 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALON: Token-Aligned Lightweight Adapters for 6-DoF Spacecraft Pose Estimation
May 29, 2026Monocular 6-DoF spacecraft pose estimation methods predominantly process individual frames, discarding the temporal information present in an image sequence acquired during spacecraft manoeuvres. Few temporal approaches require full backbone fine-tuning or auxiliary optical flow networks, risking catastrophic forgetting or increasing computational cost, respectively. We propose TALON (Token-Aligned Lightweight adapters for Orbital Navigation): spatiotemporal 3D adapters injected before the self-attention layers of a frozen ViT vision transformer, combined with a patch-token alignment loss that geometrically grounds the adapted features to keypoint structure through a prototype-conditioned KL-divergence objective. Pre-attention placement allows the frozen attention to reason over temporally enriched tokens, achieving stronger performance with a single adapter per block than post-attention alternatives. The alignment loss shapes the intermediate representations so that each keypoint induces a spatially precise activation in the token field, while the framework adds less than 5% parameters to the frozen backbone. On SPADES dataset, TALON reduces the pose error by 50% over the prior state-of-the-art, and on SwissCube dataset it surpasses the prior best by 21.8% in ADD-0.1d accuracy. Zero-shot cross-domain evaluation from sim-to-real on SPARK real data reduces pose error by 4.7x, and ablations characterise the role of adapter depth across in-domain and cross-domain settings.
Towards Visually Grounded Multimodal Summarization via Cross-Modal Transformer and Gated Attention
May 12, 2026Multimodal summarization requires models to jointly understand textual and visual inputs to generate concise, semantically coherent summaries. Existing methods often inject shallow visual features into deep language models, leading to representational mismatches and weak cross-modal grounding. We propose a unified framework that jointly performs text summarization and representative image selection. Our system, SPeCTrA-Sum (Sampler Perceiver with Cross-modal Transformer and gated Attention for Summarization), introduces two key innovations. First, a Deep Visual Processor (DVP) aligns the visual encoder with the language model at corresponding depths, enabling hierarchical, layer-wise fusion that preserves semantic consistency. Second, a lightweight Visual Relevance Predictor (VRP) selects salient and diverse images by distilling soft labels from a Determinantal Point Processes (DPP) teacher. SPeCTrA-Sum is trained using a multi-objective loss that combines autoregressive summarization, cross-modal alignment, and DPP-based distillation. Experiments show that our system produces more accurate, visually grounded summaries and selects more representative images, demonstrating the benefits of depth-aware fusion and principled image selection for multimodal summarization.
Measuring What Matters Beyond Text: Evaluating Multimodal Summaries by Quality, Alignment, and Diversity
May 12, 2026Multimodal Large Language Models (MLLMs) have facilitated Multimodal Summarization with Multimodal Output (MSMO), wherein systems generate concise textual summaries accompanied by salient visuals from multimodal sources. However, current MSMO evaluation remains fragmented: text quality, image-text alignment, and visual diversity are typically assessed in isolation using unimodal metrics, making it difficult to capture whether the modalities jointly support a faithful and useful summary. To address this gap, we introduce MM-Eval, a unified evaluation framework that integrates assessments of textual quality, cross-modal alignment, and visual diversity. MM-Eval comprises three components: (1) text quality, measured using OpenFActScore for factual consistency and G-Eval for coherence, fluency, and relevance; (2) image-text relevance, evaluated via an MLLM-as-a-judge approach; and (3) image-set diversity, quantified using Truncated CLIP Entropy. We calibrate MM-Eval through a learned aggregation model trained on the mLLM-EVAL news benchmark, aligning component contributions with human preferences. Our analysis reveals a text-dominant hierarchy in this setting, where factual consistency acts as a critical determinant of perceived overall quality, while visual relevance and diversity provide complementary signals. MM-Eval improves over heuristic aggregation baselines and provides an interpretable, reference-weak framework for comparative evaluation of multimodal summaries.
AM Flow: Adapters for Temporal Processing in Action Recognition
Nov 04, 2024



Deep learning models, in particular \textit{image} models, have recently gained generalisability and robustness. %are becoming more general and robust by the day. In this work, we propose to exploit such advances in the realm of \textit{video} classification. Video foundation models suffer from the requirement of extensive pretraining and a large training time. Towards mitigating such limitations, we propose "\textit{Attention Map (AM) Flow}" for image models, a method for identifying pixels relevant to motion in each input video frame. In this context, we propose two methods to compute AM flow, depending on camera motion. AM flow allows the separation of spatial and temporal processing, while providing improved results over combined spatio-temporal processing (as in video models). Adapters, one of the popular techniques in parameter efficient transfer learning, facilitate the incorporation of AM flow into pretrained image models, mitigating the need for full-finetuning. We extend adapters to "\textit{temporal processing adapters}" by incorporating a temporal processing unit into the adapters. Our work achieves faster convergence, therefore reducing the number of epochs needed for training. Moreover, we endow an image model with the ability to achieve state-of-the-art results on popular action recognition datasets. This reduces training time and simplifies pretraining. We present experiments on Kinetics-400, Something-Something v2, and Toyota Smarthome datasets, showcasing state-of-the-art or comparable results.
