 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAESTRO: Masked AutoEncoders for Multimodal, Multitemporal, and Multispectral Earth Observation Data
Aug 14, 2025Self-supervised learning holds great promise for remote sensing, but standard self-supervised methods must be adapted to the unique characteristics of Earth observation data. We take a step in this direction by conducting a comprehensive benchmark of fusion strategies and reconstruction target normalization schemes for multimodal, multitemporal, and multispectral Earth observation data. Based on our findings, we propose MAESTRO, a novel adaptation of the Masked Autoencoder, featuring optimized fusion strategies and a tailored target normalization scheme that introduces a spectral prior as a self-supervisory signal. Evaluated on four Earth observation datasets, MAESTRO sets a new state-of-the-art on tasks that strongly rely on multitemporal dynamics, while remaining highly competitive on tasks dominated by a single mono-temporal modality. Code to reproduce all our experiments is available at https://github.com/ignf/maestro.
FLAIR-HUB: Large-scale Multimodal Dataset for Land Cover and Crop Mapping
Jun 08, 2025The growing availability of high-quality Earth Observation (EO) data enables accurate global land cover and crop type monitoring. However, the volume and heterogeneity of these datasets pose major processing and annotation challenges. To address this, the French National Institute of Geographical and Forest Information (IGN) is actively exploring innovative strategies to exploit diverse EO data, which require large annotated datasets. IGN introduces FLAIR-HUB, the largest multi-sensor land cover dataset with very-high-resolution (20 cm) annotations, covering 2528 km2 of France. It combines six aligned modalities: aerial imagery, Sentinel-1/2 time series, SPOT imagery, topographic data, and historical aerial images. Extensive benchmarks evaluate multimodal fusion and deep learning models (CNNs, transformers) for land cover or crop mapping and also explore multi-task learning. Results underscore the complexity of multimodal fusion and fine-grained classification, with best land cover performance (78.2% accuracy, 65.8% mIoU) achieved using nearly all modalities. FLAIR-HUB supports supervised and multimodal pretraining, with data and code available at https://ignf.github.io/FLAIR/flairhub.
Operational Change Detection for Geographical Information: Overview and Challenges
Mar 18, 2025Rapid evolution of territories due to climate change and human impact requires prompt and effective updates to geospatial databases maintained by the National Mapping Agency. This paper presents a comprehensive overview of change detection methods tailored for the operational updating of large-scale geographic databases. This review first outlines the fundamental definition of change, emphasizing its multifaceted nature, from temporal to semantic characterization. It categorizes automatic change detection methods into four main families: rule-based, statistical, machine learning, and simulation methods. The strengths, limitations, and applicability of every family are discussed in the context of various input data. Then, key applications for National Mapping Agencies are identified, particularly the optimization of geospatial database updating, change-based phenomena, and dynamics monitoring. Finally, the paper highlights the current challenges for leveraging change detection such as the variability of change definition, the missing of relevant large-scale datasets, the diversity of input data, the unstudied no-change detection, the human in the loop integration and the operational constraints. The discussion underscores the necessity for ongoing innovation in change detection techniques to address the future needs of geographic information systems for national mapping agencies.
AnySat: An Earth Observation Model for Any Resolutions, Scales, and Modalities
Dec 18, 2024



Geospatial models must adapt to the diversity of Earth observation data in terms of resolutions, scales, and modalities. However, existing approaches expect fixed input configurations, which limits their practical applicability. We propose AnySat, a multimodal model based on joint embedding predictive architecture (JEPA) and resolution-adaptive spatial encoders, allowing us to train a single model on highly heterogeneous data in a self-supervised manner. To demonstrate the advantages of this unified approach, we compile GeoPlex, a collection of $5$ multimodal datasets with varying characteristics and $11$ distinct sensors. We then train a single powerful model on these diverse datasets simultaneously. Once fine-tuned, we achieve better or near state-of-the-art results on the datasets of GeoPlex and $4$ additional ones for $5$ environment monitoring tasks: land cover mapping, tree species identification, crop type classification, change detection, and flood segmentation. The code and models are available at https://github.com/gastruc/AnySat.
No Annotations for Object Detection in Art through Stable Diffusion
Dec 09, 2024



