 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
Apr 07, 2026This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. The code is available at https://github.com/davidpicard/pom.
Remote Sensing Change Detection via Weak Temporal Supervision
Jan 05, 2026Semantic change detection in remote sensing aims to identify land cover changes between bi-temporal image pairs. Progress in this area has been limited by the scarcity of annotated datasets, as pixel-level annotation is costly and time-consuming. To address this, recent methods leverage synthetic data or generate artificial change pairs, but out-of-domain generalization remains limited. In this work, we introduce a weak temporal supervision strategy that leverages additional temporal observations of existing single-temporal datasets, without requiring any new annotations. Specifically, we extend single-date remote sensing datasets with new observations acquired at different times and train a change detection model by assuming that real bi-temporal pairs mostly contain no change, while pairing images from different locations to generate change examples. To handle the inherent noise in these weak labels, we employ an object-aware change map generation and an iterative refinement process. We validate our approach on extended versions of the FLAIR and IAILD aerial datasets, achieving strong zero-shot and low-data regime performance across different benchmarks. Lastly, we showcase results over large areas in France, highlighting the scalability potential of our method.
CoDEx: Combining Domain Expertise for Spatial Generalization in Satellite Image Analysis
Apr 28, 2025



Global variations in terrain appearance raise a major challenge for satellite image analysis, leading to poor model performance when training on locations that differ from those encountered at test time. This remains true even with recent large global datasets. To address this challenge, we propose a novel domain-generalization framework for satellite images. Instead of trying to learn a single generalizable model, we train one expert model per training domain, while learning experts' similarity and encouraging similar experts to be consistent. A model selection module then identifies the most suitable experts for a given test sample and aggregates their predictions. Experiments on four datasets (DynamicEarthNet, MUDS, OSCD, and FMoW) demonstrate consistent gains over existing domain generalization and adaptation methods. Our code is publicly available at https://github.com/Abhishek19009/CoDEx.
Detecting Looted Archaeological Sites from Satellite Image Time Series
Sep 14, 2024



Archaeological sites are the physical remains of past human activity and one of the main sources of information about past societies and cultures. However, they are also the target of malevolent human actions, especially in countries having experienced inner turmoil and conflicts. Because monitoring these sites from space is a key step towards their preservation, we introduce the DAFA Looted Sites dataset, \datasetname, a labeled multi-temporal remote sensing dataset containing 55,480 images acquired monthly over 8 years across 675 Afghan archaeological sites, including 135 sites looted during the acquisition period. \datasetname~is particularly challenging because of the limited number of training samples, the class imbalance, the weak binary annotations only available at the level of the time series, and the subtlety of relevant changes coupled with important irrelevant ones over a long time period. It is also an interesting playground to assess the performance of satellite image time series (SITS) classification methods on a real and important use case. We evaluate a large set of baselines, outline the substantial benefits of using foundation models and show the additional boost that can be provided by using complete time series instead of using a single image.
Historical Printed Ornaments: Dataset and Tasks
Aug 16, 2024This paper aims to develop the study of historical printed ornaments with modern unsupervised computer vision. We highlight three complex tasks that are of critical interest to book historians: clustering, element discovery, and unsupervised change localization. For each of these tasks, we introduce an evaluation benchmark, and we adapt and evaluate state-of-the-art models. Our Rey's Ornaments dataset is designed to be a representative example of a set of ornaments historians would be interested in. It focuses on an XVIIIth century bookseller, Marc-Michel Rey, providing a consistent set of ornaments with a wide diversity and representative challenges. Our results highlight the limitations of state-of-the-art models when faced with real data and show simple baselines such as k-means or congealing can outperform more sophisticated approaches on such data. Our dataset and code can be found at https://printed-ornaments.github.io/.
