 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Shared Attention Estimation via Group Detection with Feedback Refinement
Apr 02, 2026This paper proposes an end-to-end shared attention estimation method via group detection. Most previous methods estimate shared attention (SA) without detecting the actual group of people focusing on it, or assume that there is a single SA point in a given image. These issues limit the applicability of SA detection in practice and impact performance. To address them, we propose to simultaneously achieve group detection and shared attention estimation using a two step process: (i) the generation of SA heatmaps relying on individual gaze attention heatmaps and group membership scalars estimated in a group inference; (ii) a refinement of the initial group memberships allowing to account for the initial SA heatmaps, and the final prediction of the SA heatmap. Experiments demonstrate that our method outperforms other methods in group detection and shared attention estimation. Additional analyses validate the effectiveness of the proposed components. Code: https://github.com/chihina/sagd-CVPRW2026.
Enhancing 3D Gaze Estimation in the Wild using Weak Supervision with Gaze Following Labels
Feb 27, 2025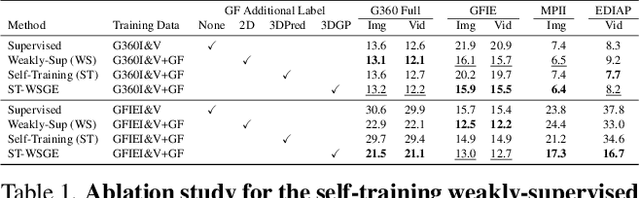
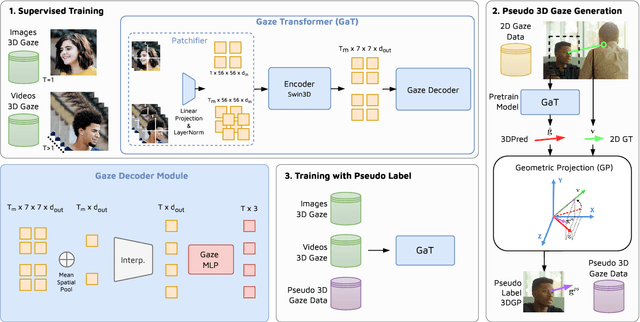
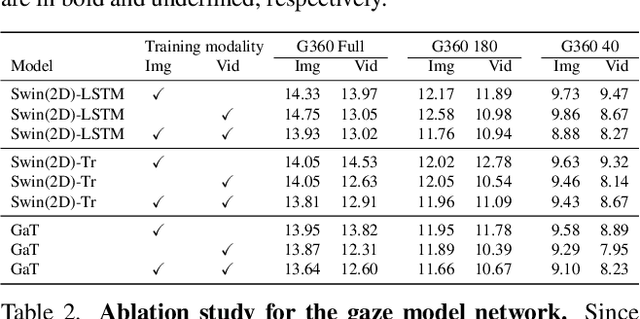
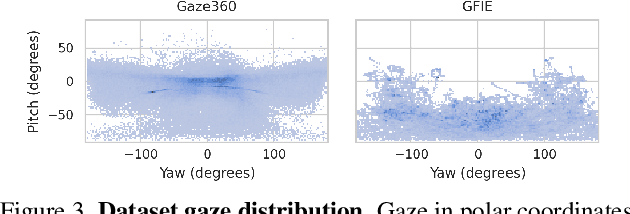
Accurate 3D gaze estimation in unconstrained real-world environments remains a significant challenge due to variations in appearance, head pose, occlusion, and the limited availability of in-the-wild 3D gaze datasets. To address these challenges, we introduce a novel Self-Training Weakly-Supervised Gaze Estimation framework (ST-WSGE). This two-stage learning framework leverages diverse 2D gaze datasets, such as gaze-following data, which offer rich variations in appearances, natural scenes, and gaze distributions, and proposes an approach to generate 3D pseudo-labels and enhance model generalization. Furthermore, traditional modality-specific models, designed separately for images or videos, limit the effective use of available training data. To overcome this, we propose the Gaze Transformer (GaT), a modality-agnostic architecture capable of simultaneously learning static and dynamic gaze information from both image and video datasets. By combining 3D video datasets with 2D gaze target labels from gaze following tasks, our approach achieves the following key contributions: (i) Significant state-of-the-art improvements in within-domain and cross-domain generalization on unconstrained benchmarks like Gaze360 and GFIE, with notable cross-modal gains in video gaze estimation; (ii) Superior cross-domain performance on datasets such as MPIIFaceGaze and Gaze360 compared to frontal face methods. Code and pre-trained models will be released to the community.
Giving Sense to Inputs: Toward an Accessible Control Framework for Shared Autonomy
Jan 28, 2025While shared autonomy offers significant potential for assistive robotics, key questions remain about how to effectively map 2D control inputs to 6D robot motions. An intuitive framework should allow users to input commands effortlessly, with the robot responding as expected, without users needing to anticipate the impact of their inputs. In this article, we propose a dynamic input mapping framework that links joystick movements to motions on control frames defined along a trajectory encoded with canal surfaces. We evaluate our method in a user study with 20 participants, demonstrating that our input mapping framework reduces the workload and improves usability compared to a baseline mapping with similar motion encoding. To prepare for deployment in assistive scenarios, we built on the development from the accessible gaming community to select an accessible control interface. We then tested the system in an exploratory study, where three wheelchair users controlled the robot for both daily living activities and a creative painting task, demonstrating its feasibility for users closer to our target population.
Loose Social-Interaction Recognition in Real-world Therapy Scenarios
Sep 30, 2024



