 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaining Explainability from a CNN for Stereotype Detection Based on Mice Stopping Behavior
Dec 06, 2024Understanding the behavior of laboratory animals is a key to find answers about diseases and neurodevelopmental disorders that also affects humans. One behavior of interest is the stopping, as it correlates with exploration, feeding and sleeping habits of individuals. To improve comprehension of animal's behavior, we focus on identifying trait revealing age/sex of mice through the series of stopping spots of each individual. We track 4 mice using LiveMouseTracker (LMT) system during 3 days. Then, we build a stack of 2D histograms of the stop positions. This stack of histograms passes through a shallow CNN architecture to classify mice in terms of age and sex. We observe that female mice show more recognizable behavioral patterns, reaching a classification accuracy of more than 90%, while males, which do not present as many distinguishable patterns, reach an accuracy of 62.5%. To gain explainability from the model, we look at the activation function of the convolutional layers and found that some regions of the cage are preferentially explored by females. Males, especially juveniles, present behavior patterns that oscillate between juvenile female and adult male.
Weakly-supervised Autism Severity Assessment in Long Videos
Jul 12, 2024Autism Spectrum Disorder (ASD) is a diverse collection of neurobiological conditions marked by challenges in social communication and reciprocal interactions, as well as repetitive and stereotypical behaviors. Atypical behavior patterns in a long, untrimmed video can serve as biomarkers for children with ASD. In this paper, we propose a video-based weakly-supervised method that takes spatio-temporal features of long videos to learn typical and atypical behaviors for autism detection. On top of that, we propose a shallow TCN-MLP network, which is designed to further categorize the severity score. We evaluate our method on actual evaluation videos of children with autism collected and annotated (for severity score) by clinical professionals. Experimental results demonstrate the effectiveness of behavioral biomarkers that could help clinicians in autism spectrum analysis.
