 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyes on VLM: Benchmarking Gaze Following and Social Gaze Prediction in Vision Language Models
May 19, 2026Vision-language models (VLMs) have rapidly evolved into general-purpose multimodal reasoners with strong zero-shot generalization. In this context, VLMs could greatly benefit the analysis of human gaze and attention, a central task in human behavior understanding that requires reasoning about the physical scene as well as the activity, interactions, and social context. However, the extent to which VLMs can reliably understand human gaze and related attentional behaviors remains largely unexplored. In this work, we present EyeVLM, a systematic evaluation framework for gaze understanding in VLMs across two complementary dimensions: tasks and models. To assess gaze understanding capabilities, we focus on two core tasks. The first, gaze following, i.e., predicting the 2D location where a person is looking, has a geometric and visual processing focus, requiring a precise understanding of the human face, attention direction, 3D scene structure, and spatial grounding of attended targets. The second, social gaze prediction, requires social and relational reasoning over multi-person interactions (e.g., mutual gaze and shared attention), and may benefit more from the LLM semantic reasoning capabilities within VLMs. Regarding models, EyeVLM evaluates these tasks in two ways: a zero-shot setting with a diverse set of state-of-the-art open- and closed-source VLMs, exploring different prompting strategies; and a fine-tuning approach based on task-specific QA pairs, studying the impact of model scale and data scale. As benchmarks, we rely on existing gaze understanding datasets and perform a systematic comparison with state-of-the-art purely visual models. Overall, our results show that current VLMs lack precise gaze understanding capabilities. While standard training helps reduce the gap with visual models, significant improvements are still needed.
Towards Benchmarking Foundation Models for Tabular Data With Text
Jul 10, 2025Foundation models for tabular data are rapidly evolving, with increasing interest in extending them to support additional modalities such as free-text features. However, existing benchmarks for tabular data rarely include textual columns, and identifying real-world tabular datasets with semantically rich text features is non-trivial. We propose a series of simple yet effective ablation-style strategies for incorporating text into conventional tabular pipelines. Moreover, we benchmark how state-of-the-art tabular foundation models can handle textual data by manually curating a collection of real-world tabular datasets with meaningful textual features. Our study is an important step towards improving benchmarking of foundation models for tabular data with text.
Robi Butler: Remote Multimodal Interactions with Household Robot Assistant
Sep 30, 2024In this paper, we introduce Robi Butler, a novel household robotic system that enables multimodal interactions with remote users. Building on the advanced communication interfaces, Robi Butler allows users to monitor the robot's status, send text or voice instructions, and select target objects by hand pointing. At the core of our system is a high-level behavior module, powered by Large Language Models (LLMs), that interprets multimodal instructions to generate action plans. These plans are composed of a set of open vocabulary primitives supported by Vision Language Models (VLMs) that handle both text and pointing queries. The integration of the above components allows Robi Butler to ground remote multimodal instructions in the real-world home environment in a zero-shot manner. We demonstrate the effectiveness and efficiency of this system using a variety of daily household tasks that involve remote users giving multimodal instructions. Additionally, we conducted a user study to analyze how multimodal interactions affect efficiency and user experience during remote human-robot interaction and discuss the potential improvements.
Exploring the Zero-Shot Capabilities of Vision-Language Models for Improving Gaze Following
Jun 06, 2024



Contextual cues related to a person's pose and interactions with objects and other people in the scene can provide valuable information for gaze following. While existing methods have focused on dedicated cue extraction methods, in this work we investigate the zero-shot capabilities of Vision-Language Models (VLMs) for extracting a wide array of contextual cues to improve gaze following performance. We first evaluate various VLMs, prompting strategies, and in-context learning (ICL) techniques for zero-shot cue recognition performance. We then use these insights to extract contextual cues for gaze following, and investigate their impact when incorporated into a state of the art model for the task. Our analysis indicates that BLIP-2 is the overall top performing VLM and that ICL can improve performance. We also observe that VLMs are sensitive to the choice of the text prompt although ensembling over multiple text prompts can provide more robust performance. Additionally, we discover that using the entire image along with an ellipse drawn around the target person is the most effective strategy for visual prompting. For gaze following, incorporating the extracted cues results in better generalization performance, especially when considering a larger set of cues, highlighting the potential of this approach.
A Novel Framework for Multi-Person Temporal Gaze Following and Social Gaze Prediction
Mar 15, 2024



Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed static models that can handle only one person at a time, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. The framework comprises of: (i) a temporal, transformer-based architecture that, in addition to image tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, that unifies annotation types across multiple gaze following and social gaze datasets. We show that our model trained on VSGaze can address all tasks jointly, and achieves state-of-the-art results for multi-person gaze following and social gaze prediction.
Sharingan: A Transformer-based Architecture for Gaze Following
Oct 01, 2023



Gaze is a powerful form of non-verbal communication and social interaction that humans develop from an early age. As such, modeling this behavior is an important task that can benefit a broad set of application domains ranging from robotics to sociology. In particular, Gaze Following is defined as the prediction of the pixel-wise 2D location where a person in the image is looking. Prior efforts in this direction have focused primarily on CNN-based architectures to perform the task. In this paper, we introduce a novel transformer-based architecture for 2D gaze prediction. We experiment with 2 variants: the first one retains the same task formulation of predicting a gaze heatmap for one person at a time, while the second one casts the problem as a 2D point regression and allows us to perform multi-person gaze prediction with a single forward pass. This new architecture achieves state-of-the-art results on the GazeFollow and VideoAttentionTarget datasets. The code for this paper will be made publicly available.
A Modular Multimodal Architecture for Gaze Target Prediction: Application to Privacy-Sensitive Settings
Jul 11, 2023



