 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning enables urban change profiling through alignment of historical maps
Feb 02, 2026Prior to modern Earth observation technologies, historical maps provide a unique record of long-term urban transformation and offer a lens on the evolving identity of cities. However, extracting consistent and fine-grained change information from historical map series remains challenging due to spatial misalignment, cartographic variation, and degrading document quality, limiting most analyses to small-scale or qualitative approaches. We propose a fully automated, deep learning-based framework for fine-grained urban change analysis from large collections of historical maps, built on a modular design that integrates dense map alignment, multi-temporal object detection, and change profiling. This framework shifts the analysis of historical maps from ad hoc visual comparison toward systematic, quantitative characterization of urban change. Experiments demonstrate the robust performance of the proposed alignment and object detection methods. Applied to Paris between 1868 and 1937, the framework reveals the spatial and temporal heterogeneity in urban transformation, highlighting its relevance for research in the social sciences and humanities. The modular design of our framework further supports adaptation to diverse cartographic contexts and downstream applications.
MapSAM2: Adapting SAM2 for Automatic Segmentation of Historical Map Images and Time Series
Oct 31, 2025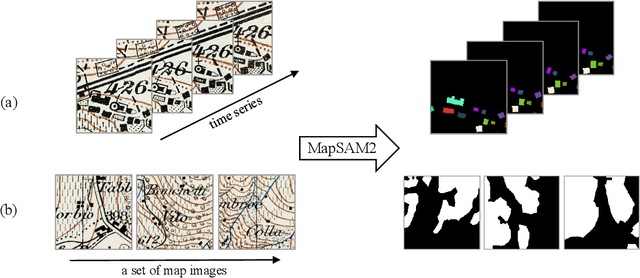
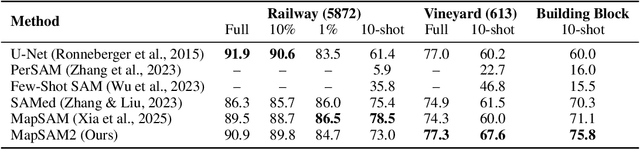
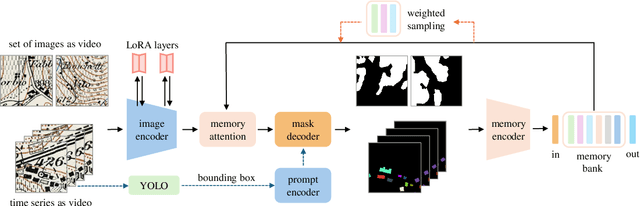
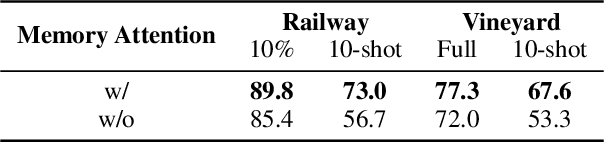
Historical maps are unique and valuable archives that document geographic features across different time periods. However, automated analysis of historical map images remains a significant challenge due to their wide stylistic variability and the scarcity of annotated training data. Constructing linked spatio-temporal datasets from historical map time series is even more time-consuming and labor-intensive, as it requires synthesizing information from multiple maps. Such datasets are essential for applications such as dating buildings, analyzing the development of road networks and settlements, studying environmental changes etc. We present MapSAM2, a unified framework for automatically segmenting both historical map images and time series. Built on a visual foundation model, MapSAM2 adapts to diverse segmentation tasks with few-shot fine-tuning. Our key innovation is to treat both historical map images and time series as videos. For images, we process a set of tiles as a video, enabling the memory attention mechanism to incorporate contextual cues from similar tiles, leading to improved geometric accuracy, particularly for areal features. For time series, we introduce the annotated Siegfried Building Time Series Dataset and, to reduce annotation costs, propose generating pseudo time series from single-year maps by simulating common temporal transformations. Experimental results show that MapSAM2 learns temporal associations effectively and can accurately segment and link buildings in time series under limited supervision or using pseudo videos. We will release both our dataset and code to support future research.
Generative AI in Map-Making: A Technical Exploration and Its Implications for Cartographers
Aug 26, 2025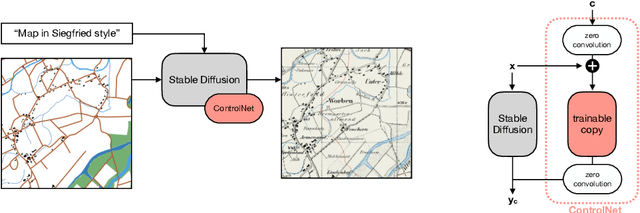
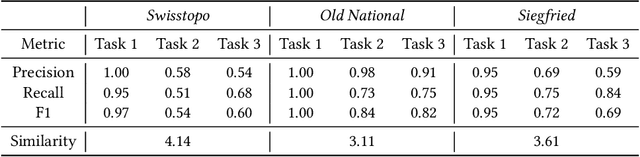
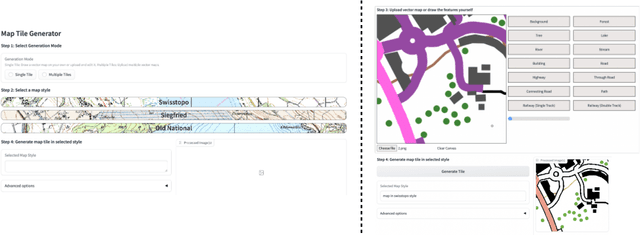
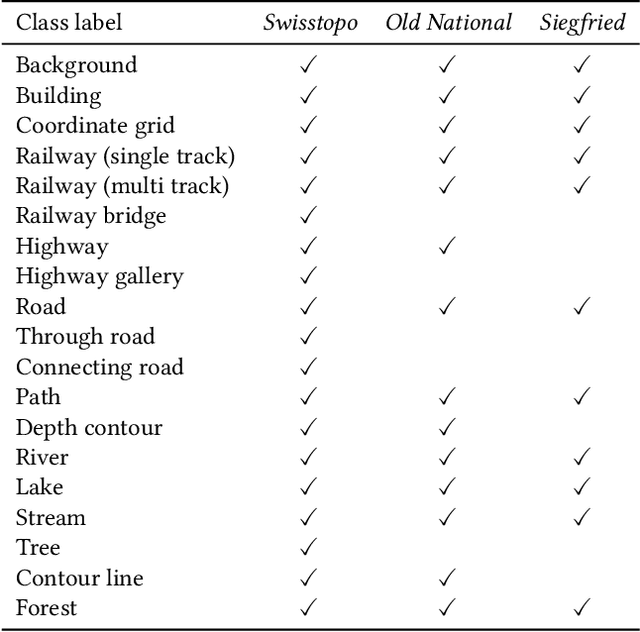
Traditional map-making relies heavily on Geographic Information Systems (GIS), requiring domain expertise and being time-consuming, especially for repetitive tasks. Recent advances in generative AI (GenAI), particularly image diffusion models, offer new opportunities for automating and democratizing the map-making process. However, these models struggle with accurate map creation due to limited control over spatial composition and semantic layout. To address this, we integrate vector data to guide map generation in different styles, specified by the textual prompts. Our model is the first to generate accurate maps in controlled styles, and we have integrated it into a web application to improve its usability and accessibility. We conducted a user study with professional cartographers to assess the fidelity of generated maps, the usability of the web application, and the implications of ever-emerging GenAI in map-making. The findings have suggested the potential of our developed application and, more generally, the GenAI models in helping both non-expert users and professionals in creating maps more efficiently. We have also outlined further technical improvements and emphasized the new role of cartographers to advance the paradigm of AI-assisted map-making.
Self-supervised Video Instance Segmentation Can Boost Geographic Entity Alignment in Historical Maps
Nov 26, 2024