Object detection in art is a valuable tool for the digital humanities, as it allows for faster identification of objects in artistic and historical images compared to humans. However, annotating such images poses significant challenges due to the need for specialized domain expertise. We present NADA (no annotations for detection in art), a pipeline that leverages diffusion models' art-related knowledge for object detection in paintings without the need for full bounding box supervision. Our method, which supports both weakly-supervised and zero-shot scenarios and does not require any fine-tuning of its pretrained components, consists of a class proposer based on large vision-language models and a class-conditioned detector based on Stable Diffusion. NADA is evaluated on two artwork datasets, ArtDL 2.0 and IconArt, outperforming prior work in weakly-supervised detection, while being the first work for zero-shot object detection in art. Code is available at https://github.com/patrick-john-ramos/nada
OmniSat: Self-Supervised Modality Fusion for Earth Observation
Apr 12, 2024



The field of Earth Observations (EO) offers a wealth of data from diverse sensors, presenting a great opportunity for advancing self-supervised multimodal learning. However, current multimodal EO datasets and models focus on a single data type, either mono-date images or time series, which limits their expressivity. We introduce OmniSat, a novel architecture that exploits the spatial alignment between multiple EO modalities to learn expressive multimodal representations without labels. To demonstrate the advantages of combining modalities of different natures, we augment two existing datasets with new modalities. As demonstrated on three downstream tasks: forestry, land cover classification, and crop mapping. OmniSat can learn rich representations in an unsupervised manner, leading to improved performance in the semi- and fully-supervised settings, even when only one modality is available for inference. The code and dataset are available at github.com/gastruc/OmniSat.
StegoGAN: Leveraging Steganography for Non-Bijective Image-to-Image Translation
Mar 29, 2024



Most image-to-image translation models postulate that a unique correspondence exists between the semantic classes of the source and target domains. However, this assumption does not always hold in real-world scenarios due to divergent distributions, different class sets, and asymmetrical information representation. As conventional GANs attempt to generate images that match the distribution of the target domain, they may hallucinate spurious instances of classes absent from the source domain, thereby diminishing the usefulness and reliability of translated images. CycleGAN-based methods are also known to hide the mismatched information in the generated images to bypass cycle consistency objectives, a process known as steganography. In response to the challenge of non-bijective image translation, we introduce StegoGAN, a novel model that leverages steganography to prevent spurious features in generated images. Our approach enhances the semantic consistency of the translated images without requiring additional postprocessing or supervision. Our experimental evaluations demonstrate that StegoGAN outperforms existing GAN-based models across various non-bijective image-to-image translation tasks, both qualitatively and quantitatively. Our code and pretrained models are accessible at https://github.com/sian-wusidi/StegoGAN.
FLAIR: a Country-Scale Land Cover Semantic Segmentation Dataset From Multi-Source Optical Imagery
Oct 20, 2023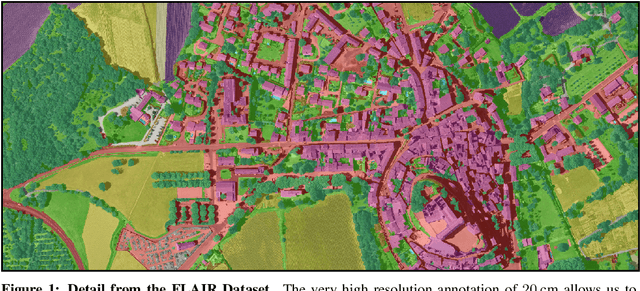
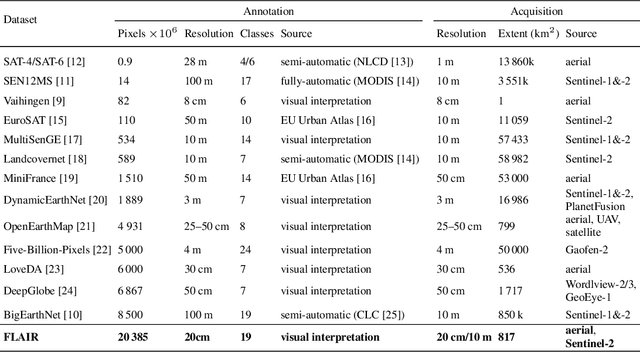

