 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in Map-Making: A Technical Exploration and Its Implications for Cartographers
Aug 26, 2025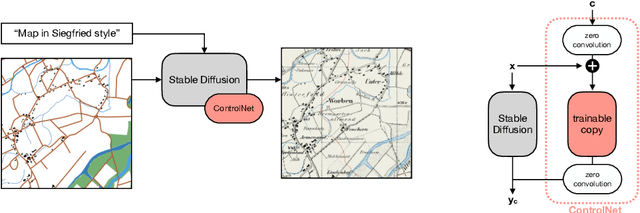
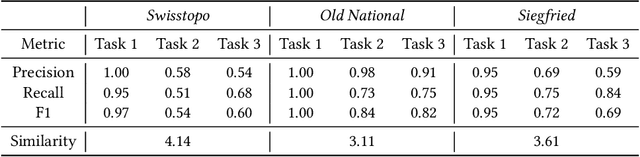
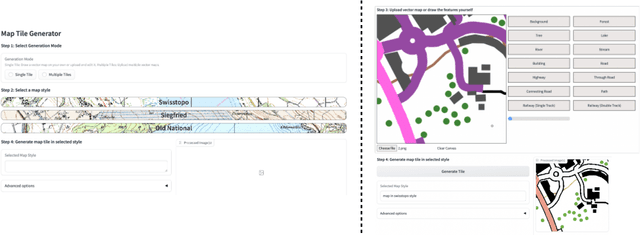
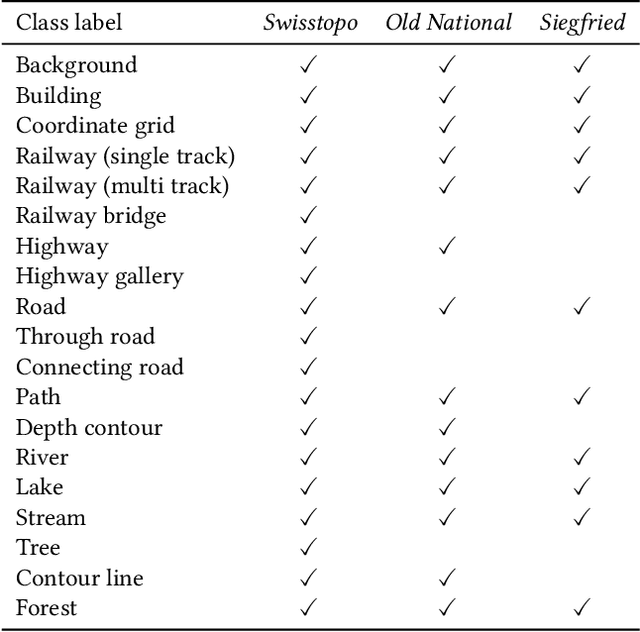
Traditional map-making relies heavily on Geographic Information Systems (GIS), requiring domain expertise and being time-consuming, especially for repetitive tasks. Recent advances in generative AI (GenAI), particularly image diffusion models, offer new opportunities for automating and democratizing the map-making process. However, these models struggle with accurate map creation due to limited control over spatial composition and semantic layout. To address this, we integrate vector data to guide map generation in different styles, specified by the textual prompts. Our model is the first to generate accurate maps in controlled styles, and we have integrated it into a web application to improve its usability and accessibility. We conducted a user study with professional cartographers to assess the fidelity of generated maps, the usability of the web application, and the implications of ever-emerging GenAI in map-making. The findings have suggested the potential of our developed application and, more generally, the GenAI models in helping both non-expert users and professionals in creating maps more efficiently. We have also outlined further technical improvements and emphasized the new role of cartographers to advance the paradigm of AI-assisted map-making.
An Efficient System for Automatic Map Storytelling -- A Case Study on Historical Maps
Oct 21, 2024



Historical maps provide valuable information and knowledge about the past. However, as they often feature non-standard projections, hand-drawn styles, and artistic elements, it is challenging for non-experts to identify and interpret them. While existing image captioning methods have achieved remarkable success on natural images, their performance on maps is suboptimal as maps are underrepresented in their pre-training process. Despite the recent advance of GPT-4 in text recognition and map captioning, it still has a limited understanding of maps, as its performance wanes when texts (e.g., titles and legends) in maps are missing or inaccurate. Besides, it is inefficient or even impractical to fine-tune the model with users' own datasets. To address these problems, we propose a novel and lightweight map-captioning counterpart. Specifically, we fine-tune the state-of-the-art vision-language model CLIP to generate captions relevant to historical maps and enrich the captions with GPT-3.5 to tell a brief story regarding where, what, when and why of a given map. We propose a novel decision tree architecture to only generate captions relevant to the specified map type. Our system shows invariance to text alterations in maps. The system can be easily adapted and extended to other map types and scaled to a larger map captioning system. The code is open-sourced at https://github.com/claudaff/automatic-map-storytelling.