Tracking geographic entities from historical maps, such as buildings, offers valuable insights into cultural heritage, urbanization patterns, environmental changes, and various historical research endeavors. However, linking these entities across diverse maps remains a persistent challenge for researchers. Traditionally, this has been addressed through a two-step process: detecting entities within individual maps and then associating them via a heuristic-based post-processing step. In this paper, we propose a novel approach that combines segmentation and association of geographic entities in historical maps using video instance segmentation (VIS). This method significantly streamlines geographic entity alignment and enhances automation. However, acquiring high-quality, video-format training data for VIS models is prohibitively expensive, especially for historical maps that often contain hundreds or thousands of geographic entities. To mitigate this challenge, we explore self-supervised learning (SSL) techniques to enhance VIS performance on historical maps. We evaluate the performance of VIS models under different pretraining configurations and introduce a novel method for generating synthetic videos from unlabeled historical map images for pretraining. Our proposed self-supervised VIS method substantially reduces the need for manual annotation. Experimental results demonstrate the superiority of the proposed self-supervised VIS approach, achieving a 24.9\% improvement in AP and a 0.23 increase in F1 score compared to the model trained from scratch.
MapSAM: Adapting Segment Anything Model for Automated Feature Detection in Historical Maps
Nov 11, 2024
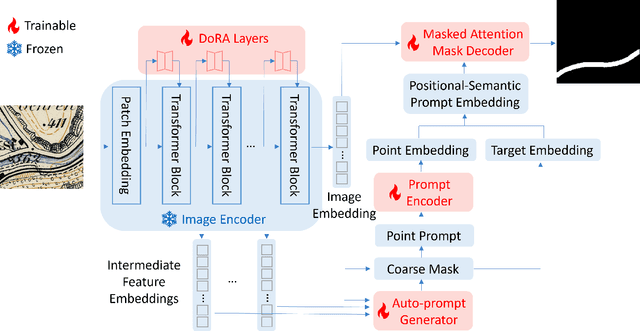
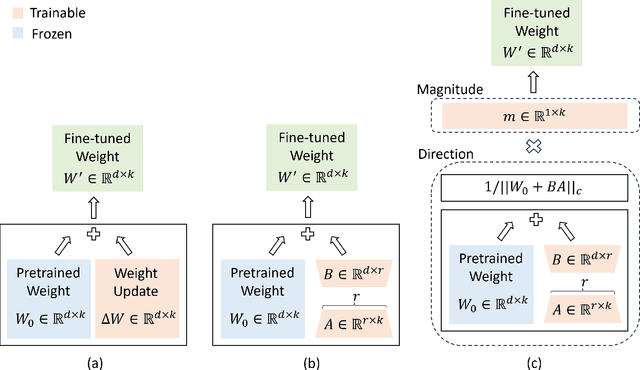

