 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental Footprint of GenAI Research: Insights from the Moshi Foundation Model
Apr 13, 2026New multi-modal large language models (MLLMs) are continuously being trained and deployed, following rapid development cycles. This generative AI frenzy is driving steady increases in energy consumption, greenhouse gas emissions, and a plethora of other environmental impacts linked to datacenter construction and hardware manufacturing. Mitigating the environmental consequences of GenAI remains challenging due to an overall lack of transparency by the main actors in the field. Even when the environmental impacts of specific models are mentioned, they are typically restricted to the carbon footprint of the final training run, omitting the research and development stages. In this work, we explore the impact of GenAI research through a fine-grained analysis of the compute spent to create Moshi, a 7B-parameter speech-text foundation model for real-time dialogue developed by Kyutai, a leading privately funded open science AI lab. For the first time, our study dives into the anatomy of compute-intensive MLLM research, quantifying the GPU-time invested in specific model components and training phases, as well as early experimental stages, failed training runs, debugging, and ablation studies. Additionally, we assess the environmental impacts of creating Moshi from beginning to end using a life cycle assessment methodology: we quantify energy and water consumption, greenhouse gas emissions, and mineral resource depletion associated with the production and use of datacenter hardware. Our detailed analysis allows us to provide actionable guidelines to reduce compute usage and environmental impacts of MLLM research, paving the way for more sustainable AI research.
UNIGEOCLIP: Unified Geospatial Contrastive Learning
Apr 13, 2026The growing availability of co-located geospatial data spanning aerial imagery, street-level views, elevation models, text, and geographic coordinates offers a unique opportunity for multimodal representation learning. We introduce UNIGEOCLIP, a massively multimodal contrastive framework to jointly align five complementary geospatial modalities in a single unified embedding space. Unlike prior approaches that fuse modalities or rely on a central pivot representation, our method performs all-to-all contrastive alignment, enabling seamless comparison, retrieval, and reasoning across arbitrary combinations of modalities. We further propose a scaled latitude-longitude encoder that improves spatial representation by capturing multi-scale geographic structure. Extensive experiments across downstream geospatial tasks demonstrate that UNIGEOCLIP consistently outperforms single-modality contrastive models and coordinate-only baselines, highlighting the benefits of holistic multimodal geospatial alignment. A reference implementation is available at https://gastruc.github.io/unigeoclip.
PoM: A Linear-Time Replacement for Attention with the Polynomial Mixer
Apr 07, 2026This paper introduces the Polynomial Mixer (PoM), a novel token mixing mechanism with linear complexity that serves as a drop-in replacement for self-attention. PoM aggregates input tokens into a compact representation through a learned polynomial function, from which each token retrieves contextual information. We prove that PoM satisfies the contextual mapping property, ensuring that transformers equipped with PoM remain universal sequence-to-sequence approximators. We replace standard self-attention with PoM across five diverse domains: text generation, handwritten text recognition, image generation, 3D modeling, and Earth observation. PoM matches the performance of attention-based models while drastically reducing computational cost when working with long sequences. The code is available at https://github.com/davidpicard/pom.
Adapting Vision Transformers to Ultra-High Resolution Semantic Segmentation with Relay Tokens
Jan 09, 2026Current approaches for segmenting ultra high resolution images either slide a window, thereby discarding global context, or downsample and lose fine detail. We propose a simple yet effective method that brings explicit multi scale reasoning to vision transformers, simultaneously preserving local details and global awareness. Concretely, we process each image in parallel at a local scale (high resolution, small crops) and a global scale (low resolution, large crops), and aggregate and propagate features between the two branches with a small set of learnable relay tokens. The design plugs directly into standard transformer backbones (eg ViT and Swin) and adds fewer than 2 % parameters. Extensive experiments on three ultra high resolution segmentation benchmarks, Archaeoscape, URUR, and Gleason, and on the conventional Cityscapes dataset show consistent gains, with up to 15 % relative mIoU improvement. Code and pretrained models are available at https://archaeoscape.ai/work/relay-tokens/ .