Satellite Image Time Series Semantic Change Detection: Novel Architecture and Analysis of Domain Shift
Jul 10, 2024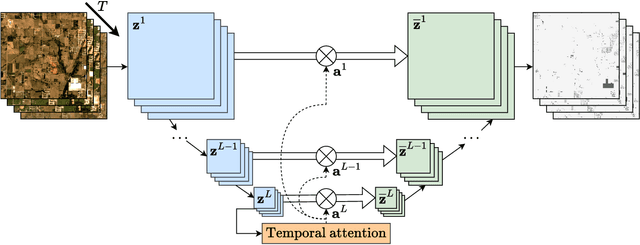
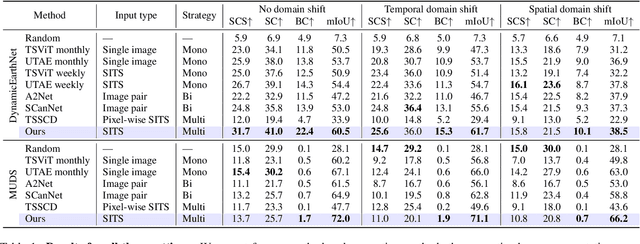
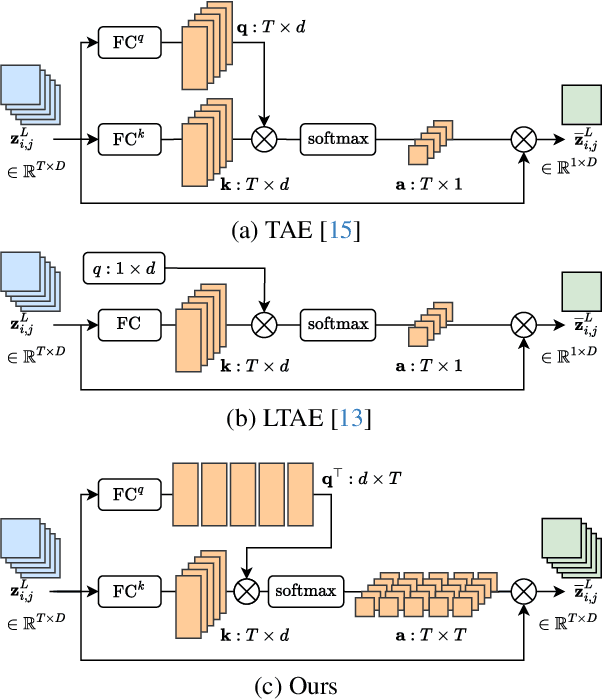
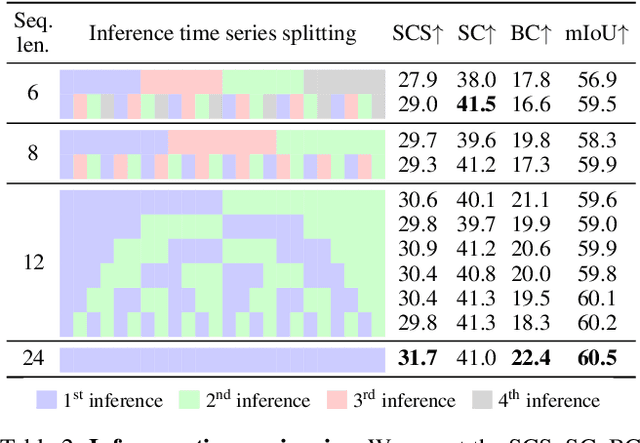
Satellite imagery plays a crucial role in monitoring changes happening on Earth's surface and aiding in climate analysis, ecosystem assessment, and disaster response. In this paper, we tackle semantic change detection with satellite image time series (SITS-SCD) which encompasses both change detection and semantic segmentation tasks. We propose a new architecture that improves over the state of the art, scales better with the number of parameters, and leverages long-term temporal information. However, for practical use cases, models need to adapt to spatial and temporal shifts, which remains a challenge. We investigate the impact of temporal and spatial shifts separately on global, multi-year SITS datasets using DynamicEarthNet and MUDS. We show that the spatial domain shift represents the most complex setting and that the impact of temporal shift on performance is more pronounced on change detection than on semantic segmentation, highlighting that it is a specific issue deserving further attention.