Automated feature detection in historical maps can significantly accelerate the reconstruction of the geospatial past. However, this process is often constrained by the time-consuming task of manually digitizing sufficient high-quality training data. The emergence of visual foundation models, such as the Segment Anything Model (SAM), offers a promising solution due to their remarkable generalization capabilities and rapid adaptation to new data distributions. Despite this, directly applying SAM in a zero-shot manner to historical map segmentation poses significant challenges, including poor recognition of certain geospatial features and a reliance on input prompts, which limits its ability to be fully automated. To address these challenges, we introduce MapSAM, a parameter-efficient fine-tuning strategy that adapts SAM into a prompt-free and versatile solution for various downstream historical map segmentation tasks. Specifically, we employ Weight-Decomposed Low-Rank Adaptation (DoRA) to integrate domain-specific knowledge into the image encoder. Additionally, we develop an automatic prompt generation process, eliminating the need for manual input. We further enhance the positional prompt in SAM, transforming it into a higher-level positional-semantic prompt, and modify the cross-attention mechanism in the mask decoder with masked attention for more effective feature aggregation. The proposed MapSAM framework demonstrates promising performance across two distinct historical map segmentation tasks: one focused on linear features and the other on areal features. Experimental results show that it adapts well to various features, even when fine-tuned with extremely limited data (e.g. 10 shots).
An Efficient System for Automatic Map Storytelling -- A Case Study on Historical Maps
Oct 21, 2024



Historical maps provide valuable information and knowledge about the past. However, as they often feature non-standard projections, hand-drawn styles, and artistic elements, it is challenging for non-experts to identify and interpret them. While existing image captioning methods have achieved remarkable success on natural images, their performance on maps is suboptimal as maps are underrepresented in their pre-training process. Despite the recent advance of GPT-4 in text recognition and map captioning, it still has a limited understanding of maps, as its performance wanes when texts (e.g., titles and legends) in maps are missing or inaccurate. Besides, it is inefficient or even impractical to fine-tune the model with users' own datasets. To address these problems, we propose a novel and lightweight map-captioning counterpart. Specifically, we fine-tune the state-of-the-art vision-language model CLIP to generate captions relevant to historical maps and enrich the captions with GPT-3.5 to tell a brief story regarding where, what, when and why of a given map. We propose a novel decision tree architecture to only generate captions relevant to the specified map type. Our system shows invariance to text alterations in maps. The system can be easily adapted and extended to other map types and scaled to a larger map captioning system. The code is open-sourced at https://github.com/claudaff/automatic-map-storytelling.
A roadmap for generative mapping: unlocking the power of generative AI for map-making
Oct 21, 2024Maps are broadly relevant across various fields, serving as valuable tools for presenting spatial phenomena and communicating spatial knowledge. However, map-making is still largely confined to those with expertise in GIS and cartography due to the specialized software and complex workflow involved, from data processing to visualization. While generative AI has recently demonstrated its remarkable capability in creating various types of content and its wide accessibility to the general public, its potential in generating maps is yet to be fully realized. This paper highlights the key applications of generative AI in map-making, summarizes recent advancements in generative AI, identifies the specific technologies required and the challenges of using current methods, and provides a roadmap for developing a generative mapping system (GMS) to make map-making more accessible.
Probabilistic road classification in historical maps using synthetic data and deep learning
Oct 03, 2024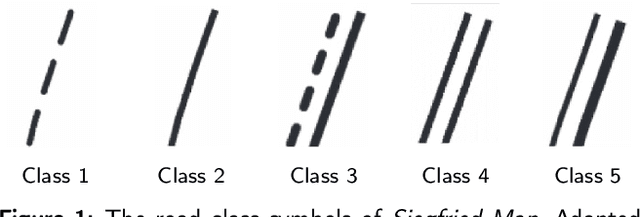