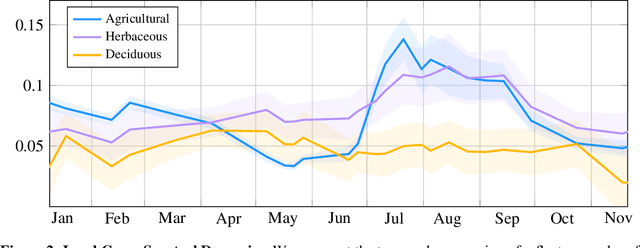
We introduce the French Land cover from Aerospace ImageRy (FLAIR), an extensive dataset from the French National Institute of Geographical and Forest Information (IGN) that provides a unique and rich resource for large-scale geospatial analysis. FLAIR contains high-resolution aerial imagery with a ground sample distance of 20 cm and over 20 billion individually labeled pixels for precise land-cover classification. The dataset also integrates temporal and spectral data from optical satellite time series. FLAIR thus combines data with varying spatial, spectral, and temporal resolutions across over 817 km2 of acquisitions representing the full landscape diversity of France. This diversity makes FLAIR a valuable resource for the development and evaluation of novel methods for large-scale land-cover semantic segmentation and raises significant challenges in terms of computer vision, data fusion, and geospatial analysis. We also provide powerful uni- and multi-sensor baseline models that can be employed to assess algorithm's performance and for downstream applications. Through its extent and the quality of its annotation, FLAIR aims to spur improvements in monitoring and understanding key anthropogenic development indicators such as urban growth, deforestation, and soil artificialization. Dataset and codes can be accessed at https://ignf.github.io/FLAIR/
GeoMultiTaskNet: remote sensing unsupervised domain adaptation using geographical coordinates
Apr 16, 2023Land cover maps are a pivotal element in a wide range of Earth Observation (EO) applications. However, annotating large datasets to develop supervised systems for remote sensing (RS) semantic segmentation is costly and time-consuming. Unsupervised Domain Adaption (UDA) could tackle these issues by adapting a model trained on a source domain, where labels are available, to a target domain, without annotations. UDA, while gaining importance in computer vision, is still under-investigated in RS. Thus, we propose a new lightweight model, GeoMultiTaskNet, based on two contributions: a GeoMultiTask module (GeoMT), which utilizes geographical coordinates to align the source and target domains, and a Dynamic Class Sampling (DCS) strategy, to adapt the semantic segmentation loss to the frequency of classes. This approach is the first to use geographical metadata for UDA in semantic segmentation. It reaches state-of-the-art performances (47,22% mIoU), reducing at the same time the number of parameters (33M), on a subset of the FLAIR dataset, a recently proposed dataset properly shaped for RS UDA, used for the first time ever for research scopes here.
The Learnable Typewriter: A Generative Approach to Text Line Analysis
Feb 06, 2023We present a generative document-specific approach to character analysis and recognition in text lines. Our main idea is to build on unsupervised multi-object segmentation methods and in particular those that reconstruct images based on a limited amount of visual elements, called sprites. Our approach can learn a large number of different characters and leverage line-level annotations when available. Our contribution is twofold. First, we provide the first adaptation and evaluation of a deep unsupervised multi-object segmentation approach for text line analysis. Since these methods have mainly been evaluated on synthetic data in a completely unsupervised setting, demonstrating that they can be adapted and quantitatively evaluated on real text images and that they can be trained using weak supervision are significant progresses. Second, we demonstrate the potential of our method for new applications, more specifically in the field of paleography, which studies the history and variations of handwriting, and for cipher analysis. We evaluate our approach on three very different datasets: a printed volume of the Google1000 dataset, the Copiale cipher and historical handwritten charters from the 12th and early 13th century.