MUAD: Multiple Uncertainties for Autonomous Driving benchmark for multiple uncertainty types and tasks
Mar 02, 2022
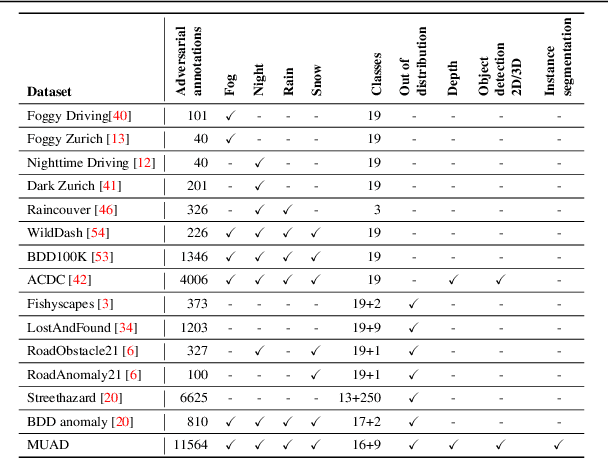
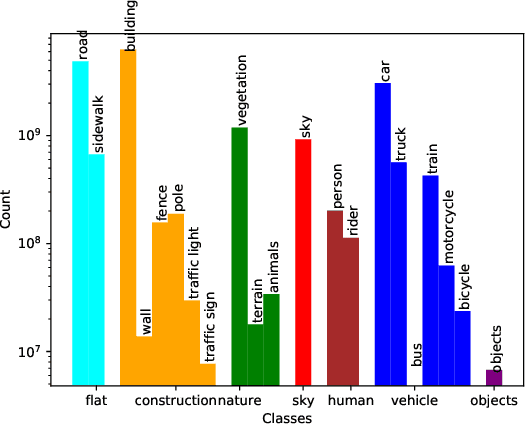
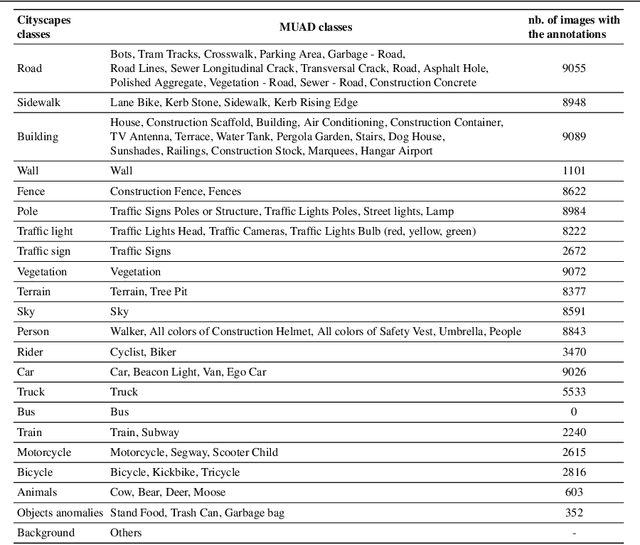
Predictive uncertainty estimation is essential for deploying Deep Neural Networks in real-world autonomous systems. However, disentangling the different types and sources of uncertainty is non trivial in most datasets, especially since there is no ground truth for uncertainty. In addition, different degrees of weather conditions can disrupt neural networks, resulting in inconsistent training data quality. Thus, we introduce the MUAD dataset (Multiple Uncertainties for Autonomous Driving), consisting of 8,500 realistic synthetic images with diverse adverse weather conditions (night, fog, rain, snow), out-of-distribution objects and annotations for semantic segmentation, depth estimation, object and instance detection. MUAD allows to better assess the impact of different sources of uncertainty on model performance. We propose a study that shows the importance of having reliable Deep Neural Networks (DNNs) in multiple experiments, and will release our dataset to allow researchers to benchmark their algorithm methodically in ad-verse conditions. More information and the download link for MUAD are available at https://muad-dataset.github.io/ .
Face Alignment with Cascaded Semi-Parametric Deep Greedy Neural Forests
Mar 05, 2017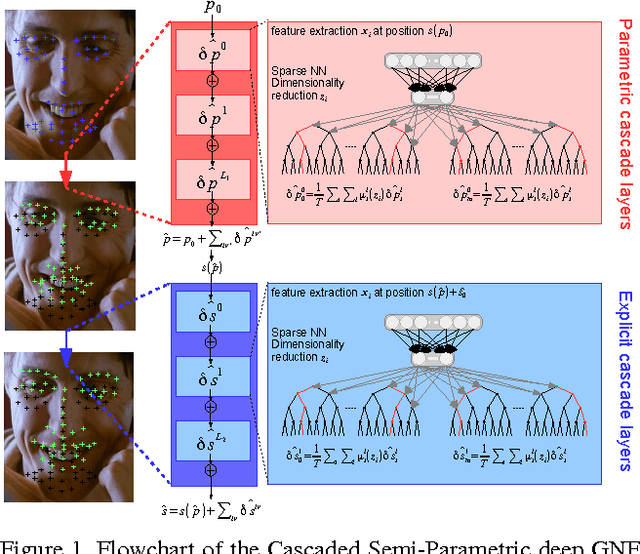
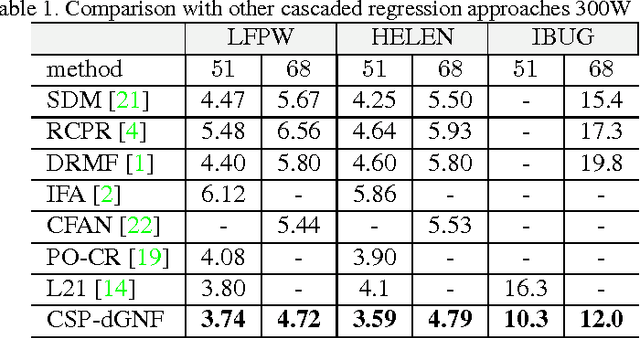
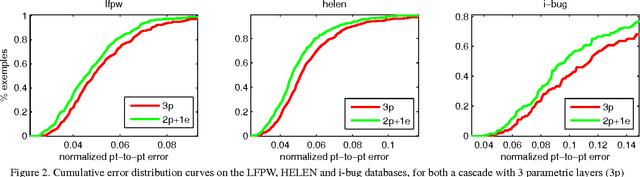
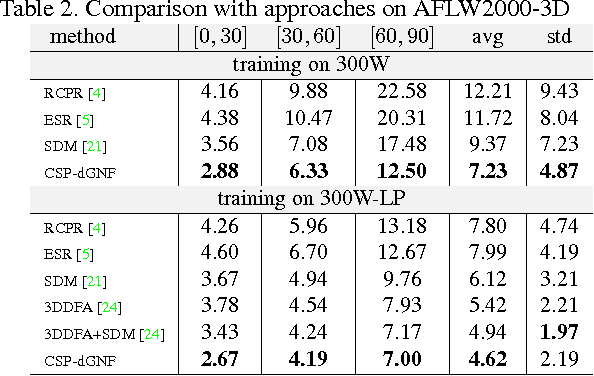
