoning. Experimental results demonstrate the effectiveness of the system in these scenarios compared with several baselines.
DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Jun 17, 2024



We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
Differentiable Particles for General-Purpose Deformable Object Manipulation
May 02, 2024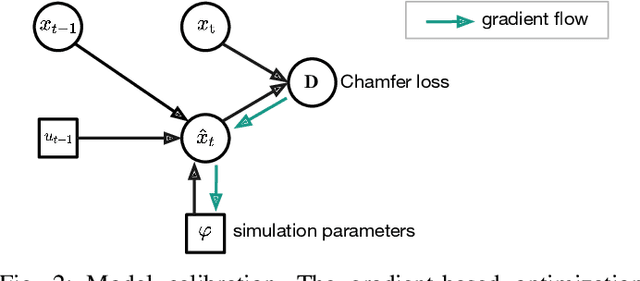
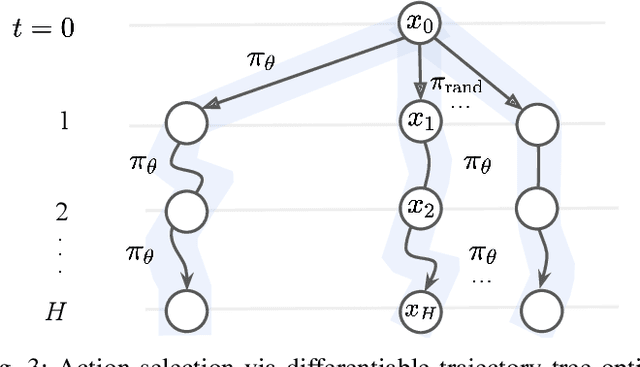

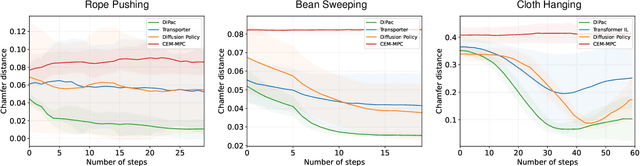
Deformable object manipulation is a long-standing challenge in robotics. While existing approaches often focus narrowly on a specific type of object, we seek a general-purpose algorithm, capable of manipulating many different types of objects: beans, rope, cloth, liquid, . . . . One key difficulty is a suitable representation, rich enough to capture object shape, dynamics for manipulation and yet simple enough to be acquired effectively from sensor data. Specifically, we propose Differentiable Particles (DiPac), a new algorithm for deformable object manipulation. DiPac represents a deformable object as a set of particles and uses a differentiable particle dynamics simulator to reason about robot manipulation. To find the best manipulation action, DiPac combines learning, planning, and trajectory optimization through differentiable trajectory tree optimization. Differentiable dynamics provides significant benefits and enable DiPac to (i) estimate the dynamics parameters efficiently, thereby narrowing the sim-to-real gap, and (ii) choose the best action by backpropagating the gradient along sampled trajectories. Both simulation and real-robot experiments show promising results. DiPac handles a variety of object types. By combining planning and learning, DiPac outperforms both pure model-based planning methods and pure data-driven learning methods. In addition, DiPac is robust and adapts to changes in dynamics, thereby enabling the transfer of an expert policy from one object to another with different physical properties, e.g., from a rigid rod to a deformable rope.
InsActor: Instruction-driven Physics-based Characters
Dec 28, 2023
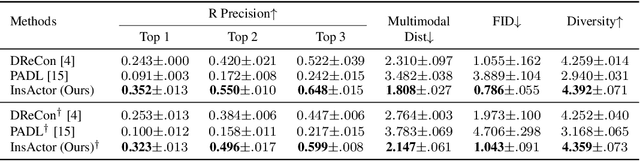
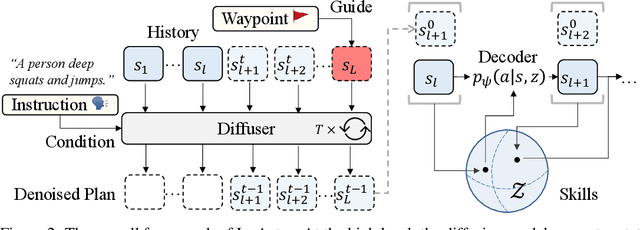
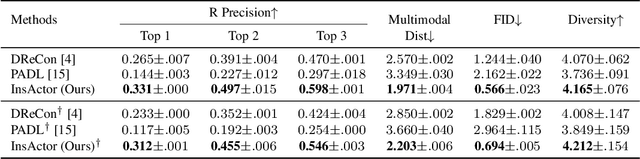
Generating animation of physics-based characters with intuitive control has long been a desirable task with numerous applications. However, generating physically simulated animations that reflect high-level human instructions remains a difficult problem due to the complexity of physical environments and the richness of human language. In this paper, we present InsActor, a principled generative framework that leverages recent advancements in diffusion-based human motion models to produce instruction-driven animations of physics-based characters. Our framework empowers InsActor to capture complex relationships between high-level human instructions and character motions by employing diffusion policies for flexibly conditioned motion planning. To overcome invalid states and infeasible state transitions in planned motions, InsActor discovers low-level skills and maps plans to latent skill sequences in a compact latent space. Extensive experiments demonstrate that InsActor achieves state-of-the-art results on various tasks, including instruction-driven motion generation and instruction-driven waypoint heading. Notably, the ability of InsActor to generate physically simulated animations using high-level human instructions makes it a valuable tool, particularly in executing long-horizon tasks with a rich set of instructions.