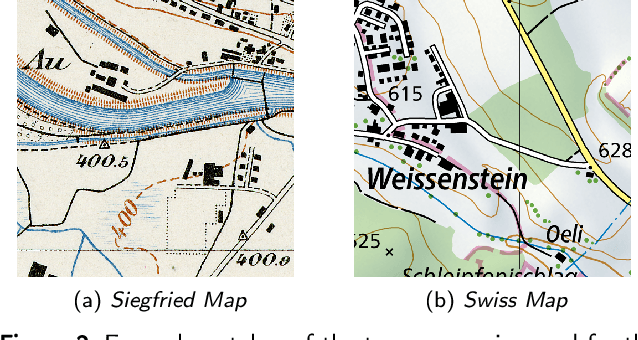

Historical maps are invaluable for analyzing long-term changes in transportation and spatial development, offering a rich source of data for evolutionary studies. However, digitizing and classifying road networks from these maps is often expensive and time-consuming, limiting their widespread use. Recent advancements in deep learning have made automatic road extraction from historical maps feasible, yet these methods typically require large amounts of labeled training data. To address this challenge, we introduce a novel framework that integrates deep learning with geoinformation, computer-based painting, and image processing methodologies. This framework enables the extraction and classification of roads from historical maps using only road geometries without needing road class labels for training. The process begins with training of a binary segmentation model to extract road geometries, followed by morphological operations, skeletonization, vectorization, and filtering algorithms. Synthetic training data is then generated by a painting function that artificially re-paints road segments using predefined symbology for road classes. Using this synthetic data, a deep ensemble is trained to generate pixel-wise probabilities for road classes to mitigate distribution shift. These predictions are then discretized along the extracted road geometries. Subsequently, further processing is employed to classify entire roads, enabling the identification of potential changes in road classes and resulting in a labeled road class dataset. Our method achieved completeness and correctness scores of over 94% and 92%, respectively, for road class 2, the most prevalent class in the two Siegfried Map sheets from Switzerland used for testing. This research offers a powerful tool for urban planning and transportation decision-making by efficiently extracting and classifying roads from historical maps.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024



Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
Cross-attention Spatio-temporal Context Transformer for Semantic Segmentation of Historical Maps
Oct 19, 2023



Historical maps provide useful spatio-temporal information on the Earth's surface before modern earth observation techniques came into being. To extract information from maps, neural networks, which gain wide popularity in recent years, have replaced hand-crafted map processing methods and tedious manual labor. However, aleatoric uncertainty, known as data-dependent uncertainty, inherent in the drawing/scanning/fading defects of the original map sheets and inadequate contexts when cropping maps into small tiles considering the memory limits of the training process, challenges the model to make correct predictions. As aleatoric uncertainty cannot be reduced even with more training data collected, we argue that complementary spatio-temporal contexts can be helpful. To achieve this, we propose a U-Net-based network that fuses spatio-temporal features with cross-attention transformers (U-SpaTem), aggregating information at a larger spatial range as well as through a temporal sequence of images. Our model achieves a better performance than other state-or-art models that use either temporal or spatial contexts. Compared with pure vision transformers, our model is more lightweight and effective. To the best of our knowledge, leveraging both spatial and temporal contexts have been rarely explored before in the segmentation task. Even though our application is on segmenting historical maps, we believe that the method can be transferred into other fields with similar problems like temporal sequences of satellite images. Our code is freely accessible at https://github.com/chenyizi086/wu.2023.sigspatial.git.