 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Gaze Estimation in the Wild using Weak Supervision with Gaze Following Labels
Feb 27, 2025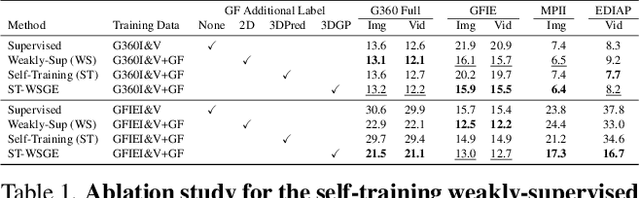
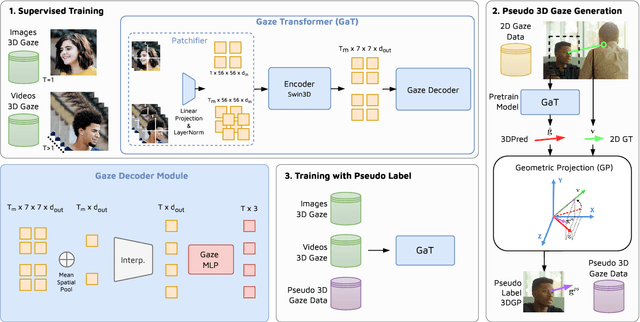
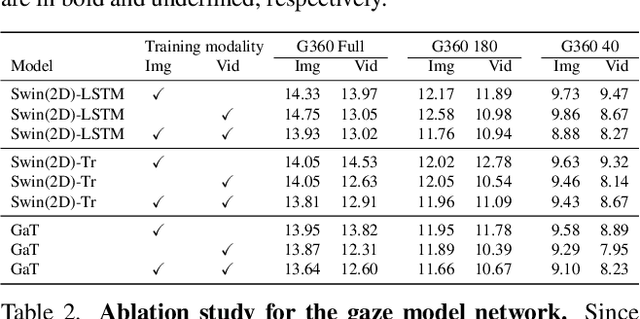
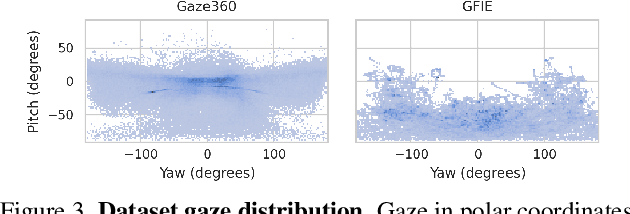
Accurate 3D gaze estimation in unconstrained real-world environments remains a significant challenge due to variations in appearance, head pose, occlusion, and the limited availability of in-the-wild 3D gaze datasets. To address these challenges, we introduce a novel Self-Training Weakly-Supervised Gaze Estimation framework (ST-WSGE). This two-stage learning framework leverages diverse 2D gaze datasets, such as gaze-following data, which offer rich variations in appearances, natural scenes, and gaze distributions, and proposes an approach to generate 3D pseudo-labels and enhance model generalization. Furthermore, traditional modality-specific models, designed separately for images or videos, limit the effective use of available training data. To overcome this, we propose the Gaze Transformer (GaT), a modality-agnostic architecture capable of simultaneously learning static and dynamic gaze information from both image and video datasets. By combining 3D video datasets with 2D gaze target labels from gaze following tasks, our approach achieves the following key contributions: (i) Significant state-of-the-art improvements in within-domain and cross-domain generalization on unconstrained benchmarks like Gaze360 and GFIE, with notable cross-modal gains in video gaze estimation; (ii) Superior cross-domain performance on datasets such as MPIIFaceGaze and Gaze360 compared to frontal face methods. Code and pre-trained models will be released to the community.
Exploring the Zero-Shot Capabilities of Vision-Language Models for Improving Gaze Following
Jun 06, 2024



Contextual cues related to a person's pose and interactions with objects and other people in the scene can provide valuable information for gaze following. While existing methods have focused on dedicated cue extraction methods, in this work we investigate the zero-shot capabilities of Vision-Language Models (VLMs) for extracting a wide array of contextual cues to improve gaze following performance. We first evaluate various VLMs, prompting strategies, and in-context learning (ICL) techniques for zero-shot cue recognition performance. We then use these insights to extract contextual cues for gaze following, and investigate their impact when incorporated into a state of the art model for the task. Our analysis indicates that BLIP-2 is the overall top performing VLM and that ICL can improve performance. We also observe that VLMs are sensitive to the choice of the text prompt although ensembling over multiple text prompts can provide more robust performance. Additionally, we discover that using the entire image along with an ellipse drawn around the target person is the most effective strategy for visual prompting. For gaze following, incorporating the extracted cues results in better generalization performance, especially when considering a larger set of cues, highlighting the potential of this approach.
A Novel Framework for Multi-Person Temporal Gaze Following and Social Gaze Prediction
Mar 15, 2024



Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed static models that can handle only one person at a time, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. The framework comprises of: (i) a temporal, transformer-based architecture that, in addition to image tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, that unifies annotation types across multiple gaze following and social gaze datasets. We show that our model trained on VSGaze can address all tasks jointly, and achieves state-of-the-art results for multi-person gaze following and social gaze prediction.