Vision-Language Foundation Models as Effective Robot Imitators
Nov 06, 2023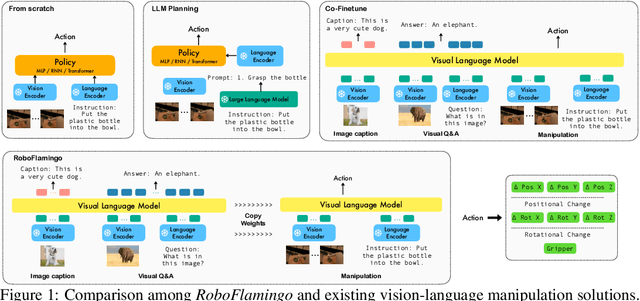
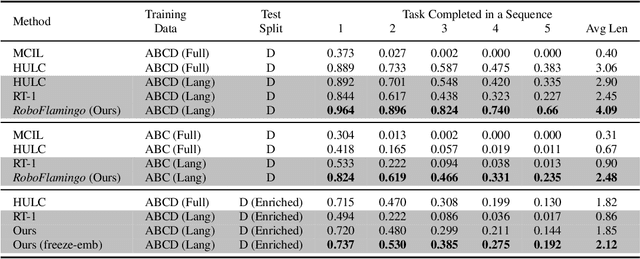
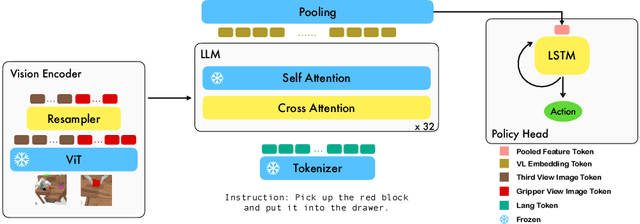
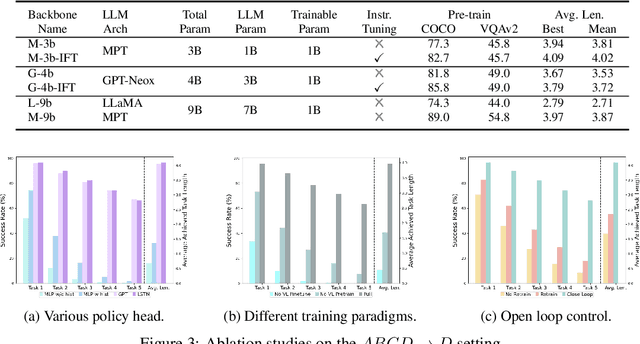
Recent progress in vision language foundation models has shown their ability to understand multimodal data and resolve complicated vision language tasks, including robotics manipulation. We seek a straightforward way of making use of existing vision-language models (VLMs) with simple fine-tuning on robotics data. To this end, we derive a simple and novel vision-language manipulation framework, dubbed RoboFlamingo, built upon the open-source VLMs, OpenFlamingo. Unlike prior works, RoboFlamingo utilizes pre-trained VLMs for single-step vision-language comprehension, models sequential history information with an explicit policy head, and is slightly fine-tuned by imitation learning only on language-conditioned manipulation datasets. Such a decomposition provides RoboFlamingo the flexibility for open-loop control and deployment on low-performance platforms. By exceeding the state-of-the-art performance with a large margin on the tested benchmark, we show RoboFlamingo can be an effective and competitive alternative to adapt VLMs to robot control. Our extensive experimental results also reveal several interesting conclusions regarding the behavior of different pre-trained VLMs on manipulation tasks. We believe RoboFlamingo has the potential to be a cost-effective and easy-to-use solution for robotics manipulation, empowering everyone with the ability to fine-tune their own robotics policy.
