 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities
Dec 18, 2024



Geospatial models must adapt to the diversity of Earth observation data in terms of resolutions, scales, and modalities. However, existing approaches expect fixed input configurations, which limits their practical applicability. We propose AnySat, a multimodal model based on joint embedding predictive architecture (JEPA) and resolution-adaptive spatial encoders, allowing us to train a single model on highly heterogeneous data in a self-supervised manner. To demonstrate the advantages of this unified approach, we compile GeoPlex, a collection of $5$ multimodal datasets with varying characteristics and $11$ distinct sensors. We then train a single powerful model on these diverse datasets simultaneously. Once fine-tuned, we achieve better or near state-of-the-art results on the datasets of GeoPlex and $4$ additional ones for $5$ environment monitoring tasks: land cover mapping, tree species identification, crop type classification, change detection, and flood segmentation. The code and models are available at https://github.com/gastruc/AnySat.
Loose Social-Interaction Recognition in Real-world Therapy Scenarios
Sep 30, 2024



The computer vision community has explored dyadic interactions for atomic actions such as pushing, carrying-object, etc. However, with the advancement in deep learning models, there is a need to explore more complex dyadic situations such as loose interactions. These are interactions where two people perform certain atomic activities to complete a global action irrespective of temporal synchronisation and physical engagement, like cooking-together for example. Analysing these types of dyadic-interactions has several useful applications in the medical domain for social-skills development and mental health diagnosis. To achieve this, we propose a novel dual-path architecture to capture the loose interaction between two individuals. Our model learns global abstract features from each stream via a CNNs backbone and fuses them using a new Global-Layer-Attention module based on a cross-attention strategy. We evaluate our model on real-world autism diagnoses such as our Loose-Interaction dataset, and the publicly available Autism dataset for loose interactions. Our network achieves baseline results on the Loose-Interaction and SOTA results on the Autism datasets. Moreover, we study different social interactions by experimenting on a publicly available dataset i.e. NTU-RGB+D (interactive classes from both NTU-60 and NTU-120). We have found that different interactions require different network designs. We also compare a slightly different version of our method by incorporating time information to address tight interactions achieving SOTA results.
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Apr 29, 2024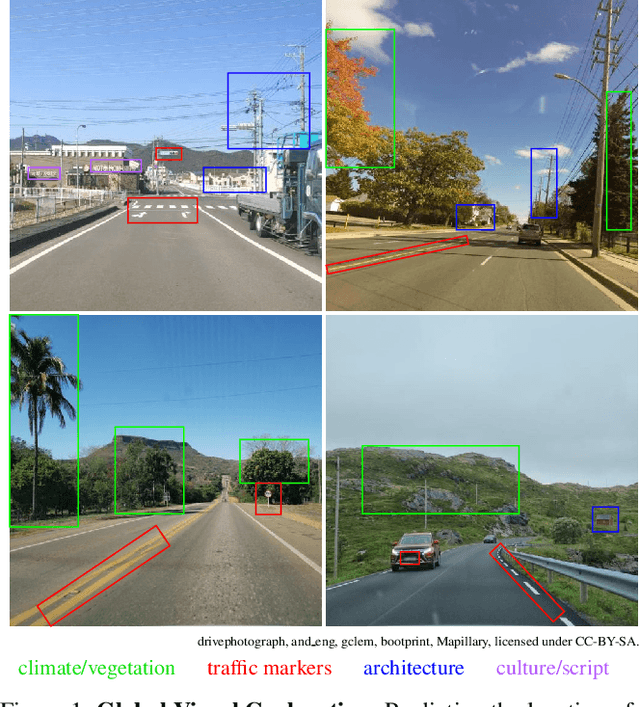
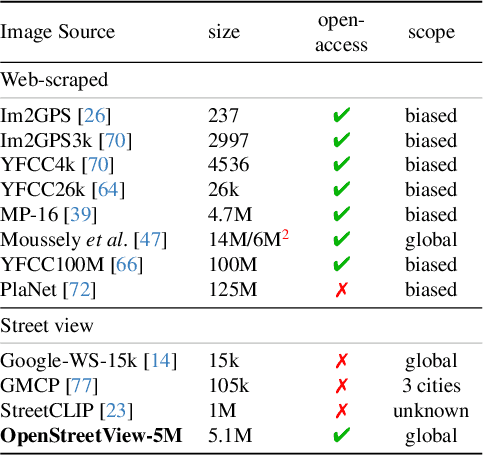

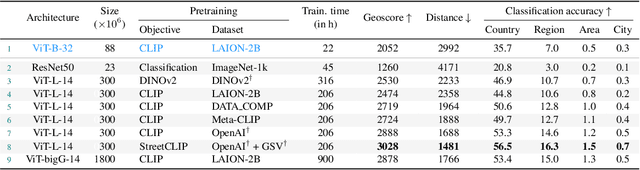
Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
OmniSat: Self-Supervised Modality Fusion for Earth Observation
Apr 12, 2024The field of Earth Observations (EO) offers a wealth of data from diverse sensors, presenting a great opportunity for advancing self-supervised multimodal learning. However, current multimodal EO datasets and models focus on a single data type, either mono-date images or time series, which limits their expressivity. We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. To demonstrate the advantages of combining modalities of different natures, we augment two existing datasets with new modalities. As demonstrated on three downstream tasks: forestry, land cover classification, and crop mapping. OmniSat can learn rich representations in an unsupervised manner, leading to improved performance in the semi- and fully-supervised settings, even when only one modality is available for inference. The code and dataset are available at github.com/gastruc/OmniSat.