 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning enables urban change profiling through alignment of historical maps
Feb 02, 2026Prior to modern Earth observation technologies, historical maps provide a unique record of long-term urban transformation and offer a lens on the evolving identity of cities. However, extracting consistent and fine-grained change information from historical map series remains challenging due to spatial misalignment, cartographic variation, and degrading document quality, limiting most analyses to small-scale or qualitative approaches. We propose a fully automated, deep learning-based framework for fine-grained urban change analysis from large collections of historical maps, built on a modular design that integrates dense map alignment, multi-temporal object detection, and change profiling. This framework shifts the analysis of historical maps from ad hoc visual comparison toward systematic, quantitative characterization of urban change. Experiments demonstrate the robust performance of the proposed alignment and object detection methods. Applied to Paris between 1868 and 1937, the framework reveals the spatial and temporal heterogeneity in urban transformation, highlighting its relevance for research in the social sciences and humanities. The modular design of our framework further supports adaptation to diverse cartographic contexts and downstream applications.
Generative AI in Map-Making: A Technical Exploration and Its Implications for Cartographers
Aug 26, 2025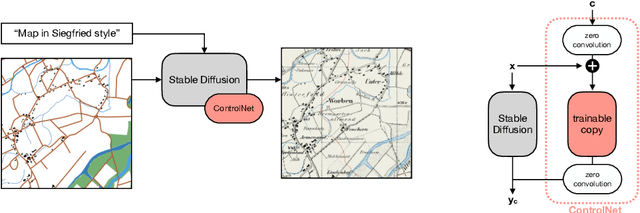
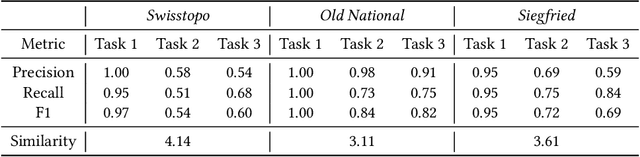
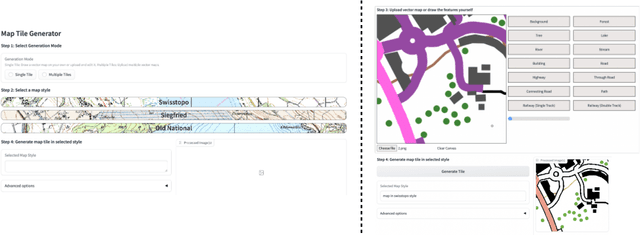
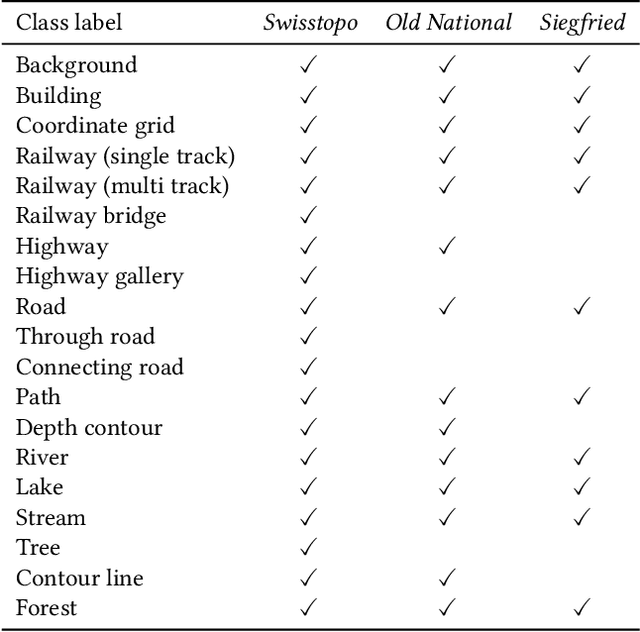
Traditional map-making relies heavily on Geographic Information Systems (GIS), requiring domain expertise and being time-consuming, especially for repetitive tasks. Recent advances in generative AI (GenAI), particularly image diffusion models, offer new opportunities for automating and democratizing the map-making process. However, these models struggle with accurate map creation due to limited control over spatial composition and semantic layout. To address this, we integrate vector data to guide map generation in different styles, specified by the textual prompts. Our model is the first to generate accurate maps in controlled styles, and we have integrated it into a web application to improve its usability and accessibility. We conducted a user study with professional cartographers to assess the fidelity of generated maps, the usability of the web application, and the implications of ever-emerging GenAI in map-making. The findings have suggested the potential of our developed application and, more generally, the GenAI models in helping both non-expert users and professionals in creating maps more efficiently. We have also outlined further technical improvements and emphasized the new role of cartographers to advance the paradigm of AI-assisted map-making.