The computer vision community has explored dyadic interactions for atomic actions such as pushing, carrying-object, etc. However, with the advancement in deep learning models, there is a need to explore more complex dyadic situations such as loose interactions. These are interactions where two people perform certain atomic activities to complete a global action irrespective of temporal synchronisation and physical engagement, like cooking-together for example. Analysing these types of dyadic-interactions has several useful applications in the medical domain for social-skills development and mental health diagnosis. To achieve this, we propose a novel dual-path architecture to capture the loose interaction between two individuals. Our model learns global abstract features from each stream via a CNNs backbone and fuses them using a new Global-Layer-Attention module based on a cross-attention strategy. We evaluate our model on real-world autism diagnoses such as our Loose-Interaction dataset, and the publicly available Autism dataset for loose interactions. Our network achieves baseline results on the Loose-Interaction and SOTA results on the Autism datasets. Moreover, we study different social interactions by experimenting on a publicly available dataset i.e. NTU-RGB+D (interactive classes from both NTU-60 and NTU-120). We have found that different interactions require different network designs. We also compare a slightly different version of our method by incorporating time information to address tight interactions achieving SOTA results.
ChildPlay-Hand: A Dataset of Hand Manipulations in the Wild
Sep 14, 2024



Hand-Object Interaction (HOI) is gaining significant attention, particularly with the creation of numerous egocentric datasets driven by AR/VR applications. However, third-person view HOI has received less attention, especially in terms of datasets. Most third-person view datasets are curated for action recognition tasks and feature pre-segmented clips of high-level daily activities, leaving a gap for in-the-wild datasets. To address this gap, we propose ChildPlay-Hand, a novel dataset that includes person and object bounding boxes, as well as manipulation actions. ChildPlay-Hand is unique in: (1) providing per-hand annotations; (2) featuring videos in uncontrolled settings with natural interactions, involving both adults and children; (3) including gaze labels from the ChildPlay-Gaze dataset for joint modeling of manipulations and gaze. The manipulation actions cover the main stages of an HOI cycle, such as grasping, holding or operating, and different types of releasing. To illustrate the interest of the dataset, we study two tasks: object in hand detection (OiH), i.e. if a person has an object in their hand, and manipulation stages (ManiS), which is more fine-grained and targets the main stages of manipulation. We benchmark various spatio-temporal and segmentation networks, exploring body vs. hand-region information and comparing pose and RGB modalities. Our findings suggest that ChildPlay-Hand is a challenging new benchmark for modeling HOI in the wild.
Weakly-supervised Autism Severity Assessment in Long Videos
Jul 12, 2024Autism Spectrum Disorder (ASD) is a diverse collection of neurobiological conditions marked by challenges in social communication and reciprocal interactions, as well as repetitive and stereotypical behaviors. Atypical behavior patterns in a long, untrimmed video can serve as biomarkers for children with ASD. In this paper, we propose a video-based weakly-supervised method that takes spatio-temporal features of long videos to learn typical and atypical behaviors for autism detection. On top of that, we propose a shallow TCN-MLP network, which is designed to further categorize the severity score. We evaluate our method on actual evaluation videos of children with autism collected and annotated (for severity score) by clinical professionals. Experimental results demonstrate the effectiveness of behavioral biomarkers that could help clinicians in autism spectrum analysis.
Exploring the Zero-Shot Capabilities of Vision-Language Models for Improving Gaze Following
Jun 06, 2024