FORMSpoT: A Decade of Tree-Level, Country-Scale Forest Monitoring
Dec 18, 2025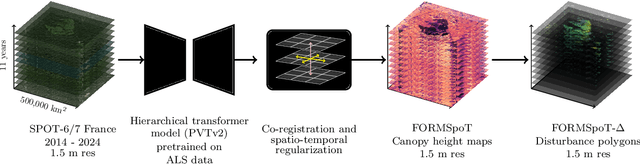
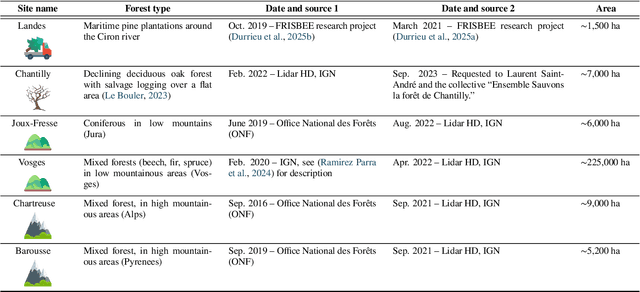
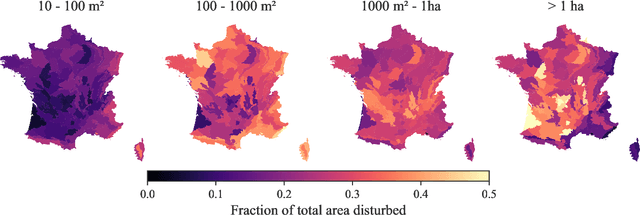
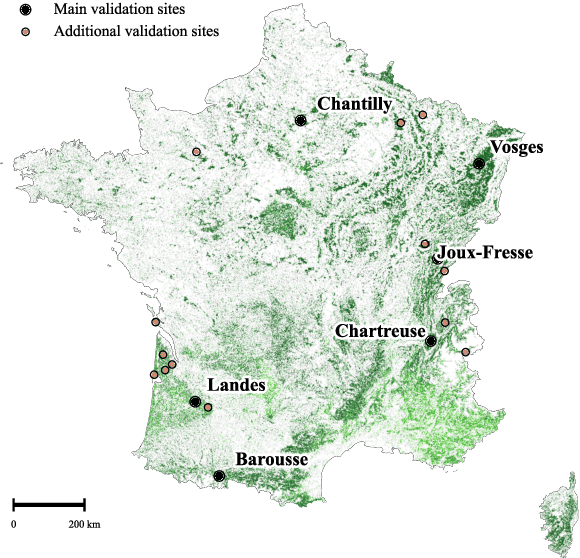
The recent decline of the European forest carbon sink highlights the need for spatially explicit and frequently updated forest monitoring tools. Yet, existing satellite-based disturbance products remain too coarse to detect changes at the scale of individual trees, typically below 100 m$^{2}$. Here, we introduce FORMSpoT (Forest Mapping with SPOT Time series), a decade-long (2014-2024) nationwide mapping of forest canopy height at 1.5 m resolution, together with annual disturbance polygons (FORMSpoT-$Δ$) covering mainland France. Canopy heights were derived from annual SPOT-6/7 composites using a hierarchical transformer model (PVTv2) trained on high-resolution airborne laser scanning (ALS) data. To enable robust change detection across heterogeneous acquisitions, we developed a dedicated post-processing pipeline combining co-registration and spatio-temporal total variation denoising. Validation against ALS revisits across 19 sites and 5,087 National Forest Inventory plots shows that FORMSpoT-$Δ$ substantially outperforms existing disturbance products. In mountainous forests, where disturbances are small and spatially fragmented, FORMSpoT-$Δ$ achieves an F1-score of 0.44, representing an order of magnitude higher than existing benchmarks. By enabling tree-level monitoring of forest dynamics at national scale, FORMSpoT-$Δ$ provides a unique tool to analyze management practices, detect early signals of forest decline, and better quantify carbon losses from subtle disturbances such as thinning or selective logging. These results underscore the critical importance of sustaining very high-resolution satellite missions like SPOT and open-data initiatives such as DINAMIS for monitoring forests under climate change.