Unsupervised Urban Land Use Mapping with Street View Contrastive Clustering and a Geographical Prior
Apr 24, 2025Urban land use classification and mapping are critical for urban planning, resource management, and environmental monitoring. Existing remote sensing techniques often lack precision in complex urban environments due to the absence of ground-level details. Unlike aerial perspectives, street view images provide a ground-level view that captures more human and social activities relevant to land use in complex urban scenes. Existing street view-based methods primarily rely on supervised classification, which is challenged by the scarcity of high-quality labeled data and the difficulty of generalizing across diverse urban landscapes. This study introduces an unsupervised contrastive clustering model for street view images with a built-in geographical prior, to enhance clustering performance. When combined with a simple visual assignment of the clusters, our approach offers a flexible and customizable solution to land use mapping, tailored to the specific needs of urban planners. We experimentally show that our method can generate land use maps from geotagged street view image datasets of two cities. As our methodology relies on the universal spatial coherence of geospatial data ("Tobler's law"), it can be adapted to various settings where street view images are available, to enable scalable, unsupervised land use mapping and updating. The code will be available at https://github.com/lin102/CCGP.
A roadmap for generative mapping: unlocking the power of generative AI for map-making
Oct 21, 2024Maps are broadly relevant across various fields, serving as valuable tools for presenting spatial phenomena and communicating spatial knowledge. However, map-making is still largely confined to those with expertise in GIS and cartography due to the specialized software and complex workflow involved, from data processing to visualization. While generative AI has recently demonstrated its remarkable capability in creating various types of content and its wide accessibility to the general public, its potential in generating maps is yet to be fully realized. This paper highlights the key applications of generative AI in map-making, summarizes recent advancements in generative AI, identifies the specific technologies required and the challenges of using current methods, and provides a roadmap for developing a generative mapping system (GMS) to make map-making more accessible.
An Efficient System for Automatic Map Storytelling -- A Case Study on Historical Maps
Oct 21, 2024



Historical maps provide valuable information and knowledge about the past. However, as they often feature non-standard projections, hand-drawn styles, and artistic elements, it is challenging for non-experts to identify and interpret them. While existing image captioning methods have achieved remarkable success on natural images, their performance on maps is suboptimal as maps are underrepresented in their pre-training process. Despite the recent advance of GPT-4 in text recognition and map captioning, it still has a limited understanding of maps, as its performance wanes when texts (e.g., titles and legends) in maps are missing or inaccurate. Besides, it is inefficient or even impractical to fine-tune the model with users' own datasets. To address these problems, we propose a novel and lightweight map-captioning counterpart. Specifically, we fine-tune the state-of-the-art vision-language model CLIP to generate captions relevant to historical maps and enrich the captions with GPT-3.5 to tell a brief story regarding where, what, when and why of a given map. We propose a novel decision tree architecture to only generate captions relevant to the specified map type. Our system shows invariance to text alterations in maps. The system can be easily adapted and extended to other map types and scaled to a larger map captioning system. The code is open-sourced at https://github.com/claudaff/automatic-map-storytelling.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024



Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
Cross-attention Spatio-temporal Context Transformer for Semantic Segmentation of Historical Maps
Oct 19, 2023



Historical maps provide useful spatio-temporal information on the Earth's surface before modern earth observation techniques came into being. To extract information from maps, neural networks, which gain wide popularity in recent years, have replaced hand-crafted map processing methods and tedious manual labor. However, aleatoric uncertainty, known as data-dependent uncertainty, inherent in the drawing/scanning/fading defects of the original map sheets and inadequate contexts when cropping maps into small tiles considering the memory limits of the training process, challenges the model to make correct predictions. As aleatoric uncertainty cannot be reduced even with more training data collected, we argue that complementary spatio-temporal contexts can be helpful. To achieve this, we propose a U-Net-based network that fuses spatio-temporal features with cross-attention transformers (U-SpaTem), aggregating information at a larger spatial range as well as through a temporal sequence of images. Our model achieves a better performance than other state-or-art models that use either temporal or spatial contexts. Compared with pure vision transformers, our model is more lightweight and effective. To the best of our knowledge, leveraging both spatial and temporal contexts have been rarely explored before in the segmentation task. Even though our application is on segmenting historical maps, we believe that the method can be transferred into other fields with similar problems like temporal sequences of satellite images. Our code is freely accessible at https://github.com/chenyizi086/wu.2023.sigspatial.git.