Loose Social-Interaction Recognition in Real-world Therapy Scenarios
Sep 30, 2024



The computer vision community has explored dyadic interactions for atomic actions such as pushing, carrying-object, etc. However, with the advancement in deep learning models, there is a need to explore more complex dyadic situations such as loose interactions. These are interactions where two people perform certain atomic activities to complete a global action irrespective of temporal synchronisation and physical engagement, like cooking-together for example. Analysing these types of dyadic-interactions has several useful applications in the medical domain for social-skills development and mental health diagnosis. To achieve this, we propose a novel dual-path architecture to capture the loose interaction between two individuals. Our model learns global abstract features from each stream via a CNNs backbone and fuses them using a new Global-Layer-Attention module based on a cross-attention strategy. We evaluate our model on real-world autism diagnoses such as our Loose-Interaction dataset, and the publicly available Autism dataset for loose interactions. Our network achieves baseline results on the Loose-Interaction and SOTA results on the Autism datasets. Moreover, we study different social interactions by experimenting on a publicly available dataset i.e. NTU-RGB+D (interactive classes from both NTU-60 and NTU-120). We have found that different interactions require different network designs. We also compare a slightly different version of our method by incorporating time information to address tight interactions achieving SOTA results.
Weakly-supervised Autism Severity Assessment in Long Videos
Jul 12, 2024Autism Spectrum Disorder (ASD) is a diverse collection of neurobiological conditions marked by challenges in social communication and reciprocal interactions, as well as repetitive and stereotypical behaviors. Atypical behavior patterns in a long, untrimmed video can serve as biomarkers for children with ASD. In this paper, we propose a video-based weakly-supervised method that takes spatio-temporal features of long videos to learn typical and atypical behaviors for autism detection. On top of that, we propose a shallow TCN-MLP network, which is designed to further categorize the severity score. We evaluate our method on actual evaluation videos of children with autism collected and annotated (for severity score) by clinical professionals. Experimental results demonstrate the effectiveness of behavioral biomarkers that could help clinicians in autism spectrum analysis.
P-Age: Pexels Dataset for Robust Spatio-Temporal Apparent Age Classification
Nov 04, 2023



Age estimation is a challenging task that has numerous applications. In this paper, we propose a new direction for age classification that utilizes a video-based model to address challenges such as occlusions, low-resolution, and lighting conditions. To address these challenges, we propose AgeFormer which utilizes spatio-temporal information on the dynamics of the entire body dominating face-based methods for age classification. Our novel two-stream architecture uses TimeSformer and EfficientNet as backbones, to effectively capture both facial and body dynamics information for efficient and accurate age estimation in videos. Furthermore, to fill the gap in predicting age in real-world situations from videos, we construct a video dataset called Pexels Age (P-Age) for age classification. The proposed method achieves superior results compared to existing face-based age estimation methods and is evaluated in situations where the face is highly occluded, blurred, or masked. The method is also cross-tested on a variety of challenging video datasets such as Charades, Smarthome, and Thumos-14.