Segmenting France Across Four Centuries
May 30, 2025



Historical maps offer an invaluable perspective into territory evolution across past centuries--long before satellite or remote sensing technologies existed. Deep learning methods have shown promising results in segmenting historical maps, but publicly available datasets typically focus on a single map type or period, require extensive and costly annotations, and are not suited for nationwide, long-term analyses. In this paper, we introduce a new dataset of historical maps tailored for analyzing large-scale, long-term land use and land cover evolution with limited annotations. Spanning metropolitan France (548,305 km^2), our dataset contains three map collections from the 18th, 19th, and 20th centuries. We provide both comprehensive modern labels and 22,878 km^2 of manually annotated historical labels for the 18th and 19th century maps. Our dataset illustrates the complexity of the segmentation task, featuring stylistic inconsistencies, interpretive ambiguities, and significant landscape changes (e.g., marshlands disappearing in favor of forests). We assess the difficulty of these challenges by benchmarking three approaches: a fully-supervised model trained with historical labels, and two weakly-supervised models that rely only on modern annotations. The latter either use the modern labels directly or first perform image-to-image translation to address the stylistic gap between historical and contemporary maps. Finally, we discuss how these methods can support long-term environment monitoring, offering insights into centuries of landscape transformation. Our official project repository is publicly available at https://github.com/Archiel19/FRAx4.git.
CoDEx: Combining Domain Expertise for Spatial Generalization in Satellite Image Analysis
Apr 28, 2025



Global variations in terrain appearance raise a major challenge for satellite image analysis, leading to poor model performance when training on locations that differ from those encountered at test time. This remains true even with recent large global datasets. To address this challenge, we propose a novel domain-generalization framework for satellite images. Instead of trying to learn a single generalizable model, we train one expert model per training domain, while learning experts' similarity and encouraging similar experts to be consistent. A model selection module then identifies the most suitable experts for a given test sample and aggregates their predictions. Experiments on four datasets (DynamicEarthNet, MUDS, OSCD, and FMoW) demonstrate consistent gains over existing domain generalization and adaptation methods. Our code is publicly available at https://github.com/Abhishek19009/CoDEx.
AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities
Dec 18, 2024



Geospatial models must adapt to the diversity of Earth observation data in terms of resolutions, scales, and modalities. However, existing approaches expect fixed input configurations, which limits their practical applicability. We propose AnySat, a multimodal model based on joint embedding predictive architecture (JEPA) and resolution-adaptive spatial encoders, allowing us to train a single model on highly heterogeneous data in a self-supervised manner. To demonstrate the advantages of this unified approach, we compile GeoPlex, a collection of $5$ multimodal datasets with varying characteristics and $11$ distinct sensors. We then train a single powerful model on these diverse datasets simultaneously. Once fine-tuned, we achieve better or near state-of-the-art results on the datasets of GeoPlex and $4$ additional ones for $5$ environment monitoring tasks: land cover mapping, tree species identification, crop type classification, change detection, and flood segmentation. The code and models are available at https://github.com/gastruc/AnySat.
Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation
Dec 09, 2024


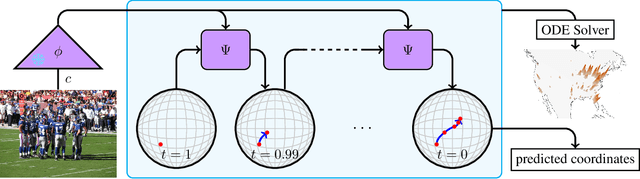
Global visual geolocation predicts where an image was captured on Earth. Since images vary in how precisely they can be localized, this task inherently involves a significant degree of ambiguity. However, existing approaches are deterministic and overlook this aspect. In this paper, we aim to close the gap between traditional geolocalization and modern generative methods. We propose the first generative geolocation approach based on diffusion and Riemannian flow matching, where the denoising process operates directly on the Earth's surface. Our model achieves state-of-the-art performance on three visual geolocation benchmarks: OpenStreetView-5M, YFCC-100M, and iNat21. In addition, we introduce the task of probabilistic visual geolocation, where the model predicts a probability distribution over all possible locations instead of a single point. We introduce new metrics and baselines for this task, demonstrating the advantages of our diffusion-based approach. Codes and models will be made available.
Archaeoscape: Bringing Aerial Laser Scanning Archaeology to the Deep Learning Era
Dec 06, 2024
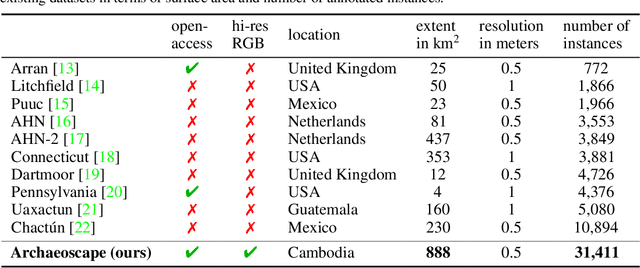
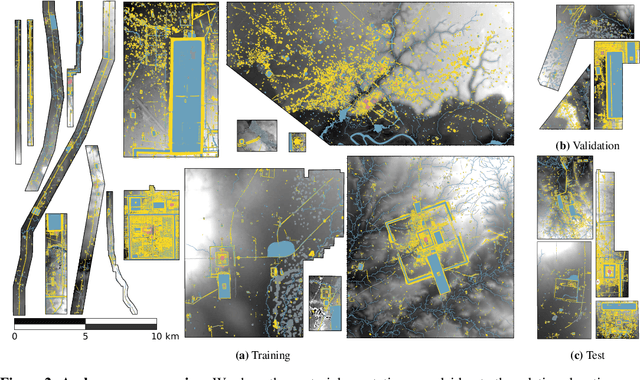
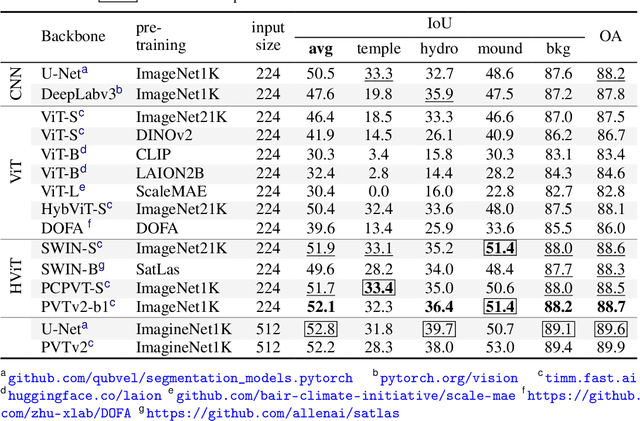
Airborne Laser Scanning (ALS) technology has transformed modern archaeology by unveiling hidden landscapes beneath dense vegetation. However, the lack of expert-annotated, open-access resources has hindered the analysis of ALS data using advanced deep learning techniques. We address this limitation with Archaeoscape (available at https://archaeoscape.ai), a novel large-scale archaeological ALS dataset spanning 888 km$^2$ in Cambodia with 31,141 annotated archaeological features from the Angkorian period. Archaeoscape is over four times larger than comparable datasets, and the first ALS archaeology resource with open-access data, annotations, and models. We benchmark several recent segmentation models to demonstrate the benefits of modern vision techniques for this problem and highlight the unique challenges of discovering subtle human-made structures under dense jungle canopies. By making Archaeoscape available in open access, we hope to bridge the gap between traditional archaeology and modern computer vision methods.