Contextual cues related to a person's pose and interactions with objects and other people in the scene can provide valuable information for gaze following. While existing methods have focused on dedicated cue extraction methods, in this work we investigate the zero-shot capabilities of Vision-Language Models (VLMs) for extracting a wide array of contextual cues to improve gaze following performance. We first evaluate various VLMs, prompting strategies, and in-context learning (ICL) techniques for zero-shot cue recognition performance. We then use these insights to extract contextual cues for gaze following, and investigate their impact when incorporated into a state of the art model for the task. Our analysis indicates that BLIP-2 is the overall top performing VLM and that ICL can improve performance. We also observe that VLMs are sensitive to the choice of the text prompt although ensembling over multiple text prompts can provide more robust performance. Additionally, we discover that using the entire image along with an ellipse drawn around the target person is the most effective strategy for visual prompting. For gaze following, incorporating the extracted cues results in better generalization performance, especially when considering a larger set of cues, highlighting the potential of this approach.
GeoSACS: Geometric Shared Autonomy via Canal Surfaces
Apr 15, 2024We introduce GeoSACS, a geometric framework for shared autonomy (SA). In variable environments, SA methods can be used to combine robotic capabilities with real-time human input in a way that offloads the physical task from the human. To remain intuitive, it can be helpful to simplify requirements for human input (i.e., reduce the dimensionality), which create challenges for to map low-dimensional human inputs to the higher dimensional control space of robots without requiring large amounts of data. We built GeoSACS on canal surfaces, a geometric framework that represents potential robot trajectories as a canal from as few as two demonstrations. GeoSACS maps user corrections on the cross-sections of this canal to provide an efficient SA framework. We extend canal surfaces to consider orientation and update the control frames to support intuitive mapping from user input to robot motions. Finally, we demonstrate GeoSACS in two preliminary studies, including a complex manipulation task where a robot loads laundry into a washer.
A Novel Framework for Multi-Person Temporal Gaze Following and Social Gaze Prediction
Mar 15, 2024



Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed static models that can handle only one person at a time, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. The framework comprises of: (i) a temporal, transformer-based architecture that, in addition to image tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, that unifies annotation types across multiple gaze following and social gaze datasets. We show that our model trained on VSGaze can address all tasks jointly, and achieves state-of-the-art results for multi-person gaze following and social gaze prediction.
Sharingan: A Transformer-based Architecture for Gaze Following
Oct 01, 2023



Gaze is a powerful form of non-verbal communication and social interaction that humans develop from an early age. As such, modeling this behavior is an important task that can benefit a broad set of application domains ranging from robotics to sociology. In particular, Gaze Following is defined as the prediction of the pixel-wise 2D location where a person in the image is looking. Prior efforts in this direction have focused primarily on CNN-based architectures to perform the task. In this paper, we introduce a novel transformer-based architecture for 2D gaze prediction. We experiment with 2 variants: the first one retains the same task formulation of predicting a gaze heatmap for one person at a time, while the second one casts the problem as a 2D point regression and allows us to perform multi-person gaze prediction with a single forward pass. This new architecture achieves state-of-the-art results on the GazeFollow and VideoAttentionTarget datasets. The code for this paper will be made publicly available.