OpenStreetView-5M: The Many Roads to Global Visual Geolocation
Apr 29, 2024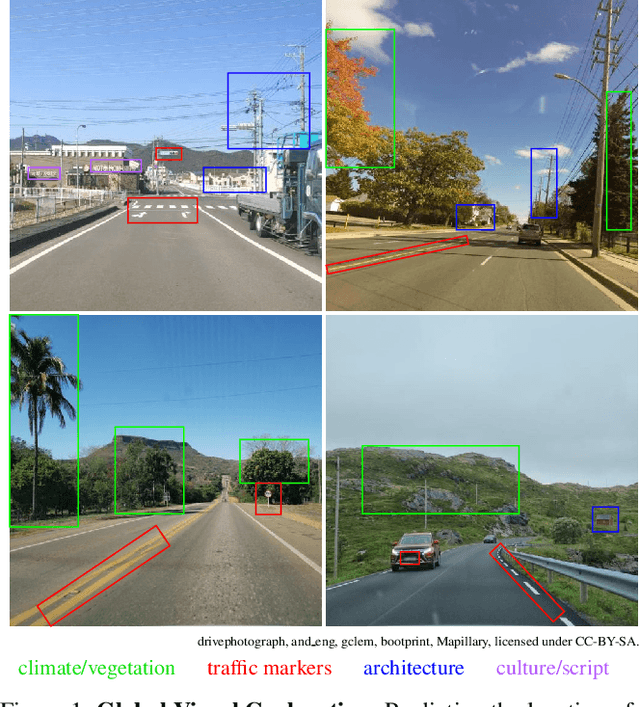
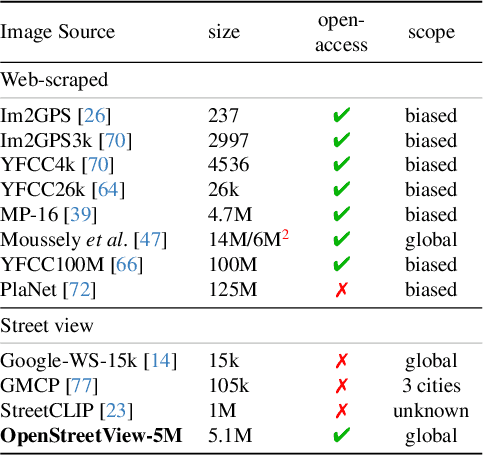

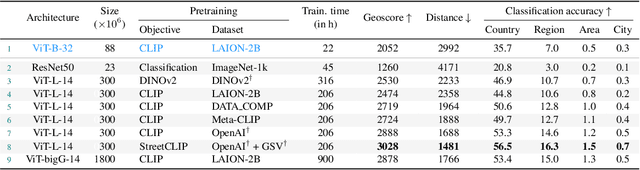
Determining the location of an image anywhere on Earth is a complex visual task, which makes it particularly relevant for evaluating computer vision algorithms. Yet, the absence of standard, large-scale, open-access datasets with reliably localizable images has limited its potential. To address this issue, we introduce OpenStreetView-5M, a large-scale, open-access dataset comprising over 5.1 million geo-referenced street view images, covering 225 countries and territories. In contrast to existing benchmarks, we enforce a strict train/test separation, allowing us to evaluate the relevance of learned geographical features beyond mere memorization. To demonstrate the utility of our dataset, we conduct an extensive benchmark of various state-of-the-art image encoders, spatial representations, and training strategies. All associated codes and models can be found at https://github.com/gastruc/osv5m.
Learnable Earth Parser: Discovering 3D Prototypes in Aerial Scans
Apr 19, 2023
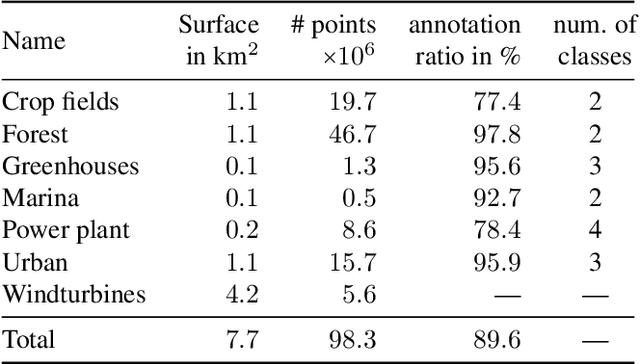
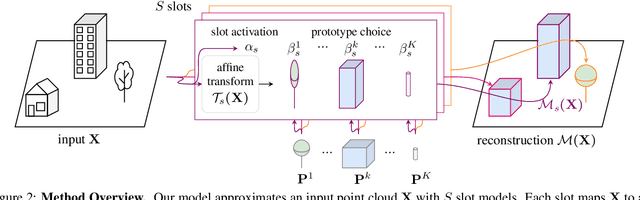

We propose an unsupervised method for parsing large 3D scans of real-world scenes into interpretable parts. Our goal is to provide a practical tool for analyzing 3D scenes with unique characteristics in the context of aerial surveying and mapping, without relying on application-specific user annotations. Our approach is based on a probabilistic reconstruction model that decomposes an input 3D point cloud into a small set of learned prototypical shapes. Our model provides an interpretable reconstruction of complex scenes and leads to relevant instance and semantic segmentations. To demonstrate the usefulness of our results, we introduce a novel dataset of seven diverse aerial LiDAR scans. We show that our method outperforms state-of-the-art unsupervised methods in terms of decomposition accuracy while remaining visually interpretable. Our method offers significant advantage over existing approaches, as it does not require any manual annotations, making it a practical and efficient tool for 3D scene analysis. Our code and dataset are available at https://imagine.enpc.fr/~loiseaur/learnable-earth-parser