Predicting where a person is looking is a complex task, requiring to understand not only the person's gaze and scene content, but also the 3D scene structure and the person's situation (are they manipulating? interacting or observing others? attentive?) to detect obstructions in the line of sight or apply attention priors that humans typically have when observing others. In this paper, we hypothesize that identifying and leveraging such priors can be better achieved through the exploitation of explicitly derived multimodal cues such as depth and pose. We thus propose a modular multimodal architecture allowing to combine these cues using an attention mechanism. The architecture can naturally be exploited in privacy-sensitive situations such as surveillance and health, where personally identifiable information cannot be released. We perform extensive experiments on the GazeFollow and VideoAttentionTarget public datasets, obtaining state-of-the-art performance and demonstrating very competitive results in the privacy setting case.
ChildPlay: A New Benchmark for Understanding Children's Gaze Behaviour
Jul 04, 2023Gaze behaviors such as eye-contact or shared attention are important markers for diagnosing developmental disorders in children. While previous studies have looked at some of these elements, the analysis is usually performed on private datasets and is restricted to lab settings. Furthermore, all publicly available gaze target prediction benchmarks mostly contain instances of adults, which makes models trained on them less applicable to scenarios with young children. In this paper, we propose the first study for predicting the gaze target of children and interacting adults. To this end, we introduce the ChildPlay dataset: a curated collection of short video clips featuring children playing and interacting with adults in uncontrolled environments (e.g. kindergarten, therapy centers, preschools etc.), which we annotate with rich gaze information. We further propose a new model for gaze target prediction that is geometrically grounded by explicitly identifying the scene parts in the 3D field of view (3DFoV) of the person, leveraging recent geometry preserving depth inference methods. Our model achieves state of the art results on benchmark datasets and ChildPlay. Furthermore, results show that looking at faces prediction performance on children is much worse than on adults, and can be significantly improved by fine-tuning models using child gaze annotations. Our dataset and models will be made publicly available.
End-to-End Differentiable 6DoF Object Pose Estimation with Local and Global Constraints
Nov 22, 2020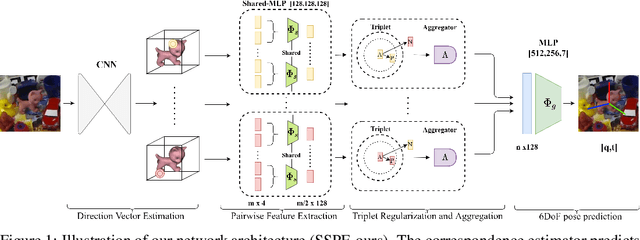
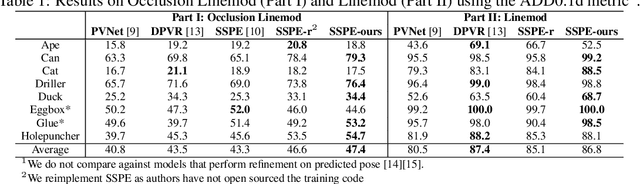

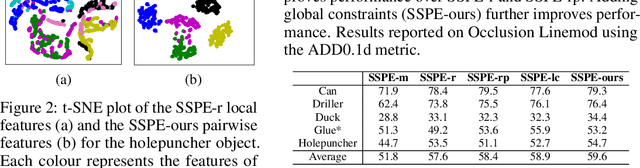
Inferring the 6DoF pose of an object from a single RGB image is an important but challenging task, especially under heavy occlusion. While recent approaches improve upon the two stage approaches by training an end-to-end pipeline, they do not leverage local and global constraints. In this paper, we propose pairwise feature extraction to integrate local constraints, and triplet regularization to integrate global constraints for improved 6DoF object pose estimation. Coupled with better augmentation, our approach achieves state of the art results on the challenging Occlusion Linemod dataset, with a 9% improvement over the previous state of the art, and achieves competitive results on the Linemod dataset.
Font Identification in Historical Documents Using Active Learning
Jan 27, 2016
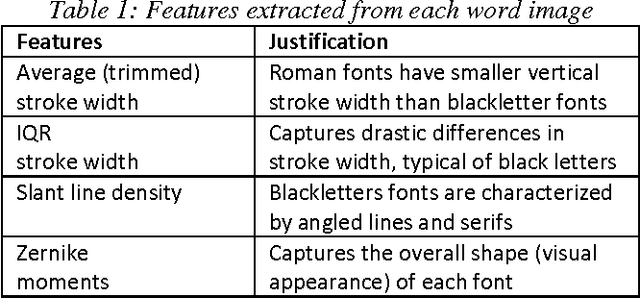
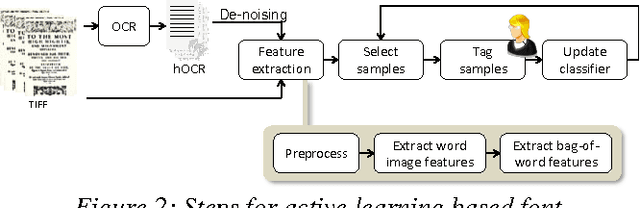

Identifying the type of font (e.g., Roman, Blackletter) used in historical documents can help optical character recognition (OCR) systems produce more accurate text transcriptions. Towards this end, we present an active-learning strategy that can significantly reduce the number of labeled samples needed to train a font classifier. Our approach extracts image-based features that exploit geometric differences between fonts at the word level, and combines them into a bag-of-word representation for each page in a document. We evaluate six sampling strategies based on uncertainty, dissimilarity and diversity criteria, and test them on a database containing over 3,000 historical documents with Blackletter, Roman and Mixed fonts. Our results show that a combination of uncertainty and diversity achieves the highest predictive accuracy (89% of test cases correctly classified) while requiring only a small fraction of the data (17%) to be labeled. We discuss the implications of this result for mass digitization projects of historical documents.