BuyTheDips: PathLoss for improved topology-preserving deep learning-based image segmentation
Jul 23, 2022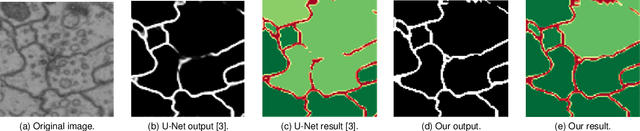
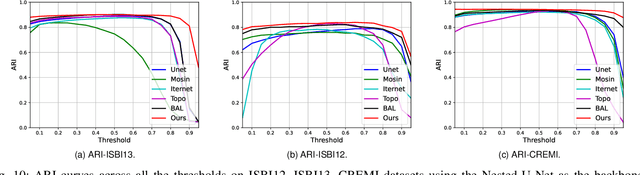
Capturing the global topology of an image is essential for proposing an accurate segmentation of its domain. However, most of existing segmentation methods do not preserve the initial topology of the given input, which is detrimental for numerous downstream object-based tasks. This is all the more true for deep learning models which most work at local scales. In this paper, we propose a new topology-preserving deep image segmentation method which relies on a new leakage loss: the Pathloss. Our method is an extension of the BALoss [1], in which we want to improve the leakage detection for better recovering the closeness property of the image segmentation. This loss allows us to correctly localize and fix the critical points (a leakage in the boundaries) that could occur in the predictions, and is based on a shortest-path search algorithm. This way, loss minimization enforces connectivity only where it is necessary and finally provides a good localization of the boundaries of the objects in the image. Moreover, according to our research, our Pathloss learns to preserve stronger elongated structure compared to methods without using topology-preserving loss. Training with our topological loss function, our method outperforms state-of-the-art topology-aware methods on two representative datasets of different natures: Electron Microscopy and Historical Map.
ICDAR 2021 Competition on Historical Map Segmentation
May 27, 2021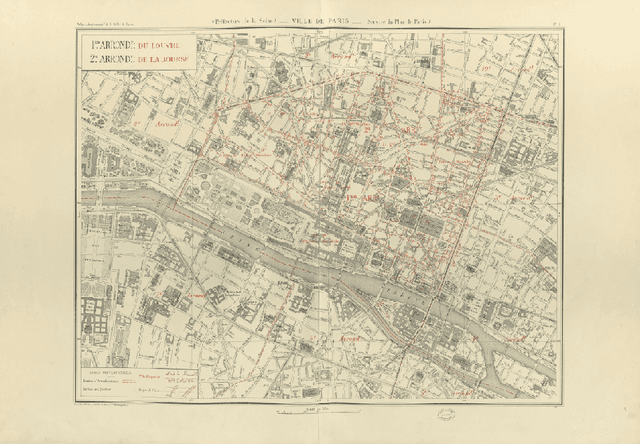
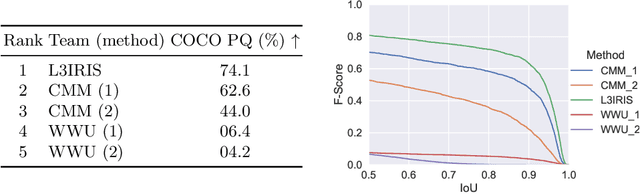
This paper presents the final results of the ICDAR 2021 Competition on Historical Map Segmentation (MapSeg), encouraging research on a series of historical atlases of Paris, France, drawn at 1/5000 scale between 1894 and 1937. The competition featured three tasks, awarded separately. Task~1 consists in detecting building blocks and was won by the L3IRIS team using a DenseNet-121 network trained in a weakly supervised fashion. This task is evaluated on 3 large images containing hundreds of shapes to detect. Task~2 consists in segmenting map content from the larger map sheet, and was won by the UWB team using a U-Net-like FCN combined with a binarization method to increase detection edge accuracy. Task~3 consists in locating intersection points of geo-referencing lines, and was also won by the UWB team who used a dedicated pipeline combining binarization, line detection with Hough transform, candidate filtering, and template matching for intersection refinement. Tasks~2 and~3 are evaluated on 95 map sheets with complex content. Dataset, evaluation tools and results are available under permissive licensing at \url{https://icdar21-mapseg.github.io/}.