Pixel-wise Agricultural Image Time Series Classification: Comparisons and a Deformable Prototype-based Approach
Mar 22, 2023



Improvements in Earth observation by satellites allow for imagery of ever higher temporal and spatial resolution. Leveraging this data for agricultural monitoring is key for addressing environmental and economic challenges. Current methods for crop segmentation using temporal data either rely on annotated data or are heavily engineered to compensate the lack of supervision. In this paper, we present and compare datasets and methods for both supervised and unsupervised pixel-wise segmentation of satellite image time series (SITS). We also introduce an approach to add invariance to spectral deformations and temporal shifts to classical prototype-based methods such as K-means and Nearest Centroid Classifier (NCC). We show this simple and highly interpretable method leads to meaningful results in both the supervised and unsupervised settings and significantly improves the state of the art for unsupervised classification of agricultural time series on four recent SITS datasets.
A Model You Can Hear: Audio Identification with Playable Prototypes
Aug 05, 2022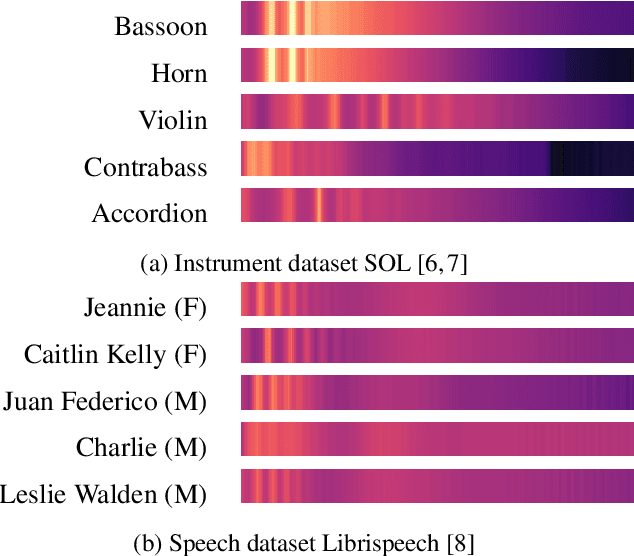
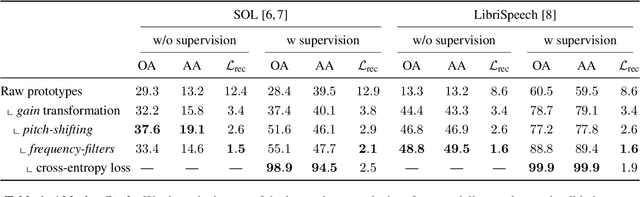

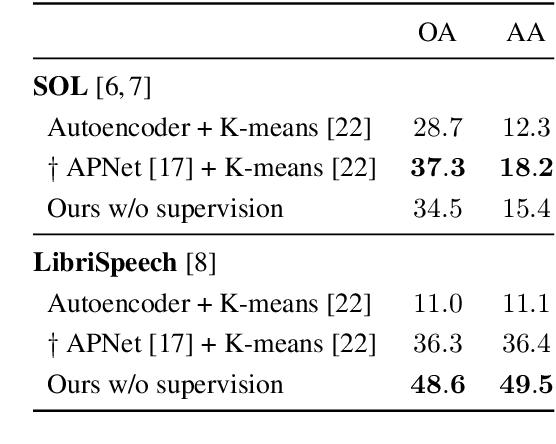
Machine learning techniques have proved useful for classifying and analyzing audio content. However, recent methods typically rely on abstract and high-dimensional representations that are difficult to interpret. Inspired by transformation-invariant approaches developed for image and 3D data, we propose an audio identification model based on learnable spectral prototypes. Equipped with dedicated transformation networks, these prototypes can be used to cluster and classify input audio samples from large collections of sounds. Our model can be trained with or without supervision and reaches state-of-the-art results for speaker and instrument identification, while remaining easily interpretable. The code is available at: https://github.com/romainloiseau/a-model-you-can-hear