Face alignment is an active topic in computer vision, consisting in aligning a shape model on the face. To this end, most modern approaches refine the shape in a cascaded manner, starting from an initial guess. Those shape updates can either be applied in the feature point space (\textit{i.e.} explicit updates) or in a low-dimensional, parametric space. In this paper, we propose a semi-parametric cascade that first aligns a parametric shape, then captures more fine-grained deformations of an explicit shape. For the purpose of learning shape updates at each cascade stage, we introduce a deep greedy neural forest (GNF) model, which is an improved version of deep neural forest (NF). GNF appears as an ideal regressor for face alignment, as it combines differentiability, high expressivity and fast evaluation runtime. The proposed framework is very fast and achieves high accuracies on multiple challenging benchmarks, including small, medium and large pose experiments.
Confidence-Weighted Local Expression Predictions for Occlusion Handling in Expression Recognition and Action Unit detection
Jul 21, 2016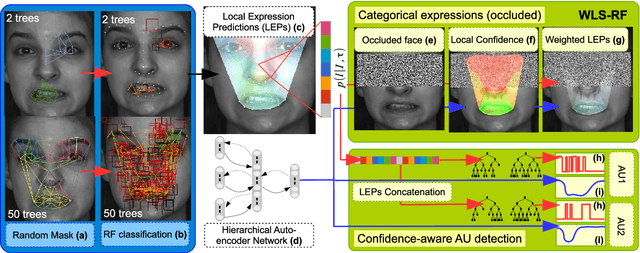
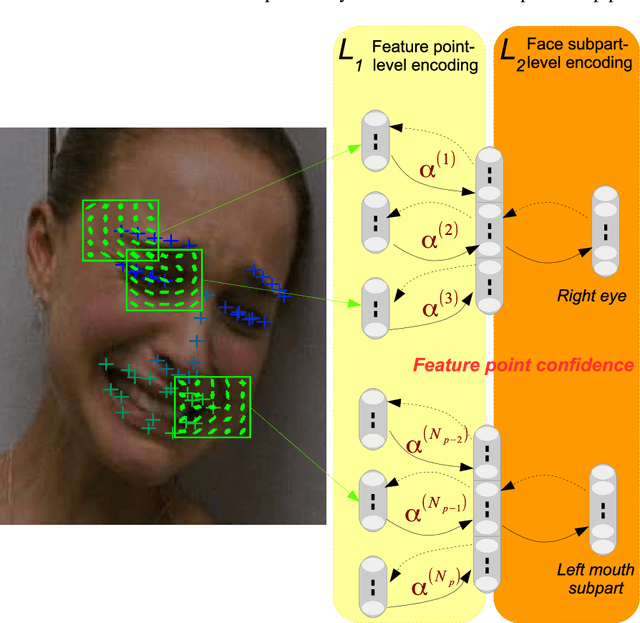
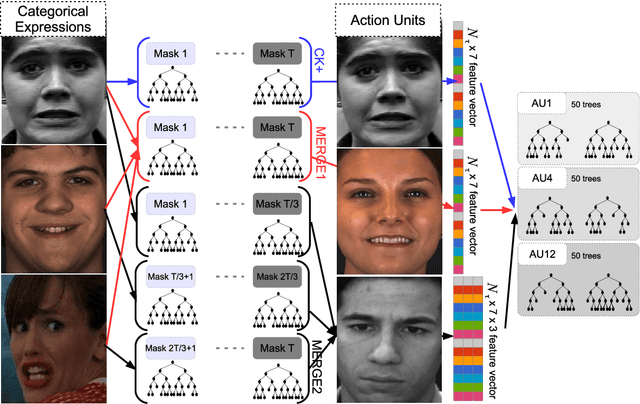

Fully-Automatic Facial Expression Recognition (FER) from still images is a challenging task as it involves handling large interpersonal morphological differences, and as partial occlusions can occasionally happen. Furthermore, labelling expressions is a time-consuming process that is prone to subjectivity, thus the variability may not be fully covered by the training data. In this work, we propose to train Random Forests upon spatially defined local subspaces of the face. The output local predictions form a categorical expression-driven high-level representation that we call Local Expression Predictions (LEPs). LEPs can be combined to describe categorical facial expressions as well as Action Units (AUs). Furthermore, LEPs can be weighted by confidence scores provided by an autoencoder network. Such network is trained to locally capture the manifold of the non-occluded training data in a hierarchical way. Extensive experiments show that the proposed LEP representation yields high descriptive power for categorical expressions and AU occurrence prediction, and leads to interesting perspectives towards the design of occlusion-robust and confidence-aware FER systems.