Combining Deep Learning and Mathematical Morphology for Historical Map Segmentation
Jan 06, 2021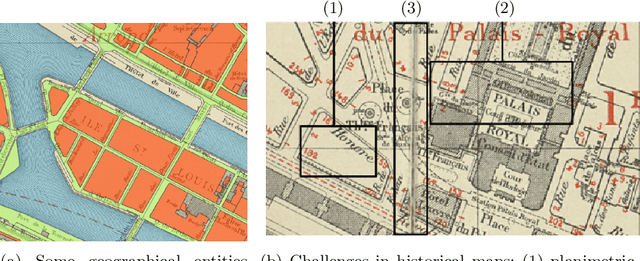
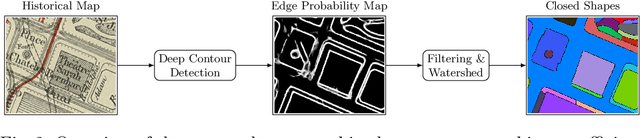


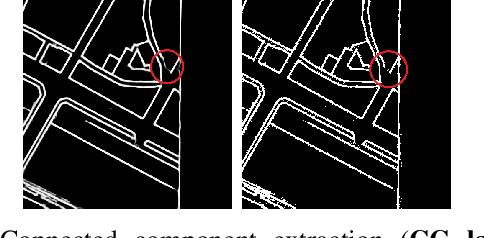
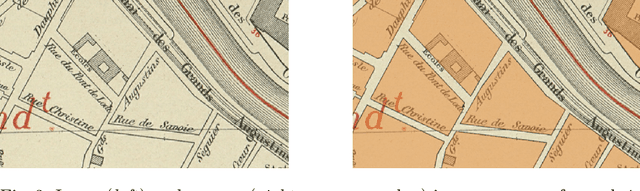
The digitization of historical maps enables the study of ancient, fragile, unique, and hardly accessible information sources. Main map features can be retrieved and tracked through the time for subsequent thematic analysis. The goal of this work is the vectorization step, i.e., the extraction of vector shapes of the objects of interest from raster images of maps. We are particularly interested in closed shape detection such as buildings, building blocks, gardens, rivers, etc. in order to monitor their temporal evolution. Historical map images present significant pattern recognition challenges. The extraction of closed shapes by using traditional Mathematical Morphology (MM) is highly challenging due to the overlapping of multiple map features and texts. Moreover, state-of-the-art Convolutional Neural Networks (CNN) are perfectly designed for content image filtering but provide no guarantee about closed shape detection. Also, the lack of textural and color information of historical maps makes it hard for CNN to detect shapes that are represented by only their boundaries. Our contribution is a pipeline that combines the strengths of CNN (efficient edge detection and filtering) and MM (guaranteed extraction of closed shapes) in order to achieve such a task. The evaluation of our approach on a public dataset shows its effectiveness for extracting the closed boundaries of objects in historical maps.