TeachingBot: Robot Teacher for Human Handwriting
Sep 21, 2023Teaching physical skills to humans requires one-on-one interaction between the teacher and the learner. With a shortage of human teachers, such a teaching mode faces the challenge of scaling up. Robots, with their replicable nature and physical capabilities, offer a solution. In this work, we present TeachingBot, a robotic system designed for teaching handwriting to human learners. We tackle two primary challenges in this teaching task: the adaptation to each learner's unique style and the creation of an engaging learning experience. TeachingBot captures the learner's style using a probabilistic learning approach based on the learner's handwriting. Then, based on the learned style, it provides physical guidance to human learners with variable impedance to make the learning experience engaging. Results from human-subject experiments based on 15 human subjects support the effectiveness of TeachingBot, demonstrating improved human learning outcomes compared to baseline methods. Additionally, we illustrate how TeachingBot customizes its teaching approach for individual learners, leading to enhanced overall engagement and effectiveness.
What Truly Matters in Trajectory Prediction for Autonomous Driving?
Jun 27, 2023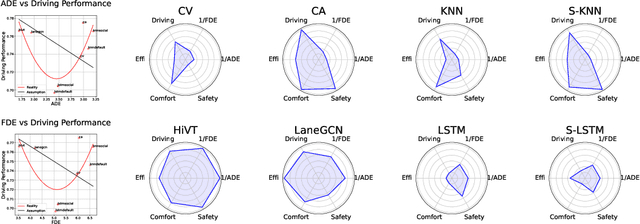



In the autonomous driving system, trajectory prediction plays a vital role in ensuring safety and facilitating smooth navigation. However, we observe a substantial discrepancy between the accuracy of predictors on fixed datasets and their driving performance when used in downstream tasks. This discrepancy arises from two overlooked factors in the current evaluation protocols of trajectory prediction: 1) the dynamics gap between the dataset and real driving scenario; and 2) the computational efficiency of predictors. In real-world scenarios, prediction algorithms influence the behavior of autonomous vehicles, which, in turn, alter the behaviors of other agents on the road. This interaction results in predictor-specific dynamics that directly impact prediction results. As other agents' responses are predetermined on datasets, a significant dynamics gap arises between evaluations conducted on fixed datasets and actual driving scenarios. Furthermore, focusing solely on accuracy fails to address the demand for computational efficiency, which is critical for the real-time response required by the autonomous driving system. Therefore, in this paper, we demonstrate that an interactive, task-driven evaluation approach for trajectory prediction is crucial to reflect its efficacy for autonomous driving.
DiffMimic: Efficient Motion Mimicking with Differentiable Physics
Apr 26, 2023
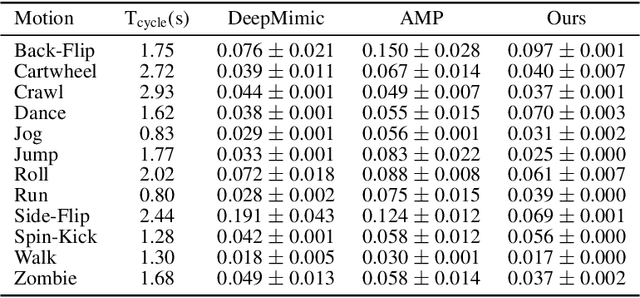
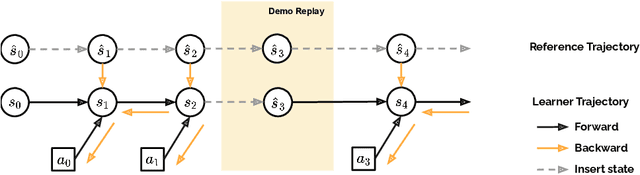
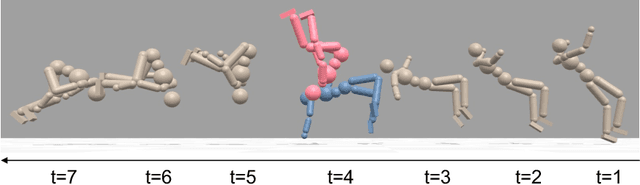
Motion mimicking is a foundational task in physics-based character animation. However, most existing motion mimicking methods are built upon reinforcement learning (RL) and suffer from heavy reward engineering, high variance, and slow convergence with hard explorations. Specifically, they usually take tens of hours or even days of training to mimic a simple motion sequence, resulting in poor scalability. In this work, we leverage differentiable physics simulators (DPS) and propose an efficient motion mimicking method dubbed DiffMimic. Our key insight is that DPS casts a complex policy learning task to a much simpler state matching problem. In particular, DPS learns a stable policy by analytical gradients with ground-truth physical priors hence leading to significantly faster and stabler convergence than RL-based methods. Moreover, to escape from local optima, we utilize a Demonstration Replay mechanism to enable stable gradient backpropagation in a long horizon. Extensive experiments on standard benchmarks show that DiffMimic has a better sample efficiency and time efficiency than existing methods (e.g., DeepMimic). Notably, DiffMimic allows a physically simulated character to learn Backflip after 10 minutes of training and be able to cycle it after 3 hours of training, while the existing approach may require about a day of training to cycle Backflip. More importantly, we hope DiffMimic can benefit more differentiable animation systems with techniques like differentiable clothes simulation in future research.