Dynamic Pose-Robust Facial Expression Recognition by Multi-View Pairwise Conditional Random Forests
Jul 21, 2016
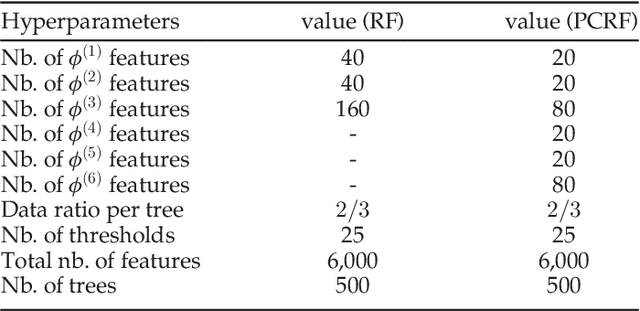
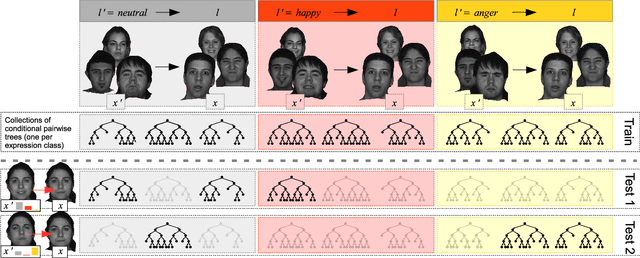
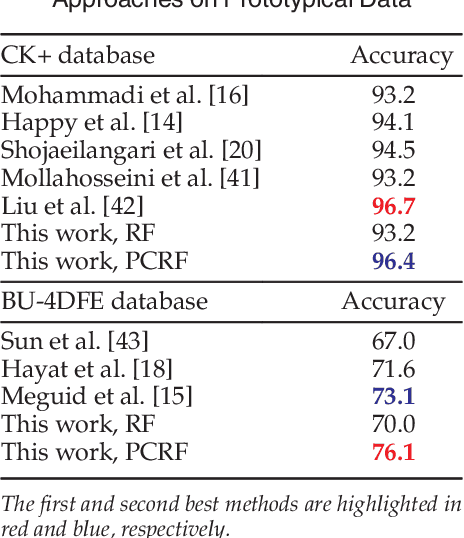
Automatic facial expression classification (FER) from videos is a critical problem for the development of intelligent human-computer interaction systems. Still, it is a challenging problem that involves capturing high-dimensional spatio-temporal patterns describing the variation of one's appearance over time. Such representation undergoes great variability of the facial morphology and environmental factors as well as head pose variations. In this paper, we use Conditional Random Forests to capture low-level expression transition patterns. More specifically, heterogeneous derivative features (e.g. feature point movements or texture variations) are evaluated upon pairs of images. When testing on a video frame, pairs are created between this current frame and previous ones and predictions for each previous frame are used to draw trees from Pairwise Conditional Random Forests (PCRF) whose pairwise outputs are averaged over time to produce robust estimates. Moreover, PCRF collections can also be conditioned on head pose estimation for multi-view dynamic FER. As such, our approach appears as a natural extension of Random Forests for learning spatio-temporal patterns, potentially from multiple viewpoints. Experiments on popular datasets show that our method leads to significant improvements over standard Random Forests as well as state-of-the-art approaches on several scenarios, including a novel multi-view video corpus generated from a publicly available database.