 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent 3D Network Protocol for Multimedia Data Classification using Deep Learning
Jul 23, 2022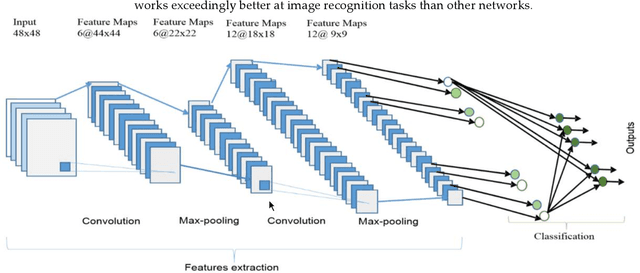


In videos, the human's actions are of three-dimensional (3D) signals. These videos investigate the spatiotemporal knowledge of human behavior. The promising ability is investigated using 3D convolution neural networks (CNNs). The 3D CNNs have not yet achieved high output for their well-established two-dimensional (2D) equivalents in still photographs. Board 3D Convolutional Memory and Spatiotemporal fusion face training difficulty preventing 3D CNN from accomplishing remarkable evaluation. In this paper, we implement Hybrid Deep Learning Architecture that combines STIP and 3D CNN features to enhance the performance of 3D videos effectively. After implementation, the more detailed and deeper charting for training in each circle of space-time fusion. The training model further enhances the results after handling complicated evaluations of models. The video classification model is used in this implemented model. Intelligent 3D Network Protocol for Multimedia Data Classification using Deep Learning is introduced to further understand spacetime association in human endeavors. In the implementation of the result, the well-known dataset, i.e., UCF101 to, evaluates the performance of the proposed hybrid technique. The results beat the proposed hybrid technique that substantially beats the initial 3D CNNs. The results are compared with state-of-the-art frameworks from literature for action recognition on UCF101 with an accuracy of 95%.