JOADAA: joint online action detection and action anticipation
Sep 12, 2023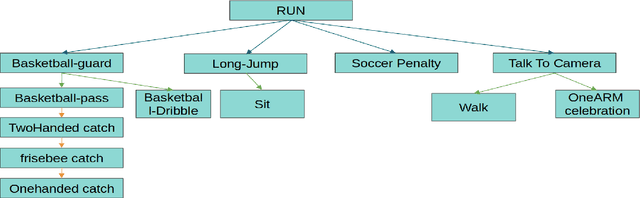
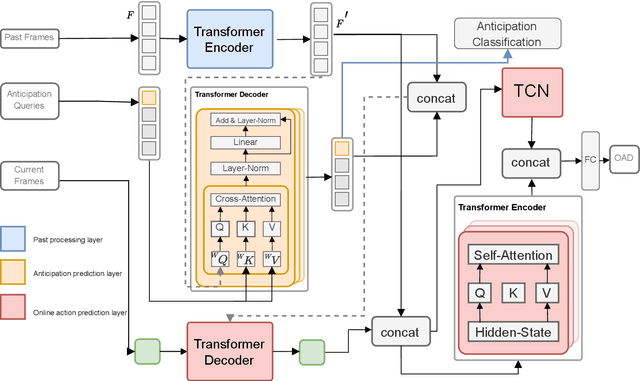
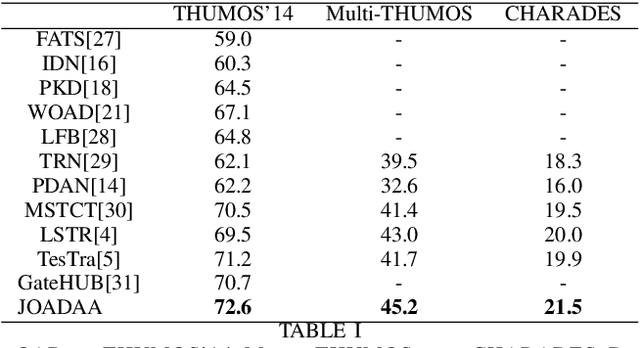
Action anticipation involves forecasting future actions by connecting past events to future ones. However, this reasoning ignores the real-life hierarchy of events which is considered to be composed of three main parts: past, present, and future. We argue that considering these three main parts and their dependencies could improve performance. On the other hand, online action detection is the task of predicting actions in a streaming manner. In this case, one has access only to the past and present information. Therefore, in online action detection (OAD) the existing approaches miss semantics or future information which limits their performance. To sum up, for both of these tasks, the complete set of knowledge (past-present-future) is missing, which makes it challenging to infer action dependencies, therefore having low performances. To address this limitation, we propose to fuse both tasks into a single uniform architecture. By combining action anticipation and online action detection, our approach can cover the missing dependencies of future information in online action detection. This method referred to as JOADAA, presents a uniform model that jointly performs action anticipation and online action detection. We validate our proposed model on three challenging datasets: THUMOS'14, which is a sparsely annotated dataset with one action per time step, CHARADES, and Multi-THUMOS, two densely annotated datasets with more complex scenarios. JOADAA achieves SOTA results on these benchmarks for both tasks.
Intelligent 3D Network Protocol for Multimedia Data Classification using Deep Learning
Jul 23, 2022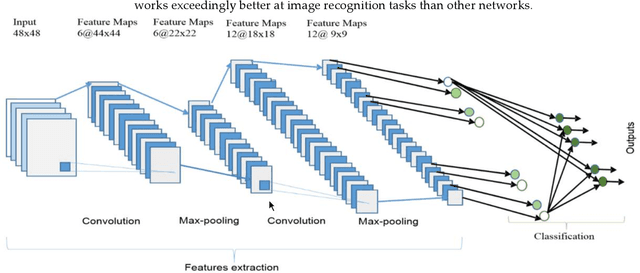


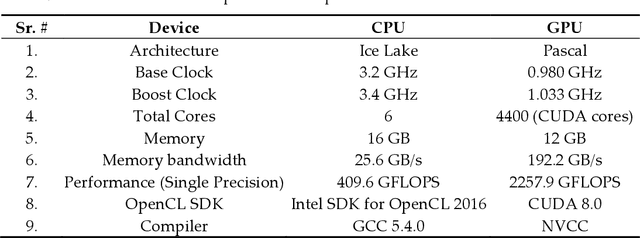
In videos, the human's actions are of three-dimensional (3D) signals. These videos investigate the spatiotemporal knowledge of human behavior. The promising ability is investigated using 3D convolution neural networks (CNNs). The 3D CNNs have not yet achieved high output for their well-established two-dimensional (2D) equivalents in still photographs. Board 3D Convolutional Memory and Spatiotemporal fusion face training difficulty preventing 3D CNN from accomplishing remarkable evaluation. In this paper, we implement Hybrid Deep Learning Architecture that combines STIP and 3D CNN features to enhance the performance of 3D videos effectively. After implementation, the more detailed and deeper charting for training in each circle of space-time fusion. The training model further enhances the results after handling complicated evaluations of models. The video classification model is used in this implemented model. Intelligent 3D Network Protocol for Multimedia Data Classification using Deep Learning is introduced to further understand spacetime association in human endeavors. In the implementation of the result, the well-known dataset, i.e., UCF101 to, evaluates the performance of the proposed hybrid technique. The results beat the proposed hybrid technique that substantially beats the initial 3D CNNs. The results are compared with state-of-the-art frameworks from literature for action recognition on UCF101 with an accuracy of 95%.